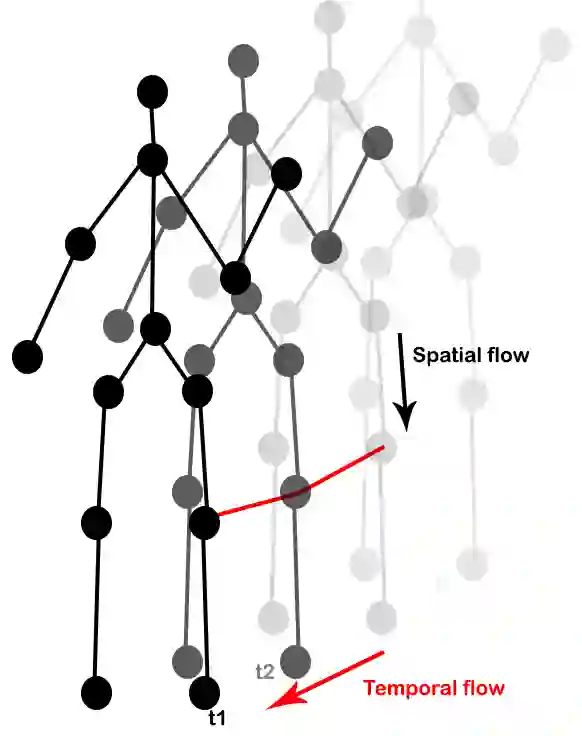
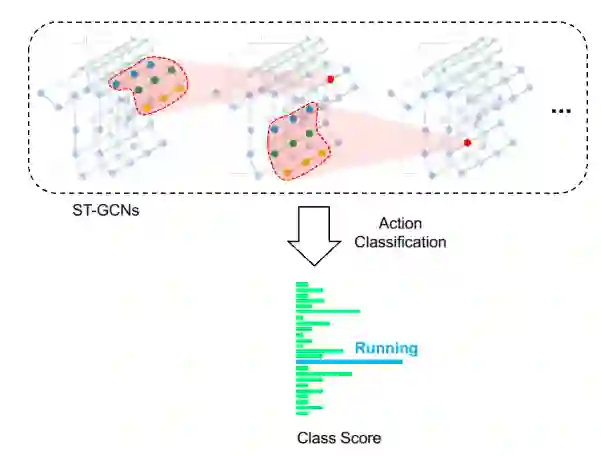
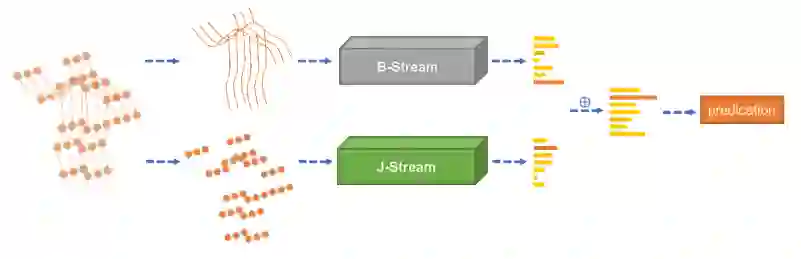
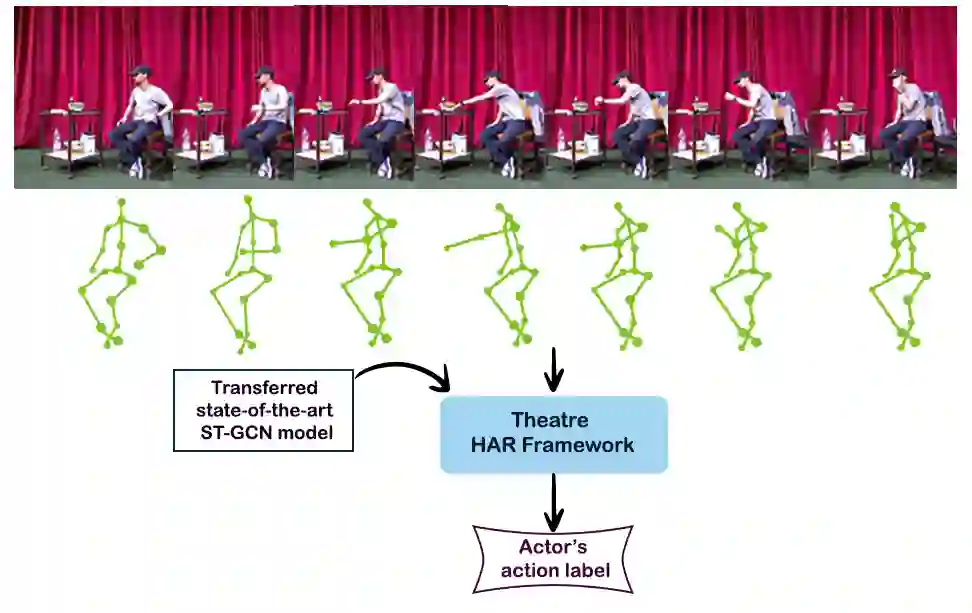
The aim of this research is to recognize human actions performed on stage to aid visually impaired and blind individuals. To achieve this, we have created a theatre human action recognition system that uses skeleton data captured by depth image as input. We collected new samples of human actions in a theatre environment, and then tested the transfer learning technique with three pre-trained Spatio-Temporal Graph Convolution Networks for skeleton-based human action recognition: the spatio-temporal graph convolution network, the two-stream adaptive graph convolution network, and the multi-scale disentangled unified graph convolution network. We selected the NTU-RGBD human action benchmark as the source domain and used our collected dataset as the target domain. We analyzed the transferability of the pre-trained models and proposed two configurations to apply and adapt the transfer learning technique to the diversity between the source and target domains. The use of transfer learning helped to improve the performance of the human action system within the context of theatre. The results indicate that Spatio-Temporal Graph Convolution Networks is positively transferred, and there was an improvement in performance compared to the baseline without transfer learning.
翻译:本研究旨在识别舞台上的人类动作,以辅助视障及盲人群体。为此,我们构建了一个剧场人体动作识别系统,该系统以深度图像捕获的骨架数据作为输入。我们采集了剧场环境中的新人体动作样本,并利用三种基于骨架的预训练时空图卷积网络(即时空图卷积网络、双流自适应图卷积网络和多尺度解缠统一图卷积网络)测试了迁移学习技术。我们选取NTU-RGBD人体动作基准数据集作为源域,将自建数据集作为目标域。通过分析预训练模型的可迁移性,针对源域与目标域间的差异,我们提出了两种迁移学习应用与适配方案。实验结果表明,迁移学习有效提升了剧场场景下人体动作系统的性能,且时空图卷积网络呈现出正向迁移效果,相较未使用迁移学习的基准模型其性能显著提升。