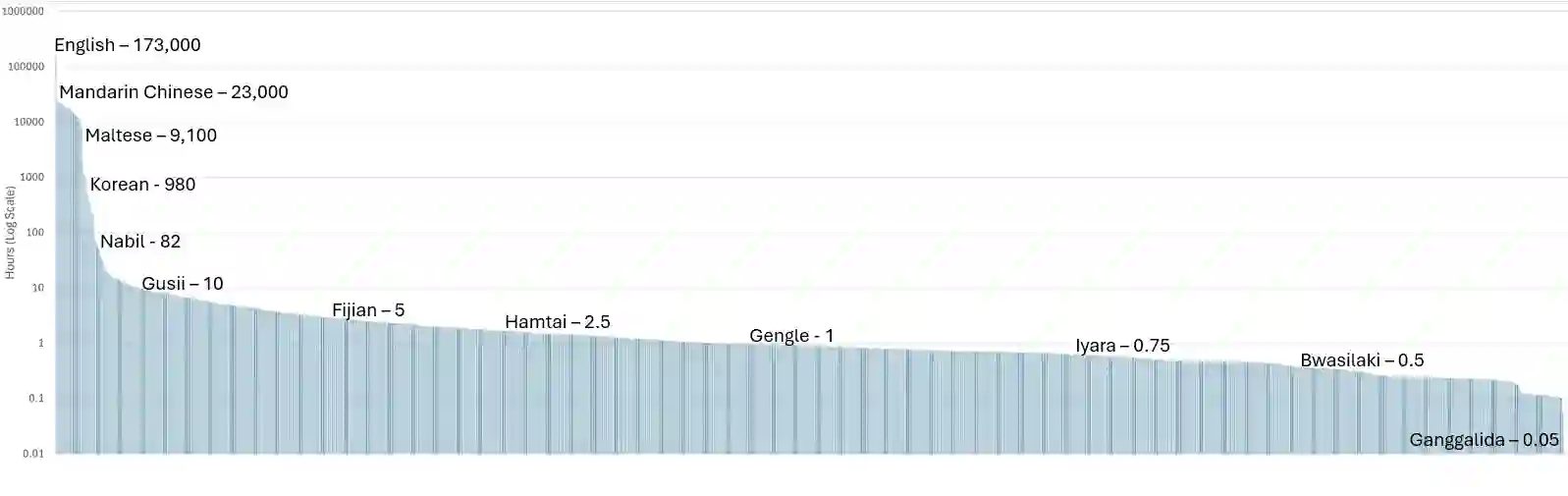
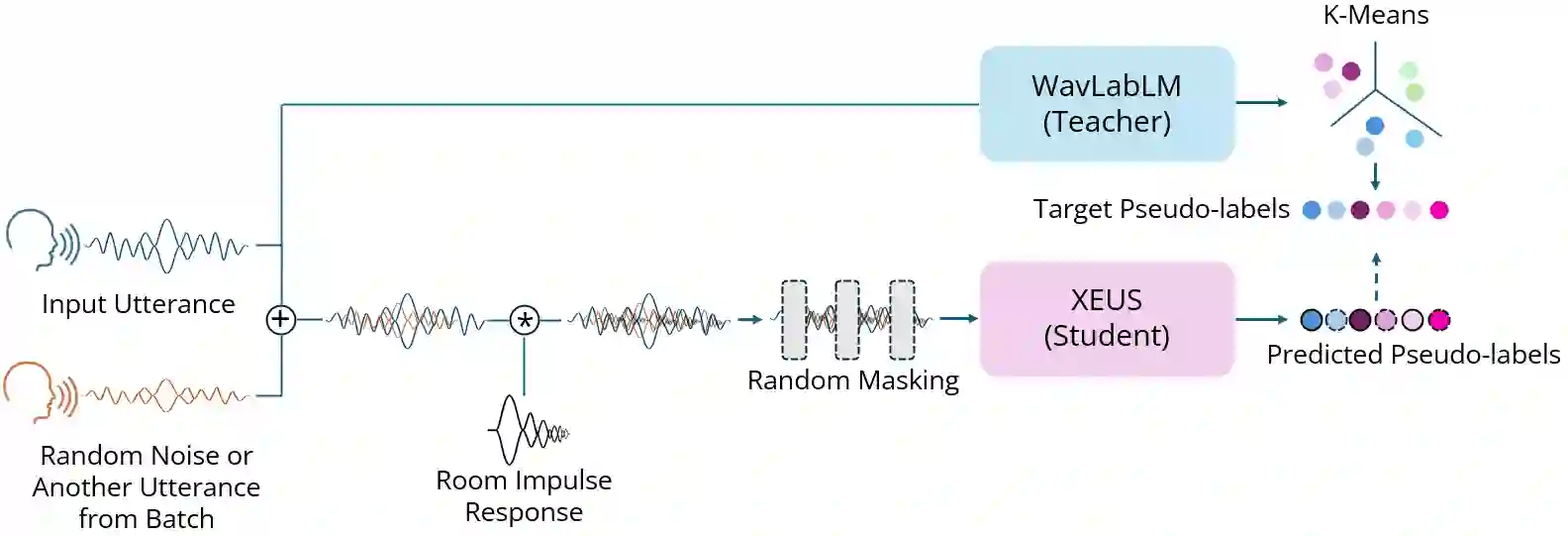
Self-supervised learning (SSL) has helped extend speech technologies to more languages by reducing the need for labeled data. However, models are still far from supporting the world's 7000+ languages. We propose XEUS, a Cross-lingual Encoder for Universal Speech, trained on over 1 million hours of data across 4057 languages, extending the language coverage of SSL models 4-fold. We combine 1 million hours of speech from existing publicly accessible corpora with a newly created corpus of 7400+ hours from 4057 languages, which will be publicly released. To handle the diverse conditions of multilingual speech data, we augment the typical SSL masked prediction approach with a novel dereverberation objective, increasing robustness. We evaluate XEUS on several benchmarks, and show that it consistently outperforms or achieves comparable results to state-of-the-art (SOTA) SSL models across a variety of tasks. XEUS sets a new SOTA on the ML-SUPERB benchmark: it outperforms MMS 1B and w2v-BERT 2.0 v2 by 0.8% and 4.4% respectively, despite having less parameters or pre-training data. Checkpoints, code, and data are found in https://www.wavlab.org/activities/2024/xeus/.
翻译:自监督学习通过减少对标注数据的需求,促进了语音技术向更多语言的扩展。然而,现有模型仍远未达到支持全球7000多种语言的水平。我们提出了XEUS(跨语言通用语音编码器),该模型在4057种语言的超过100万小时数据上进行训练,将自监督学习模型的语言覆盖范围扩展了四倍。我们整合了来自现有公开可访问语料库的100万小时语音数据,以及新创建的涵盖4057种语言的7400多小时语料库(该语料库将公开发布)。为应对多语言语音数据的多样化条件,我们在典型的自监督学习掩码预测方法基础上,引入了一种新颖的去混响目标,从而增强了模型的鲁棒性。我们在多个基准测试上评估XEUS,结果表明,在各种任务中,XEUS始终优于或达到与最先进自监督学习模型相当的性能。XEUS在ML-SUPERB基准测试中创造了新的最先进水平:尽管参数量或预训练数据更少,但其性能分别超过MMS 1B和w2v-BERT 2.0 v2模型0.8%和4.4%。模型检查点、代码及数据可在https://www.wavlab.org/activities/2024/xeus/获取。