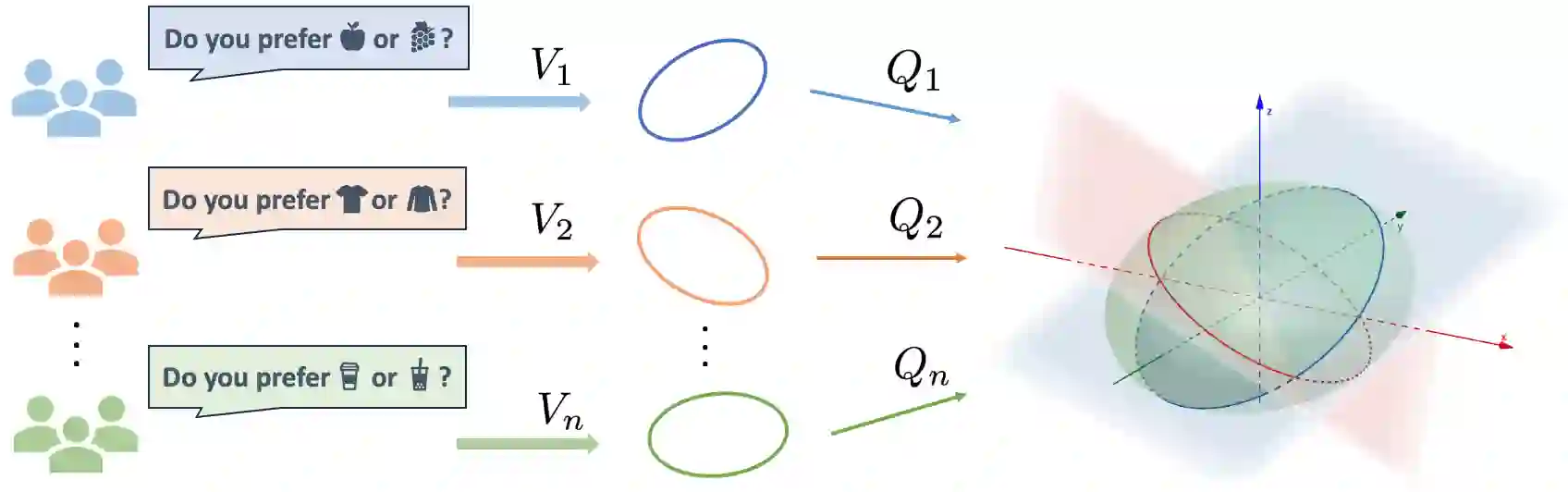
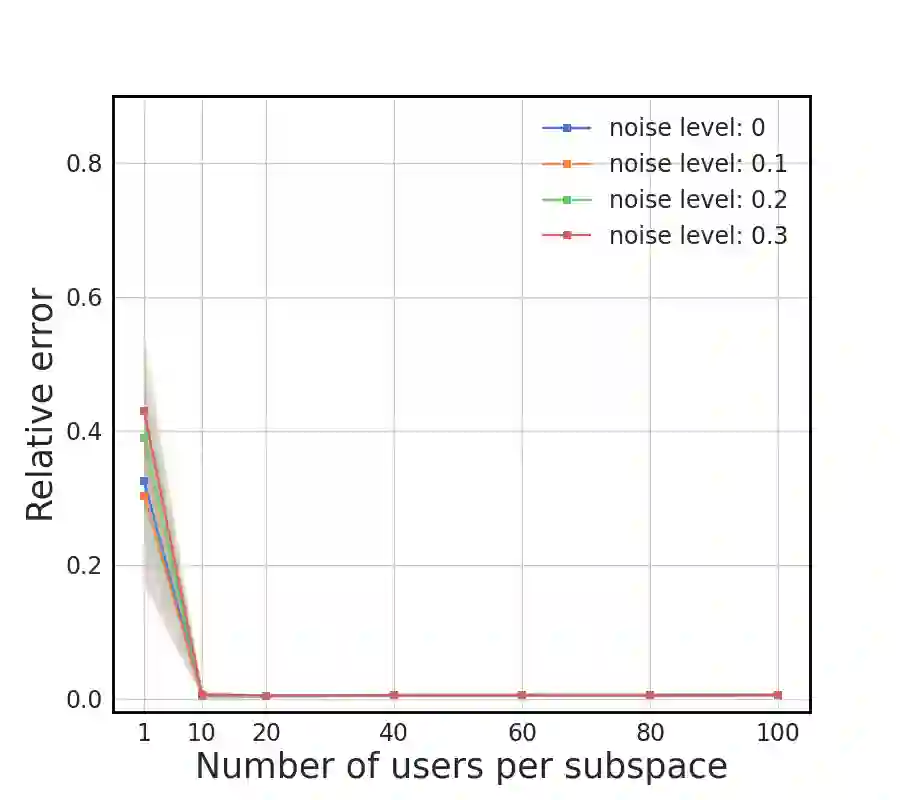
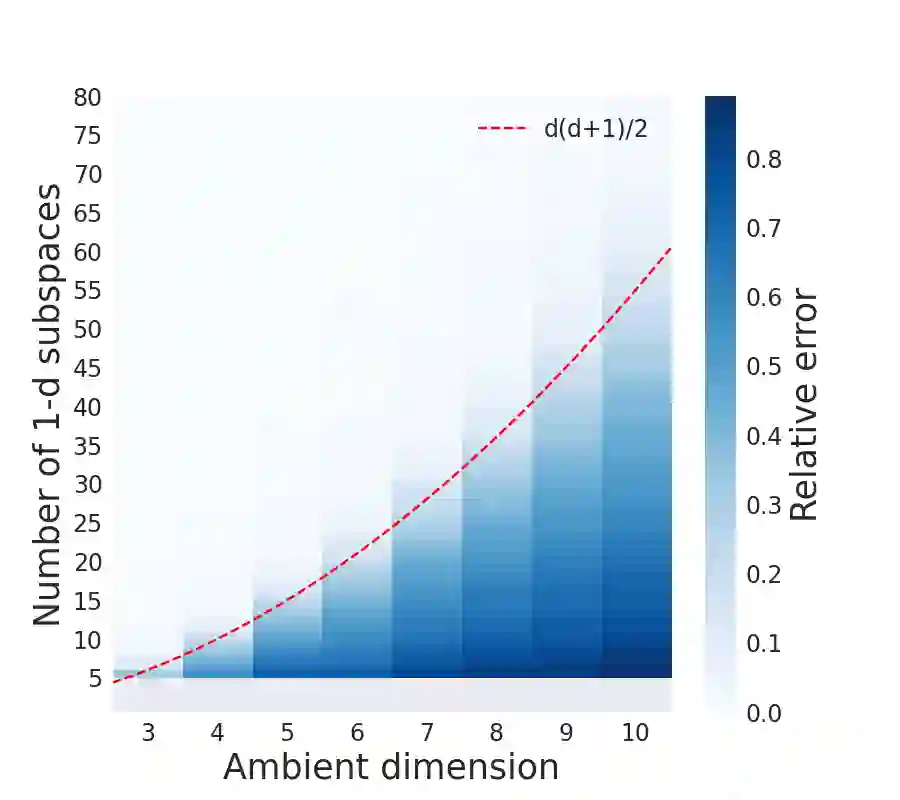
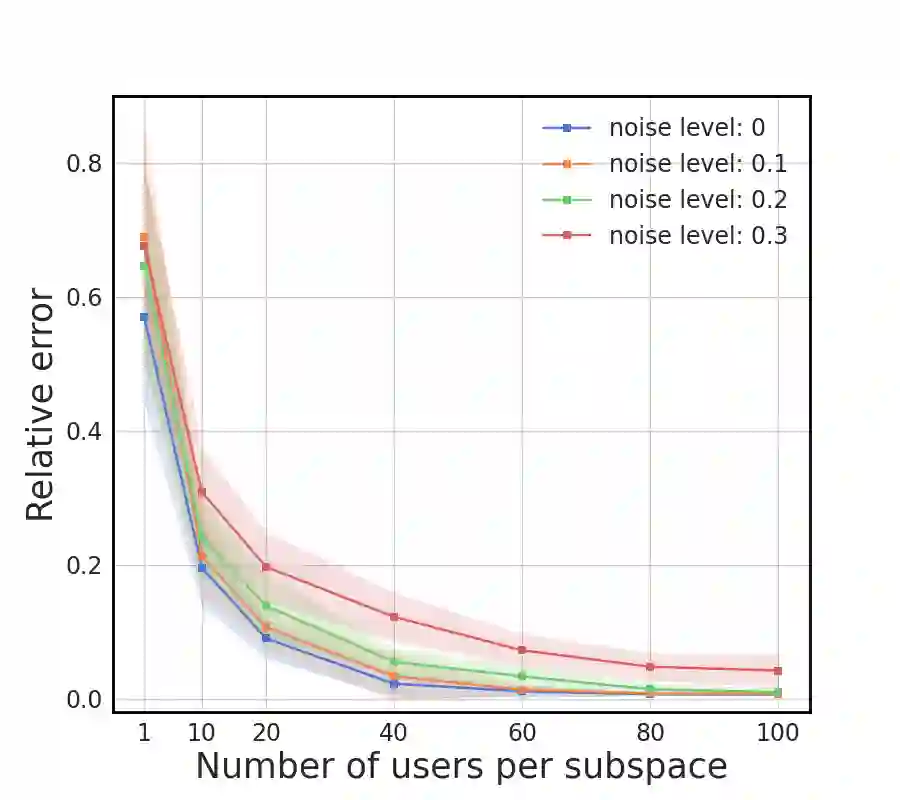
We study metric learning from preference comparisons under the ideal point model, in which a user prefers an item over another if it is closer to their latent ideal item. These items are embedded into $\mathbb{R}^d$ equipped with an unknown Mahalanobis distance shared across users. While recent work shows that it is possible to simultaneously recover the metric and ideal items given $\mathcal{O}(d)$ pairwise comparisons per user, in practice we often have a limited budget of $o(d)$ comparisons. We study whether the metric can still be recovered, even though it is known that learning individual ideal items is now no longer possible. We show that in general, $o(d)$ comparisons reveal no information about the metric, even with infinitely many users. However, when comparisons are made over items that exhibit low-dimensional structure, each user can contribute to learning the metric restricted to a low-dimensional subspace so that the metric can be jointly identified. We present a divide-and-conquer approach that achieves this, and provide theoretical recovery guarantees and empirical validation.
翻译:我们研究在理想点模型下从偏好比较中学习度量的问题,该模型假设当物品与用户潜在的理想物品更接近时,用户会更偏好该物品。这些物品被嵌入到配备未知马氏距离的 $\mathbb{R}^d$ 空间中,该距离在所有用户间共享。尽管近期研究表明,在每位用户提供 $\mathcal{O}(d)$ 组成对比较的情况下,可以同时恢复度量与理想物品,但在实际应用中我们通常仅有 $o(d)$ 次比较的有限预算。我们探讨在此限制下是否仍能恢复度量——尽管已知此时已无法学习个体的理想物品。我们证明,在一般情况下,即使存在无限多用户,$o(d)$ 次比较也无法提供关于度量的任何信息。然而,当比较所涉及的物品呈现低维结构时,每位用户可对学习限制在低维子空间上的度量作出贡献,从而能够联合识别该度量。我们提出一种实现此目标的"分而治之"方法,并提供了理论恢复保证与实证验证。