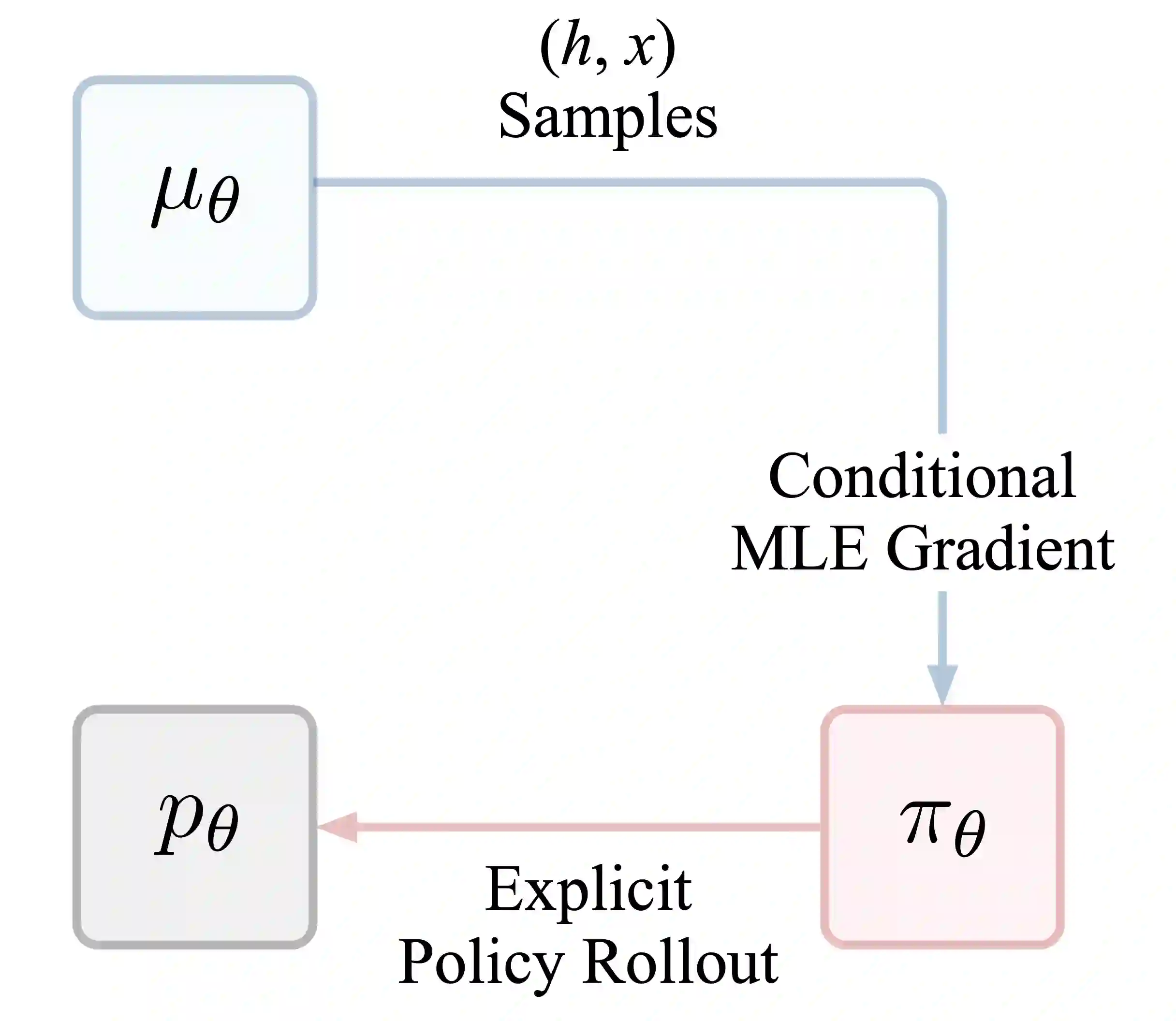
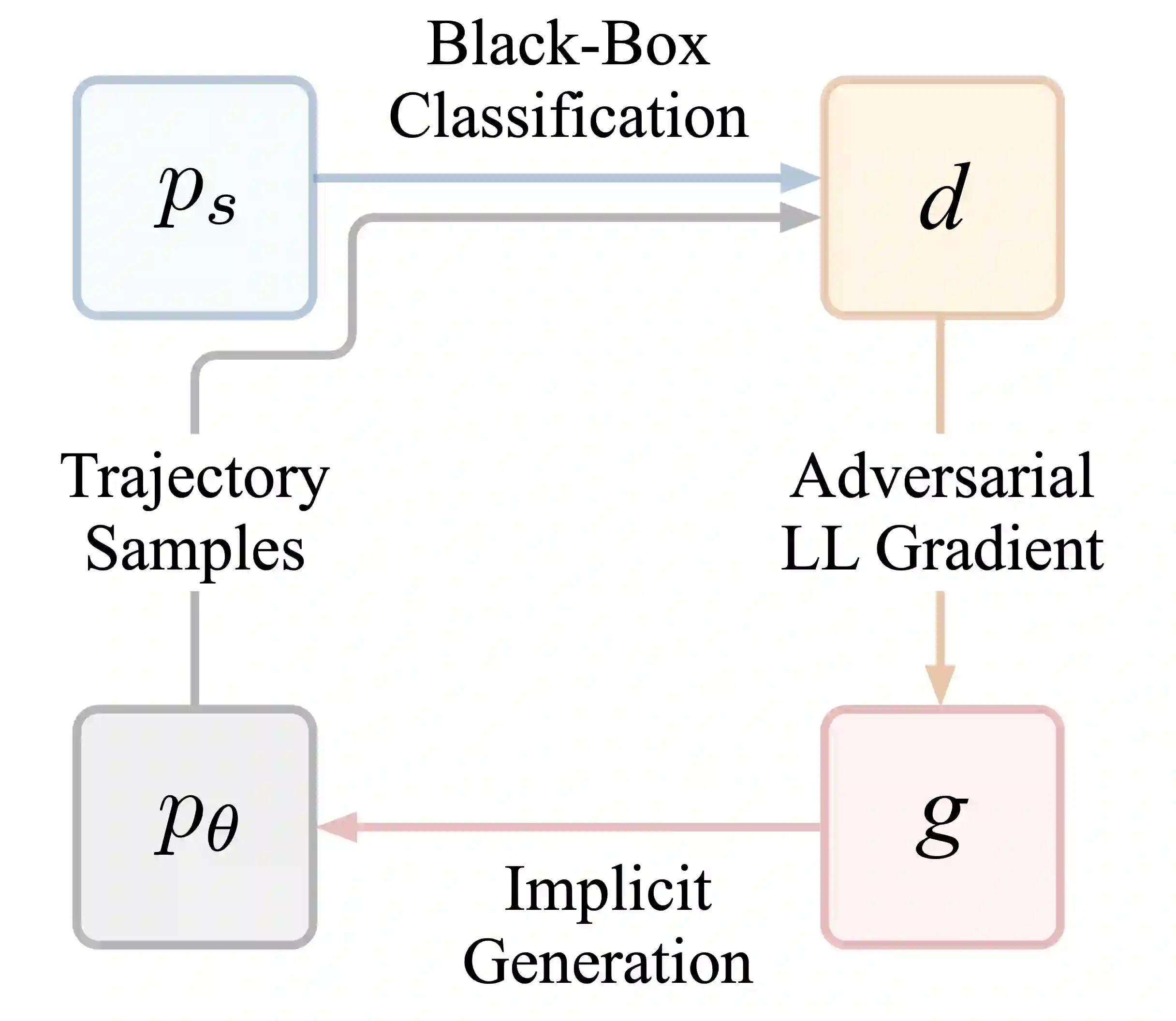
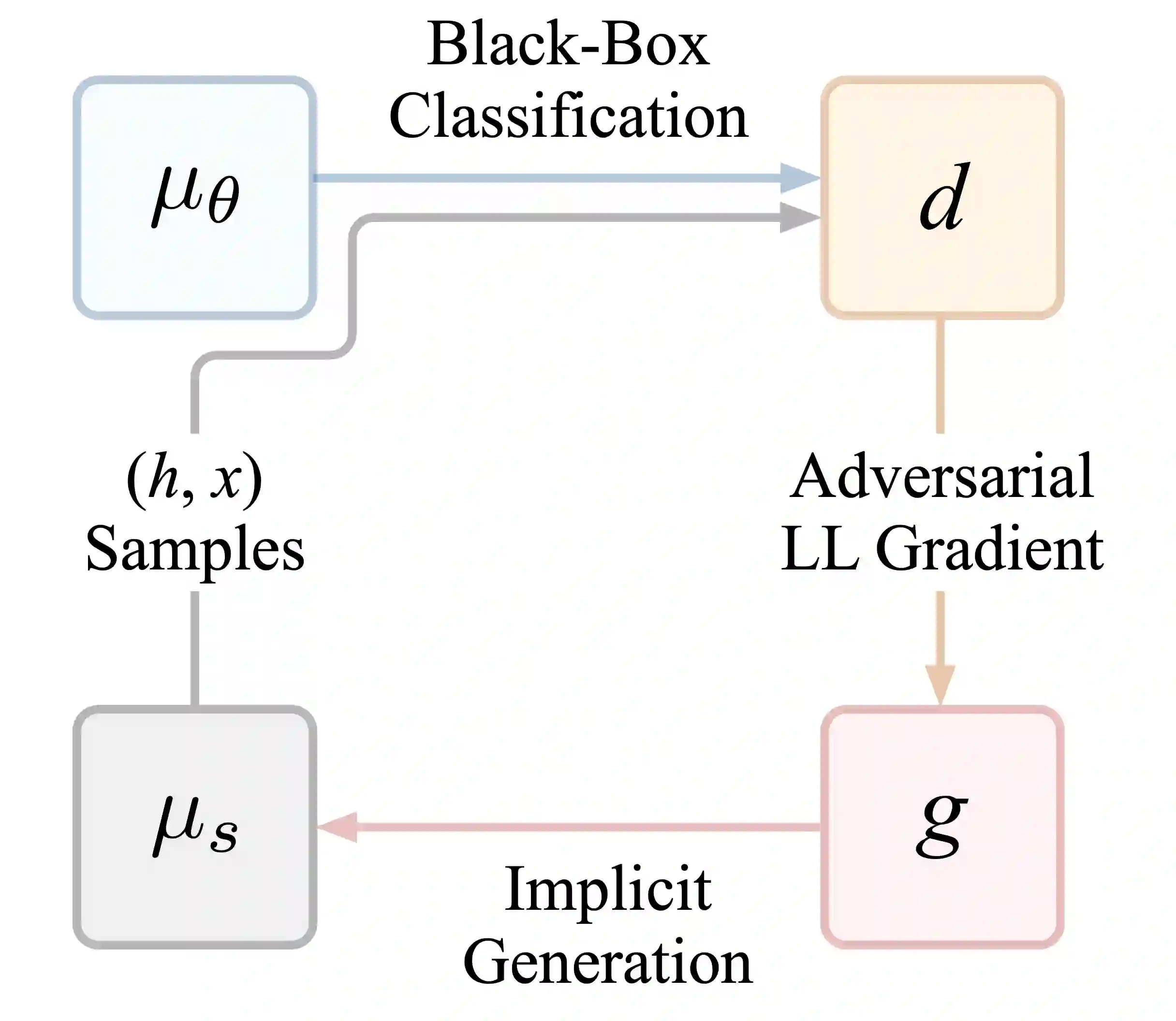
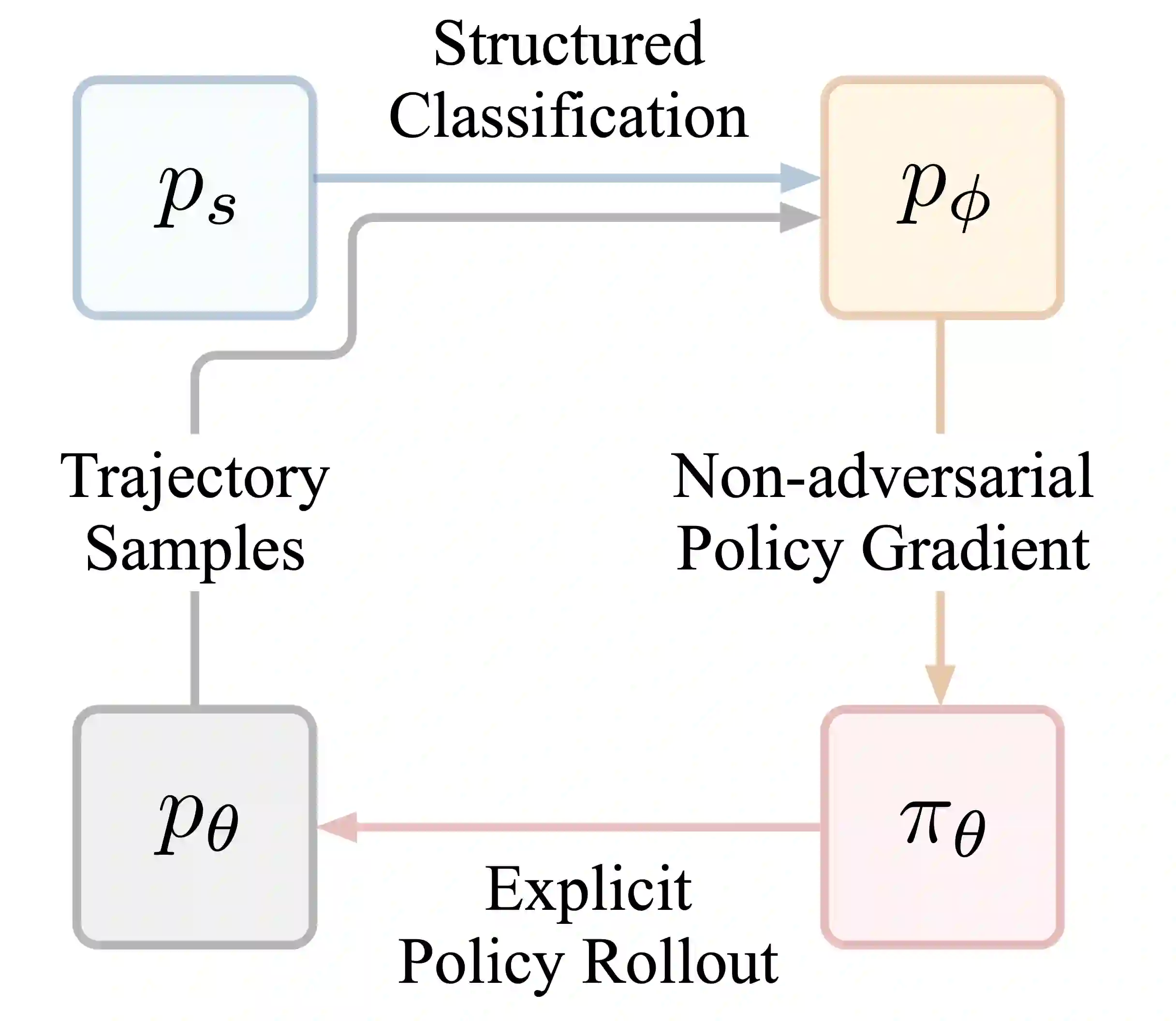
Consider learning a generative model for time-series data. The sequential setting poses a unique challenge: Not only should the generator capture the conditional dynamics of (stepwise) transitions, but its open-loop rollouts should also preserve the joint distribution of (multi-step) trajectories. On one hand, autoregressive models trained by MLE allow learning and computing explicit transition distributions, but