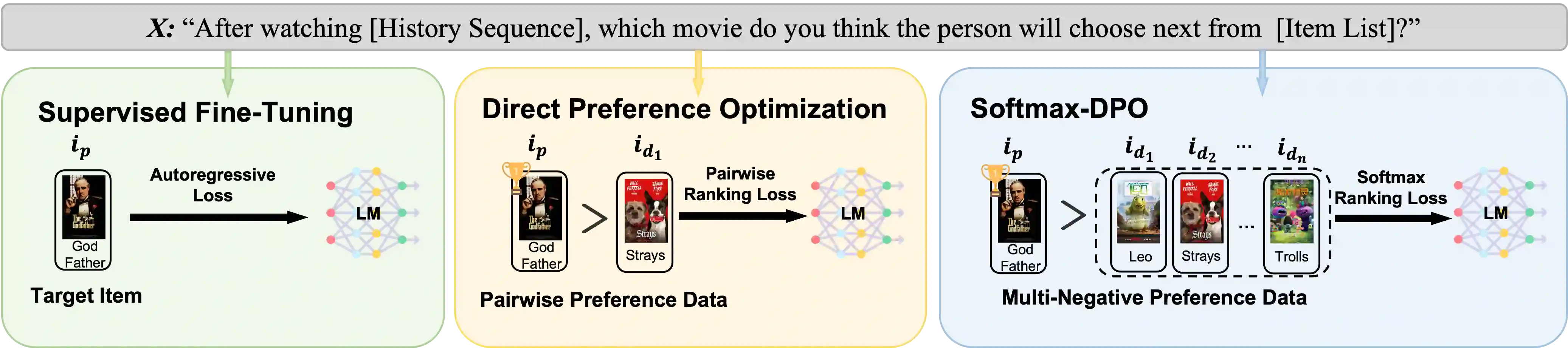
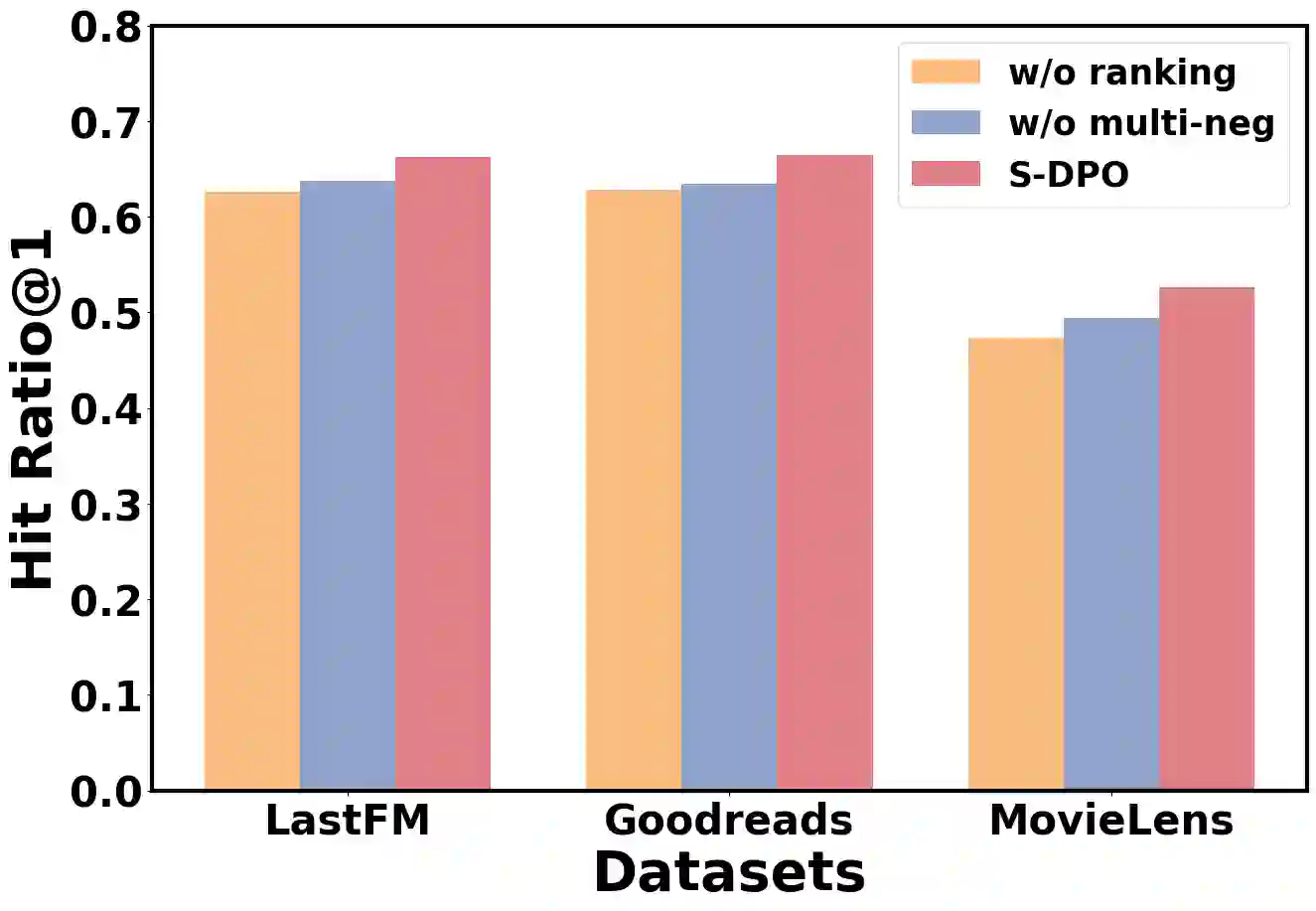
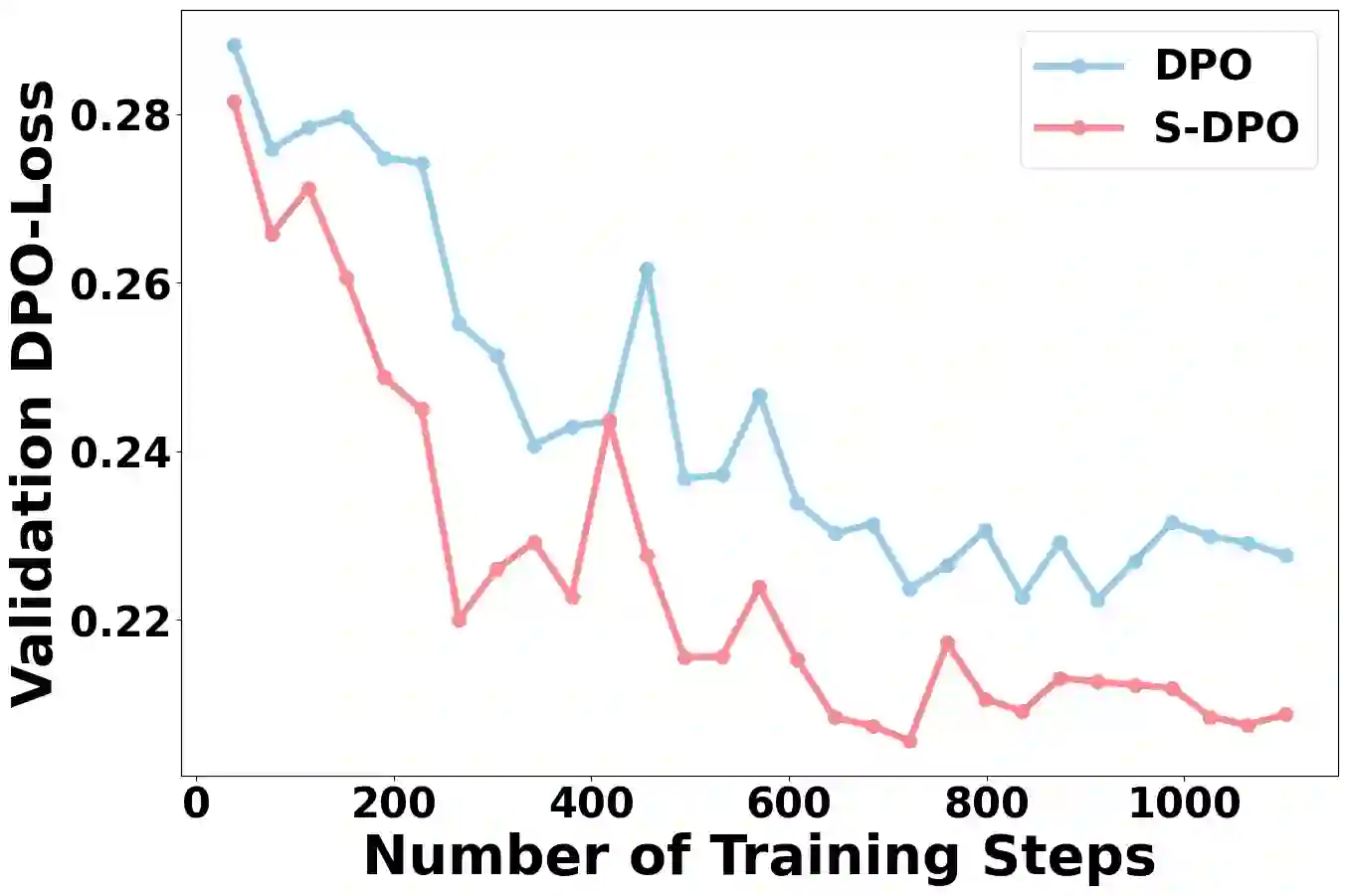
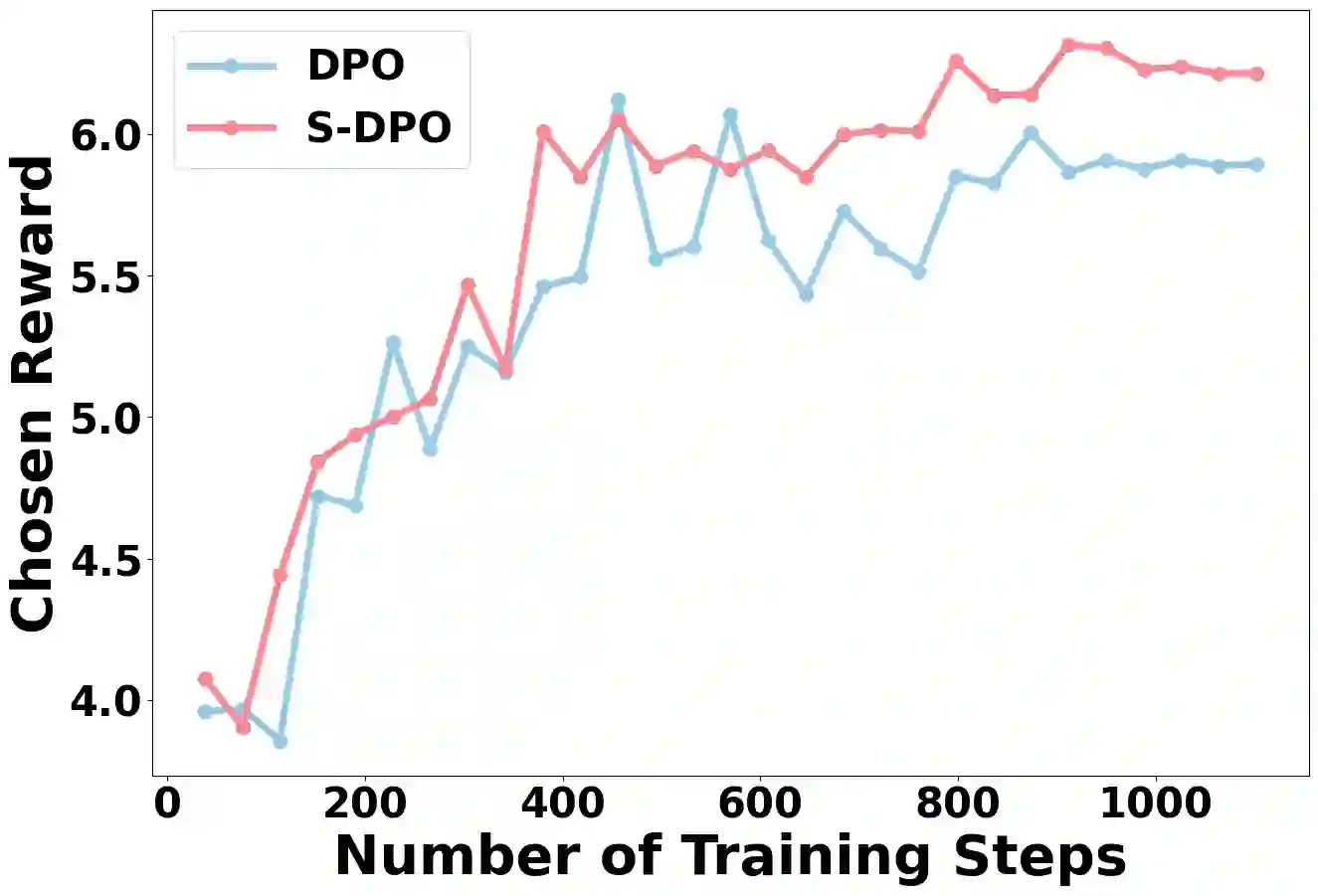
Recommender systems aim to predict personalized rankings based on user preference data. With the rise of Language Models (LMs), LM-based recommenders have been widely explored due to their extensive world knowledge and powerful reasoning abilities. Most of the LM-based recommenders convert historical interactions into language prompts, pairing with a positive item as the target response and fine-tuning LM with a language modeling loss. However, the current objective fails