
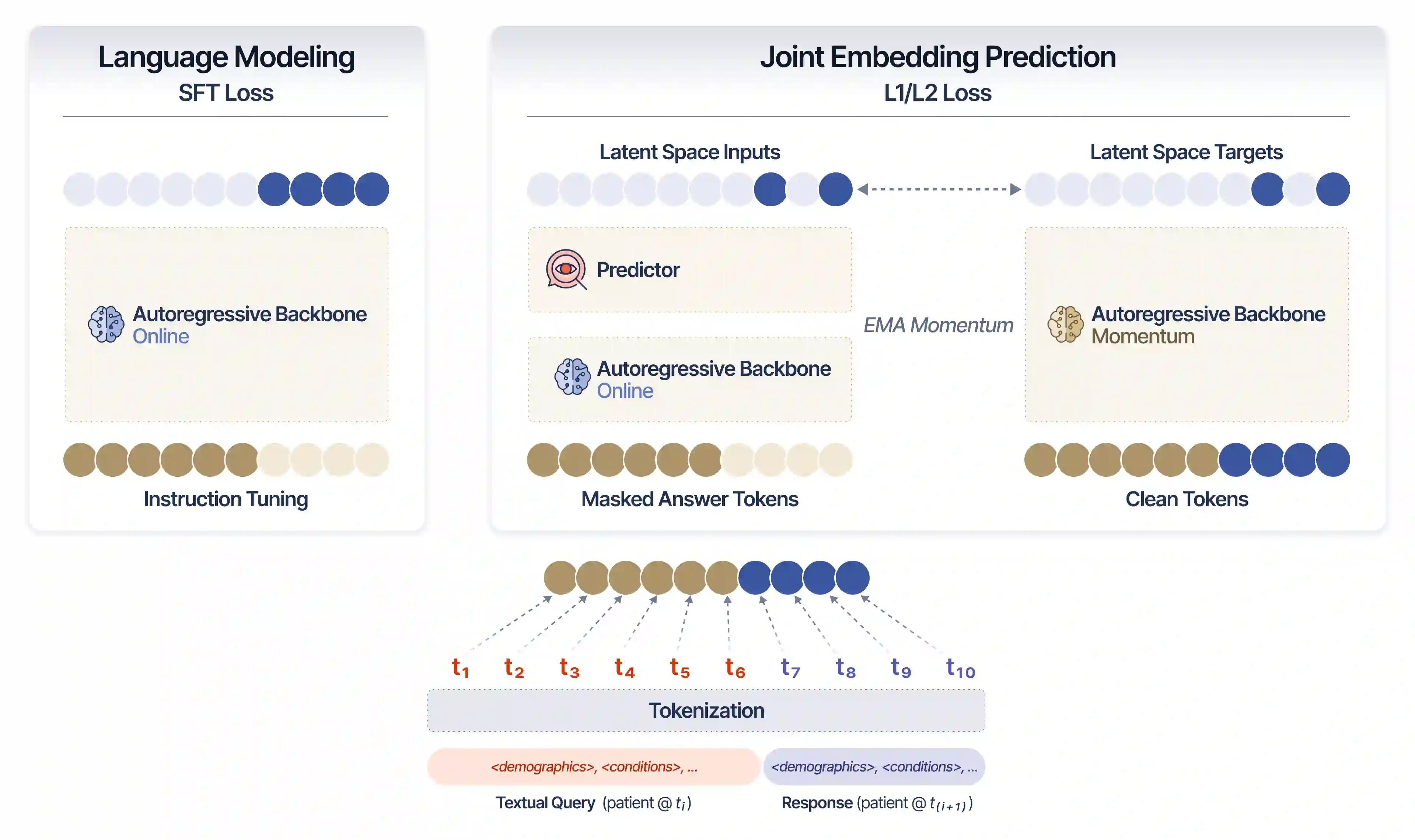
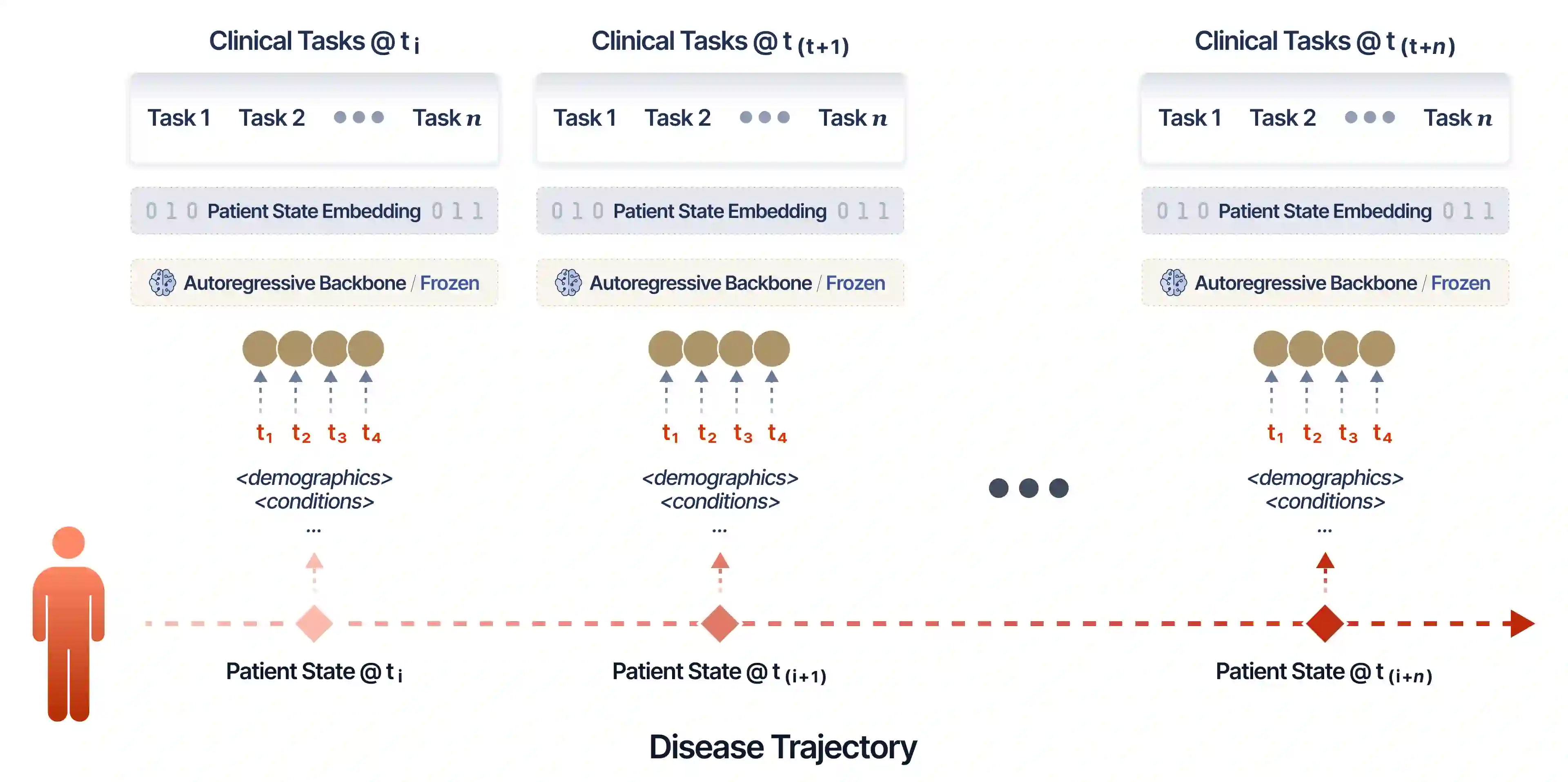
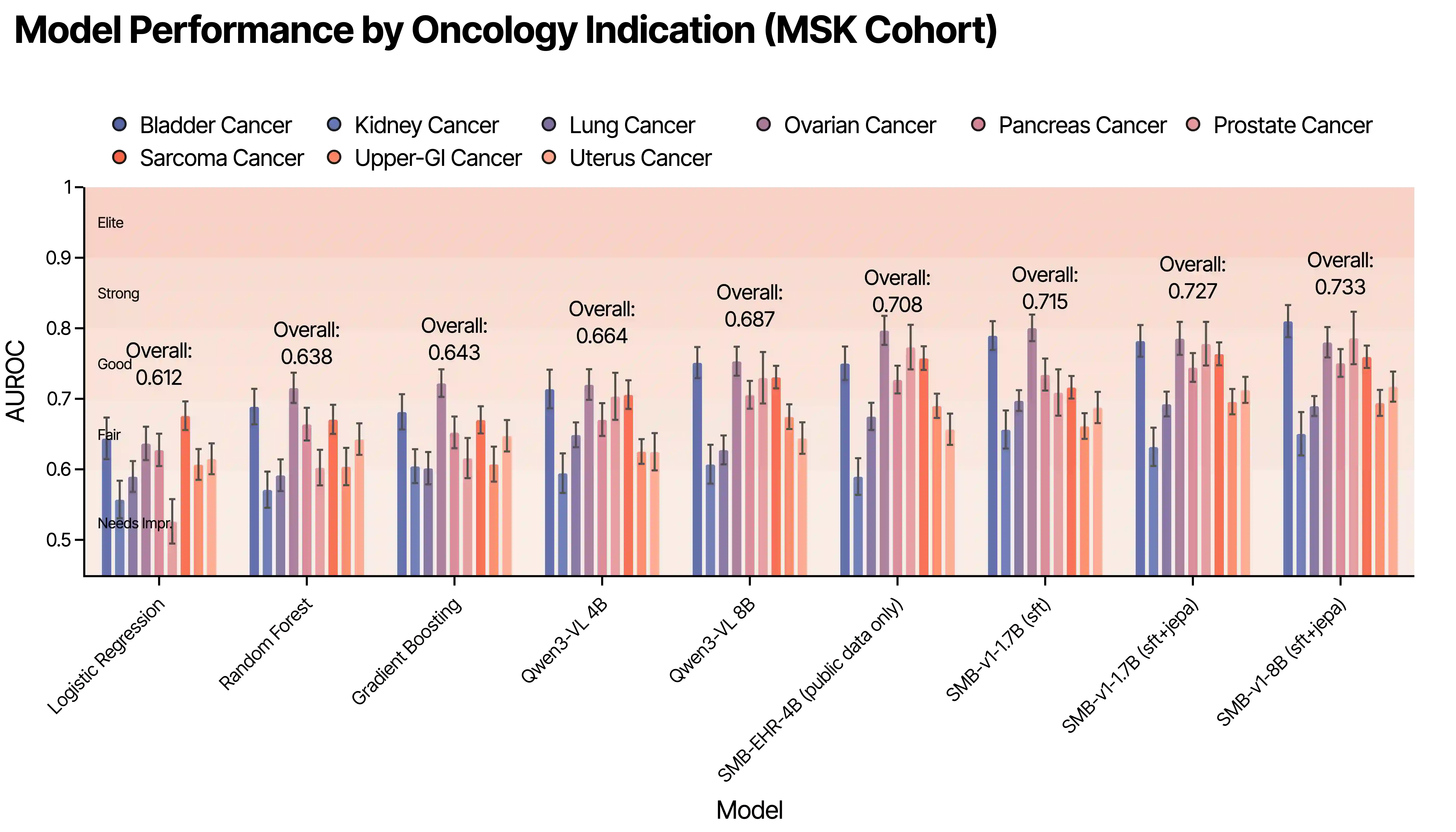
Large language models (LLMs) trained with next-word-prediction have achieved success as clinical foundation models. Representations from these language backbones yield strong linear probe performance across biomedical tasks, suggesting that patient semantics emerge from next-token prediction at scale. However, this paradigm treats patients as a document to be summarized rather than a dynamical system to be simulated; a patient's trajectory emerges from their state evolving under interventions and time, requiring models that simulate dynamics rather than predict tokens. To address this, we introduce SMB-Structure, a world model for structured EHR that grounds a joint-embedding prediction architecture (JEPA) with next-token