suffer from compounding error during rollouts. On the other hand, adversarial models based on GAN training alleviate such exposure bias, but transitions are implicit and hard to assess. In this work, we study a generative framework that seeks to combine the strengths of both: Motivated by a moment-matching objective to mitigate compounding error, we optimize a local (but forward-looking) transition policy, where the reinforcement signal is provided by a global (but stepwise-decomposable) energy model trained by contrastive estimation. At training, the two components are learned cooperatively, avoiding the instabilities typical of adversarial objectives. At inference, the learned policy serves as the generator for iterative sampling, and the learned energy serves as a trajectory-level measure for evaluating sample quality. By expressly training a policy to imitate sequential behavior of time-series features in a dataset, this approach embodies "generation by imitation". Theoretically, we illustrate the correctness of this formulation and the consistency of the algorithm. Empirically, we evaluate its ability to generate predictively useful samples from real-world datasets, verifying that it performs at the standard of existing benchmarks.
翻译:考虑学习针对时间序列数据的生成模型。序列设定带来了独特挑战:生成器不仅应捕获(逐步)转换的条件动态,其开环生成结果还应保留(多步)轨迹的联合分布。一方面,采用极大似然估计训练的具有自回归性质的模型能够学习并计算显式转换分布,但在生成过程中会出现误差累积问题。另一方面,基于生成对抗网络训练的对抗模型缓解了此类暴露偏差,但转换过程是隐式的且难以评估。在本工作中,我们研究了一种旨在结合两者优势的生成框架:受缓解累积误差的矩匹配目标启发,我们优化一个局部(但具有前瞻性)的转换策略,其中强化信号由通过对比估计训练的全局(但可逐步骤分解)能量模型提供。在训练过程中,两个组件协同学习,避免了对抗目标中典型的不稳定性。在推理过程中,学习到的策略作为迭代采样的生成器,而学习到的能量则作为评估样本质量的轨迹级度量。通过明确训练策略以模仿数据集中时间序列特征的序列行为,该方法体现了"基于模仿的生成"。理论上,我们阐述了该公式的正确性及算法的一致性。实证上,我们从真实数据集中评估其生成具有预测价值样本的能力,验证了其性能达到现有基准标准。