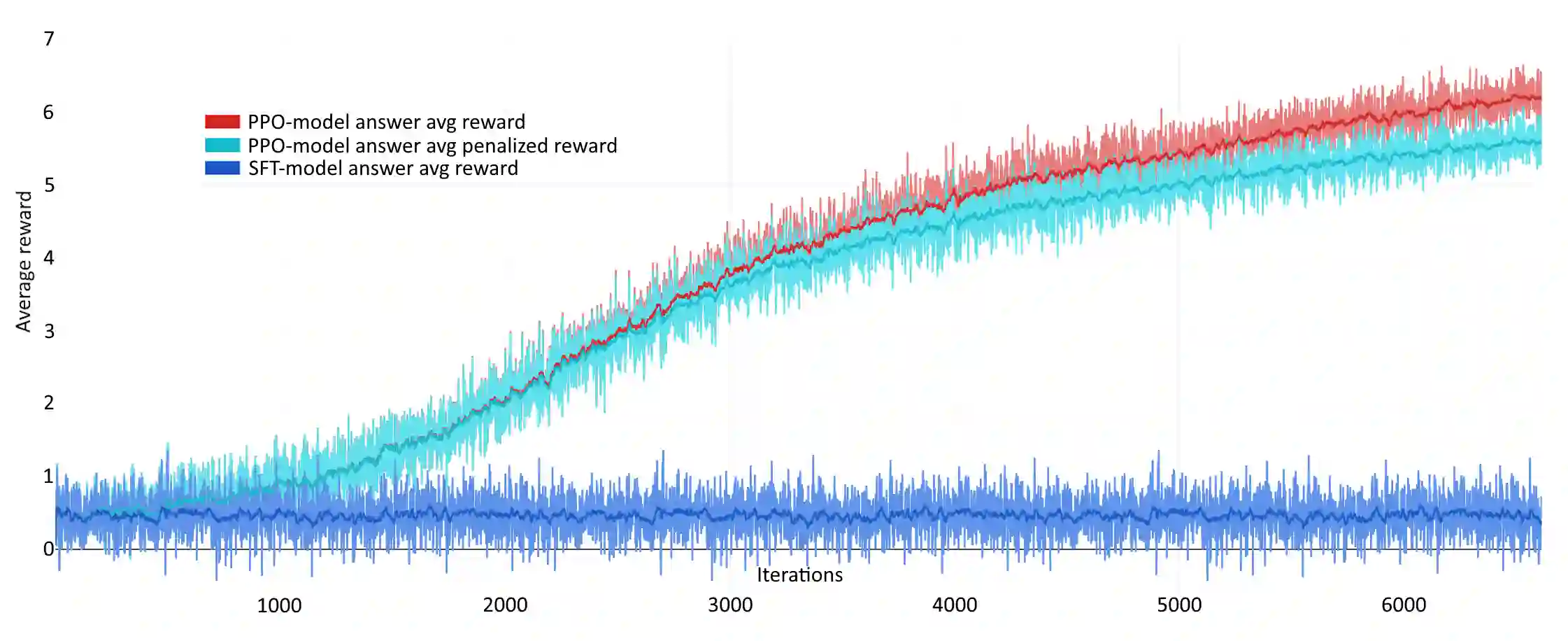
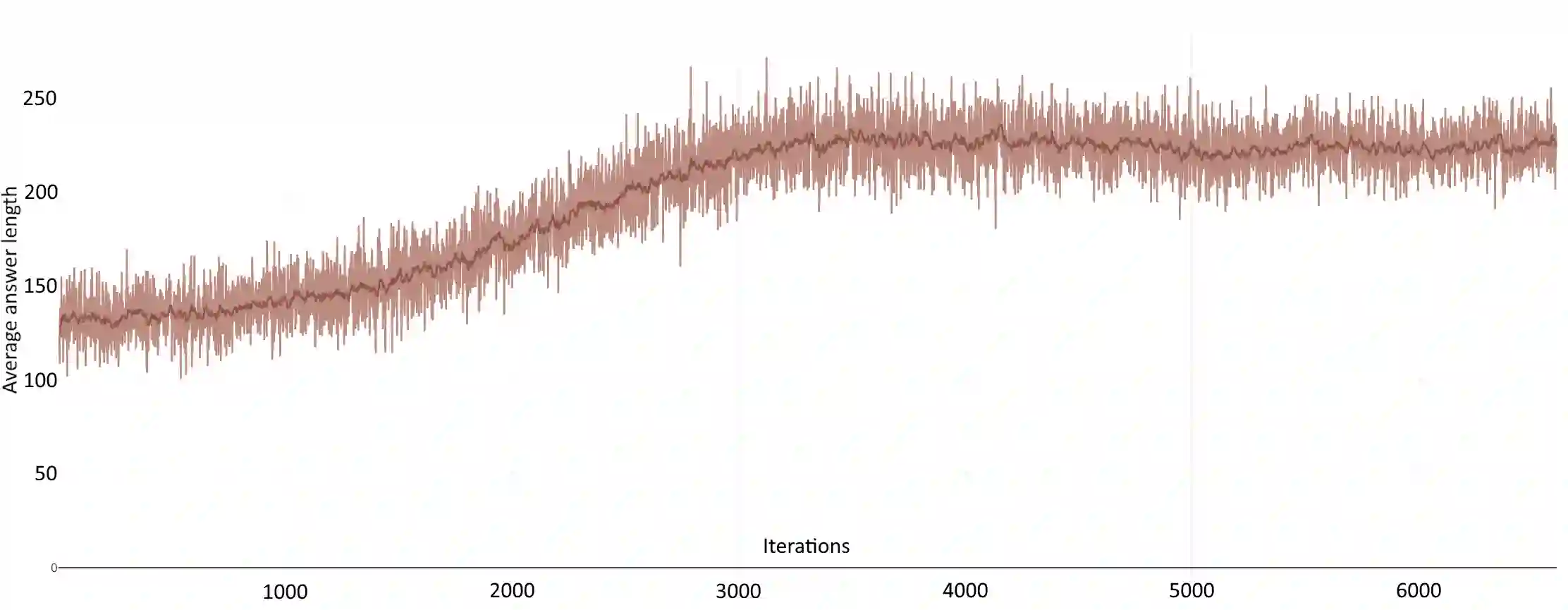
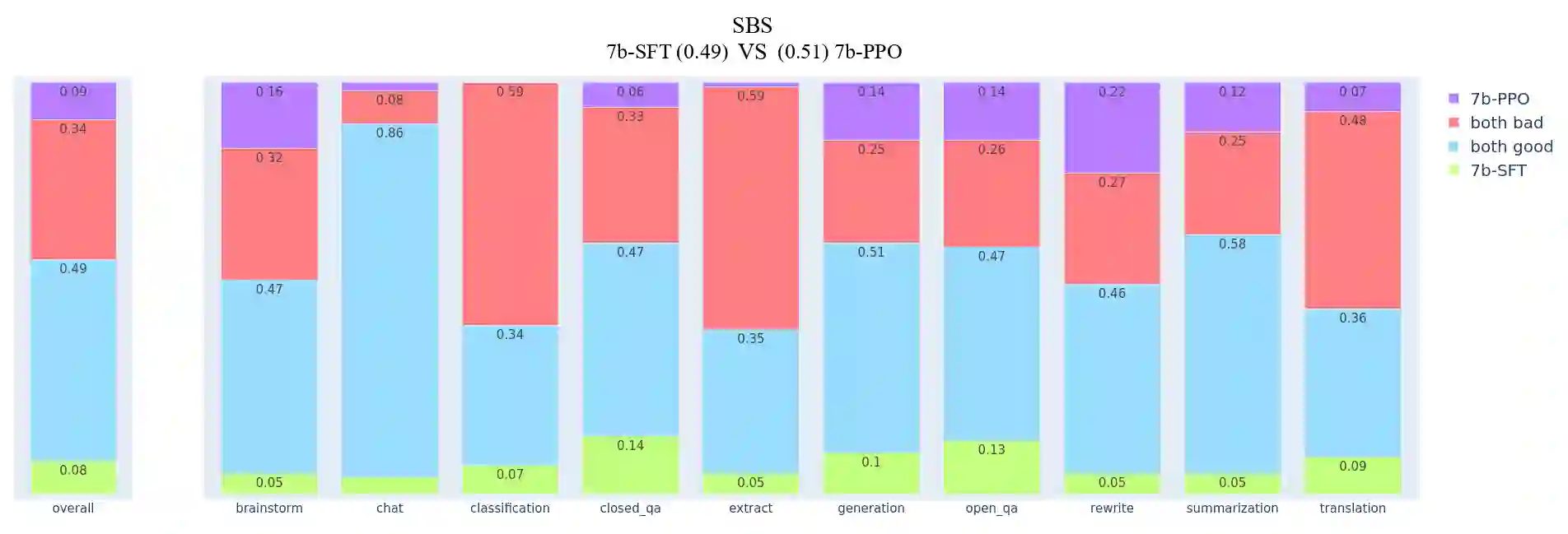
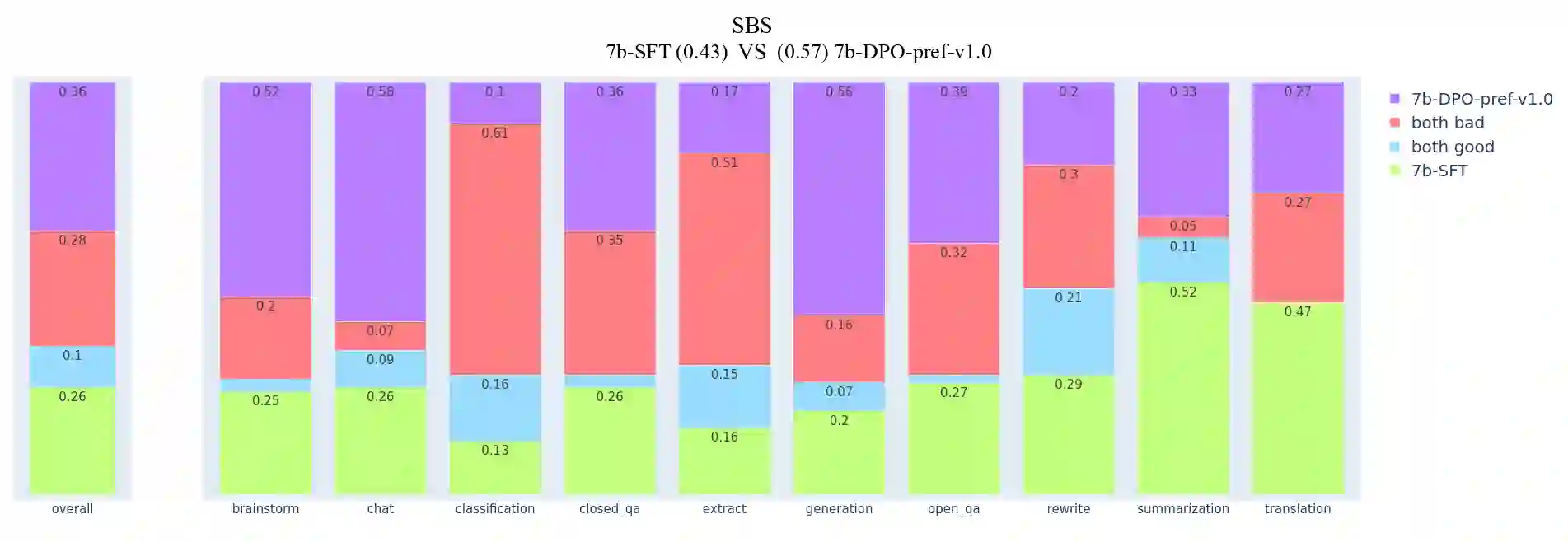
In this article, we investigate the alignment of Large Language Models according to human preferences. We discuss the features of training a Preference Model, which simulates human preferences, and the methods and details we found essential for achieving the best results. We also discuss using Reinforcement Learning to fine-tune Large Language Models and describe the challenges we faced and the ways to overcome them. Additionally, we present our experience with the Direct Preference Optimization method, which enables us to align a Large Language Model with human preferences without creating a separate Preference Model. As our contribution, we introduce the approach for collecting a preference dataset through perplexity filtering, which makes the process of creating such a dataset for a specific Language Model much easier and more cost-effective.
翻译:本文研究了大型语言模型与人类偏好的对齐问题。我们探讨了训练偏好模型(用于模拟人类偏好)的特点,以及实现最佳效果所需的关键方法与细节。同时,我们讨论了使用强化学习对大型语言模型进行微调的方法,阐述了所面临的挑战及其解决方案。此外,我们分享了直接偏好优化方法的实践经验,该方法无需构建独立的偏好模型即可实现大型语言模型与人类偏好的对齐。作为本研究的贡献,我们提出了一种通过困惑度过滤收集偏好数据的方法,该方法显著简化了针对特定语言模型构建偏好数据集的流程,并大幅降低了成本。