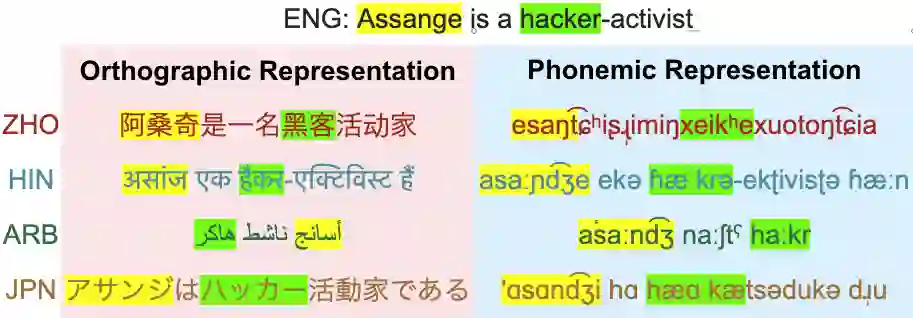
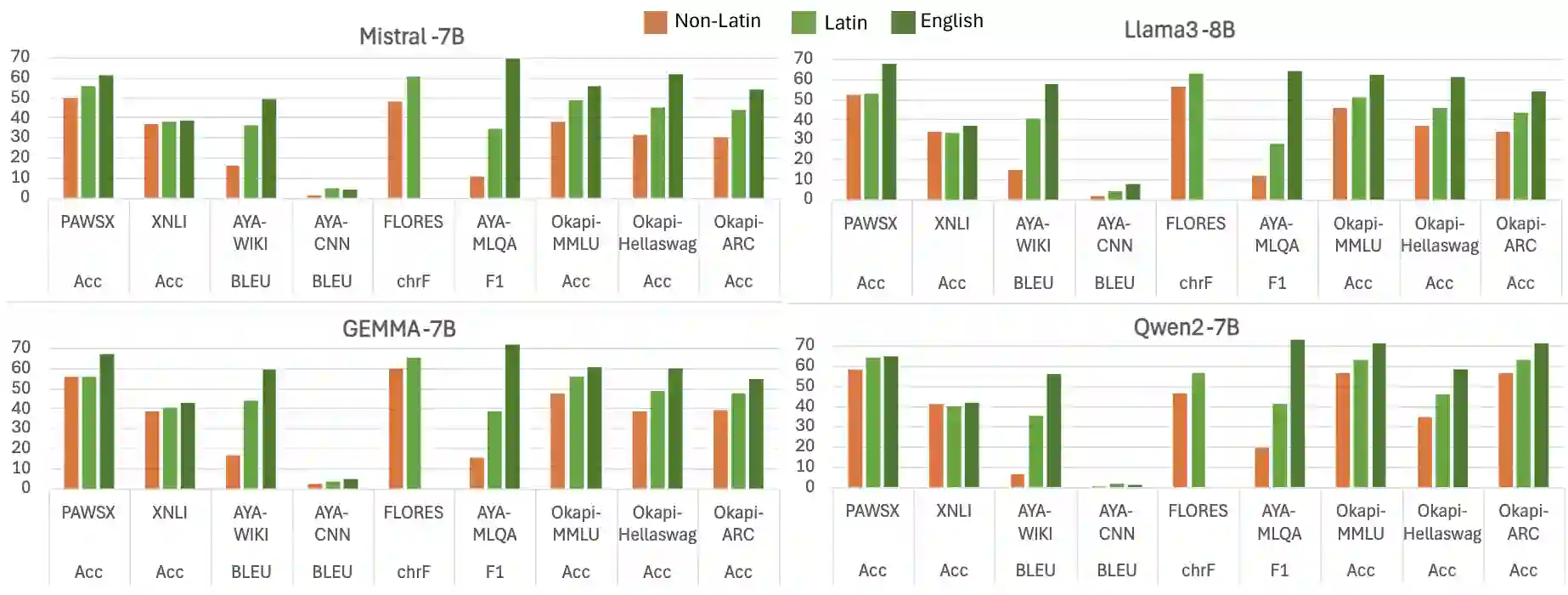
Multilingual LLMs have achieved remarkable benchmark performance, but we find they continue to underperform on non-Latin script languages across contemporary LLM families. This discrepancy arises from the fact that LLMs are pretrained with orthographic scripts, which are dominated by Latin characters that obscure their shared phonology with non-Latin scripts. We propose leveraging phonemic transcriptions as complementary signals to induce script-invariant representations. Our study demonstrates that integrating phonemic signals improves performance across both non-Latin and Latin languages, with a particularly significant impact on closing the performance gap between the two. Through detailed experiments, we show that phonemic and orthographic scripts retrieve distinct examples for in-context learning (ICL). This motivates our proposed Mixed-ICL retrieval strategy, where further aggregation leads to our significant performance improvements for both Latin script languages (up to 12.6%) and non-Latin script languages (up to 15.1%) compared to randomized ICL retrieval.
翻译:多语言大语言模型在基准测试中取得了显著性能,但我们发现其在当代大语言模型系列中对非拉丁文字语言的表现仍然欠佳。这种差异源于大语言模型是基于正字法文字进行预训练的,而这些文字以拉丁字符为主导,掩盖了其与非拉丁文字共享的音系学特征。我们提出利用音位转写作为补充信号,以诱导出文字不变的表征。我们的研究表明,整合音位信号能同时提升对非拉丁文字语言和拉丁文字语言的性能,并且在缩小两者之间的性能差距方面效果尤为显著。通过详细的实验,我们证明音位转写与正字法文字在上下文学习(ICL)中检索到不同的示例。这启发了我们提出的混合ICL检索策略,该策略通过进一步聚合,与随机ICL检索相比,为拉丁文字语言(最高提升12.6%)和非拉丁文字语言(最高提升15.1%)均带来了显著的性能提升。