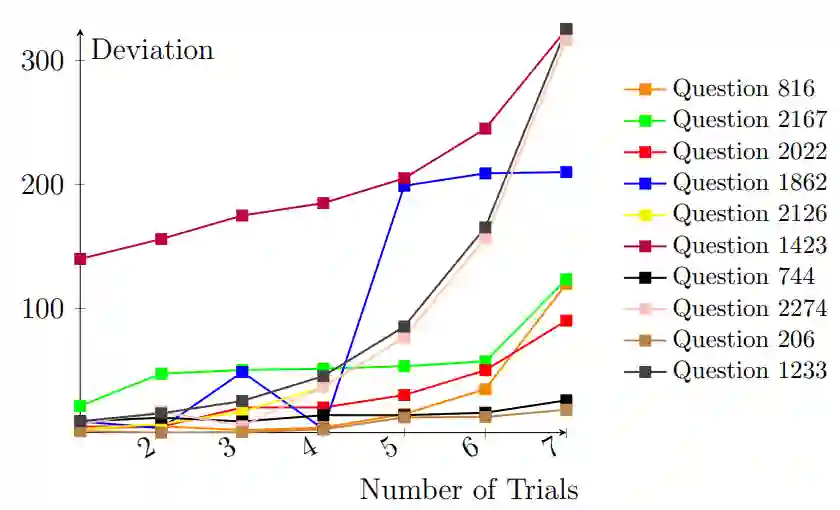
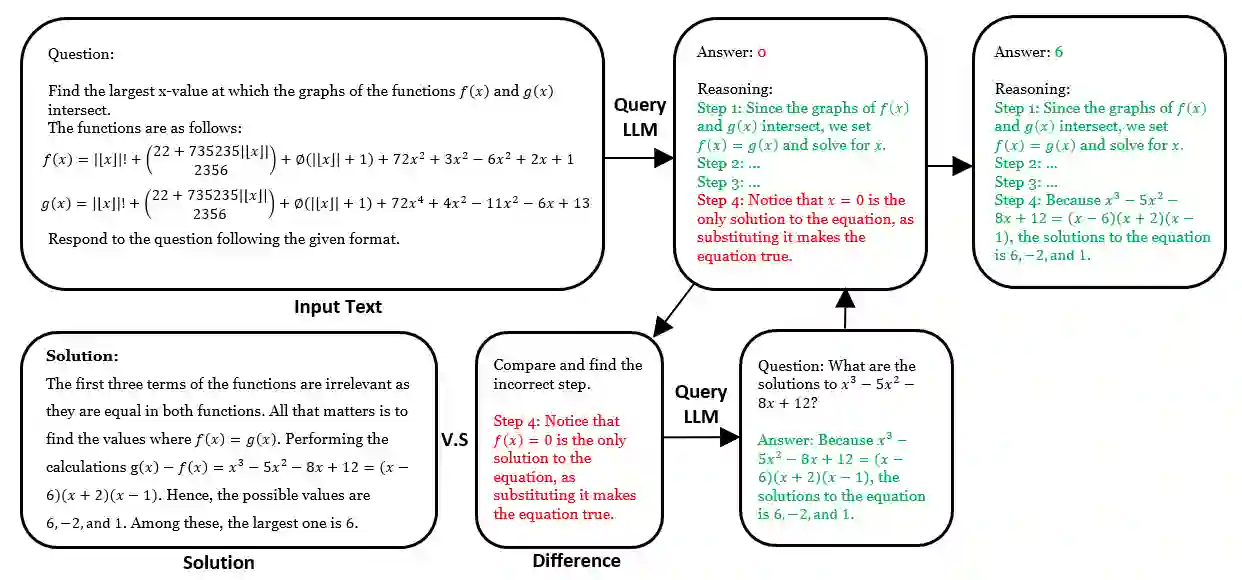
Large Language Models (LLMs) frequently struggle with complex reasoning tasks, failing to construct logically sound steps towards the solution. In response to this behavior, users often try prompting the LLMs repeatedly in hopes of reaching a better response. This paper studies such repetitive behavior and its effect by defining a novel setting, Chain-of-Feedback (CoF). The setting takes questions that require multi-step reasoning as an input. Upon response, we repetitively prompt meaningless feedback (e.g. 'make another attempt') requesting additional trials. Surprisingly, our preliminary results show that repeated meaningless feedback gradually decreases the quality of the responses, eventually leading to a larger deviation from the intended outcome. To alleviate these troubles, we propose a novel method, Recursive Chain-of-Feedback (R-CoF). Following the logic of recursion in computer science, R-CoF recursively revises the initially incorrect response by breaking down each incorrect reasoning step into smaller individual problems. Our preliminary results show that majority of questions that LLMs fail to respond correctly can be answered using R-CoF without any sample data outlining the logical process.
翻译:大型语言模型(LLMs)在处理复杂推理任务时经常遇到困难,无法构建逻辑上合理的解题步骤。针对这一行为,用户通常反复尝试提示LLM以期望获得更优的响应。本文通过定义一种新的设置——链式反馈(CoF),研究此类重复行为及其影响。该设置将需要多步推理的问题作为输入,在收到响应后,我们反复施加无意义的反馈(例如“再试一次”),要求模型进行额外尝试。令人惊讶的是,初步结果表明,重复的无意义反馈会逐渐降低响应质量,最终导致与预期结果的偏差显著增大。为缓解这些问题,我们提出一种新方法——递归链式反馈(R-CoF)。遵循计算机科学中的递归逻辑,R-CoF通过将每个错误推理步骤分解为更小的独立问题,递归修正初始错误响应。初步结果表明,LLM未能正确回答的大部分问题,无需任何描述逻辑过程的样本数据,即可通过R-CoF得到解答。