to fully leverage preference data and is not optimized for personalized ranking tasks, which hinders the performance of LM-based recommenders. Inspired by the current advancement of Direct Preference Optimization (DPO) in human preference alignment and the success of softmax loss in recommendations, we propose Softmax-DPO (S-DPO) to instill ranking information into the LM to help LM-based recommenders distinguish preferred items from negatives, rather than solely focusing on positives. Specifically, we incorporate multiple negatives in user preference data and devise an alternative version of DPO loss tailored for LM-based recommenders, which is extended from the traditional full-ranking Plackett-Luce (PL) model to partial rankings and connected to softmax sampling strategies. Theoretically, we bridge S-DPO with the softmax loss over negative sampling and find that it has an inherent benefit of mining hard negatives, which assures its exceptional capabilities in recommendation tasks. Empirically, extensive experiments conducted on three real-world datasets demonstrate the superiority of S-DPO to effectively model user preference and further boost recommendation performance while providing better rewards for preferred items. Our codes are available at https://github.com/chenyuxin1999/S-DPO.
翻译:推荐系统旨在基于用户偏好数据预测个性化排序。随着语言模型(LMs)的兴起,基于语言模型的推荐系统因其广泛的世界知识和强大的推理能力而被广泛探索。大多数基于语言模型的推荐系统将历史交互转化为语言提示,并将正样本项目作为目标响应,通过语言建模损失对语言模型进行微调。然而,当前的目标函数未能充分利用偏好数据,且未针对个性化排序任务进行优化,这限制了基于语言模型的推荐系统的性能。受直接偏好优化(DPO)在人类偏好对齐方面的最新进展以及softmax损失在推荐系统中成功应用的启发,我们提出Softmax-DPO(S-DPO),旨在将排序信息注入语言模型,以帮助基于语言模型的推荐系统区分偏好项目与负样本,而非仅关注正样本。具体而言,我们在用户偏好数据中引入多个负样本,并设计了一种专为基于语言模型的推荐系统定制的DPO损失函数变体,该变体从传统的全排序Plackett-Luce(PL)模型扩展至部分排序,并与softmax采样策略相关联。理论上,我们将S-DPO与基于负采样的softmax损失联系起来,发现其具有挖掘困难负样本的内在优势,这确保了其在推荐任务中的卓越能力。实证方面,在三个真实世界数据集上进行的大量实验表明,S-DPO在有效建模用户偏好、进一步提升推荐性能的同时,能为偏好项目提供更好的奖励。我们的代码公开于https://github.com/chenyuxin1999/S-DPO。