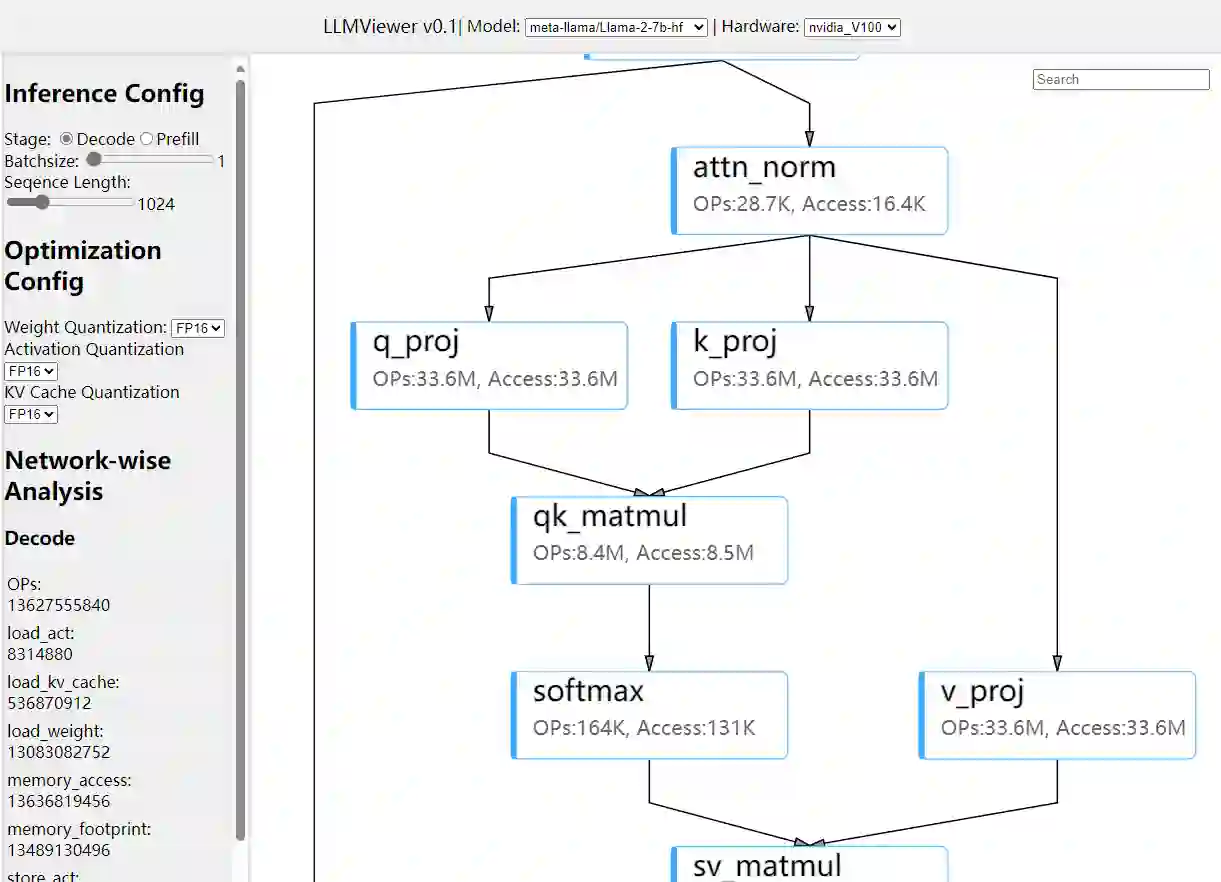
The field of efficient Large Language Model (LLM) inference is rapidly evolving, presenting a unique blend of opportunities and challenges. Although the field has expanded and is vibrant, there hasn't been a concise framework that analyzes the various methods of LLM Inference to provide a clear understanding of this domain. Our survey stands out from traditional literature reviews by not only summarizing the current state of research but also by introducing a framework based on roofline model for systematic analysis of LLM inference techniques. This framework identifies the bottlenecks when deploying LLMs on hardware devices and provides a clear understanding of practical problems, such as why LLMs are memory-bound, how much memory and computation they need, and how to choose the right hardware. We systematically collate the latest advancements in efficient LLM inference, covering crucial areas such as model compression (e.g., Knowledge Distillation and Quantization), algorithm improvements (e.g., Early Exit and Mixture-of-Expert), and both hardware and system-level enhancements. Our survey stands out by analyzing these methods with roofline model, helping us understand their impact on memory access and computation. This distinctive approach not only showcases the current research landscape but also delivers valuable insights for practical implementation, positioning our work as an indispensable resource for researchers new to the field as well as for those seeking to deepen their understanding of efficient LLM deployment. The analyze tool, LLM-Viewer, is open-sourced.
翻译:高效大型语言模型推理领域正在快速发展,呈现出机遇与挑战并存的独特格局。尽管该领域规模不断扩大且充满活力,但尚未出现一个简洁的框架来系统分析各类LLM推理方法,以提供对该领域的清晰认知。本综述不仅通过总结当前研究现状区别于传统文献回顾,更引入基于屋顶线模型的分析框架,对LLM推理技术进行系统性研究。该框架能识别在硬件设备上部署LLM时的瓶颈,并提供对实际问题的清晰理解,例如:为何LLM会受到内存限制、所需内存与算力的大小关系,以及如何选择合适硬件等问题。我们系统梳理了高效LLM推理的最新进展,涵盖模型压缩(如知识蒸馏与量化)、算法改进(如早期退出与混合专家)、以及硬件与系统级优化等关键领域。本综述的独特性在于采用屋顶线模型分析这些方法,帮助理解其对内存访问与计算的影响。这一独特方法不仅展示了当前研究格局,更对实际部署提供了宝贵见解,使本工作成为领域新手及希望深入理解高效LLM部署的研究人员不可或缺的资源。分析工具LLM-Viewer已开源。