prediction (SFT). SFT grounds our model to reconstruct future patient states in token space, while JEPA predicts those futures in latent space from the initial patient representation alone, forcing trajectory dynamics to be encoded before the next state is observed. We validate across two large-scale cohorts: Memorial Sloan Kettering (23,319 oncology patients; 323,000+ patient-years) and INSPECT (19,402 pulmonary embolism patients). Using a linear probe evaluated at multiple points along the disease trajectory, we demonstrate that our training paradigm learns embeddings that capture disease dynamics not recoverable by autoregressive baselines, enabling SMB-Structure to achieve competitive performance on complex tasks characterized by high patient heterogeneity. Model weights are available at https://huggingface.co/standardmodelbio/SMB-v1-1.7B-Structure.
翻译:通过下一词预测训练的大型语言模型(LLM)已成为成功的临床基础模型。这些语言骨干网络生成的表征在生物医学任务中展现出强大的线性探针性能,表明患者语义能够通过大规模的下一个词预测任务自然涌现。然而,该范式将患者视为待总结的文档,而非待模拟的动态系统;患者的病程轨迹源于其状态在干预措施和时间作用下的演化,这要求模型能够模拟动态过程而非仅预测词元。为此,我们提出SMB-Structure——一种面向结构化电子健康记录的世界模型,该模型将联合嵌入预测架构(JEPA)与下一词元预测(SFT)相结合。SFT使模型能够在词元空间中重建未来患者状态,而JEPA仅基于初始患者表征在潜在空间中预测未来状态,从而强制模型在观测到下一状态前编码轨迹动态信息。我们在两个大规模队列中进行了验证:纪念斯隆凯特琳癌症中心(23,319名肿瘤患者;超323,000患者-年)和INSPECT队列(19,402名肺栓塞患者)。通过沿疾病轨迹多个时间点评估的线性探针,我们证明该训练范式学习到的嵌入能够捕捉自回归基线模型无法恢复的疾病动态特征,使SMB-Structure在具有高度患者异质性的复杂任务中取得具有竞争力的性能。模型权重发布于https://huggingface.co/standardmodelbio/SMB-v1-1.7B-Structure。

相关内容

一是主要脏器无疾病,身体形态发育良好,体形均匀,人体各系统具有良好的生理功能,有较强的身体活动能力和劳动能力,这是对健康最基本的要求;
二是对疾病的抵抗能力较强,能够适应环境变化,各种生理刺激以及致病因素对身体的作用。传统的健康观是“无病即健康”,现代人的健康观是整体健康,世界卫生组织提出“健康不仅是躯体没有疾病,还要具备心理健康、社会适应良好和有道德”。因此,现代人的健康内容包括:躯体健康、心理健康、心灵健康、社会健康、智力健康、道德健康、环境健康等。健康是人的基本权利。健康是人生的第一财富。

