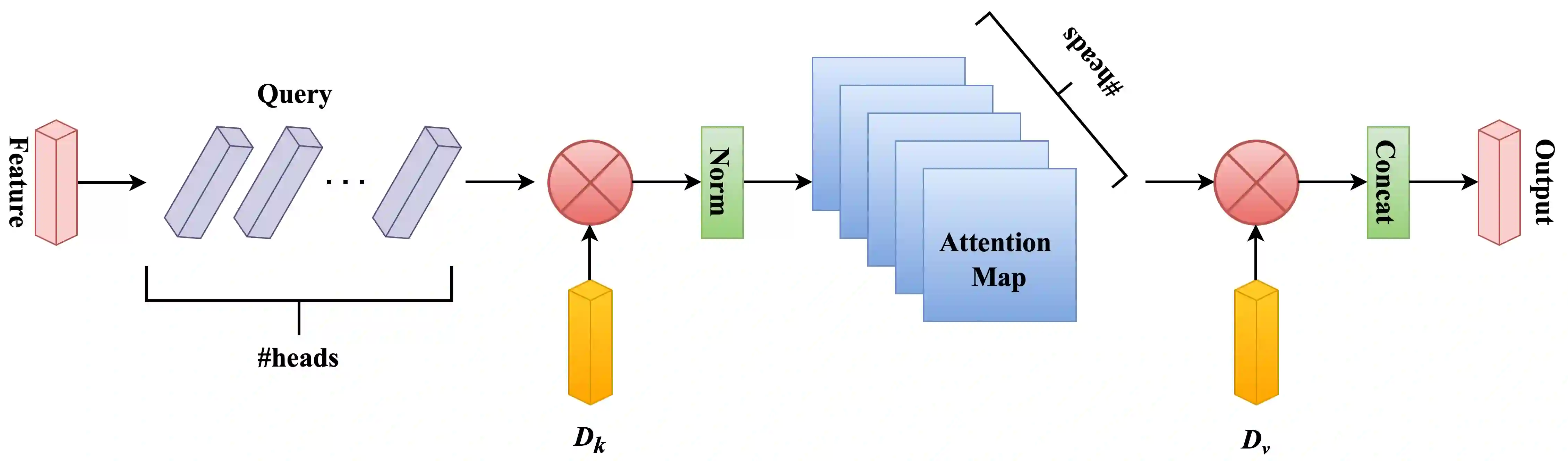
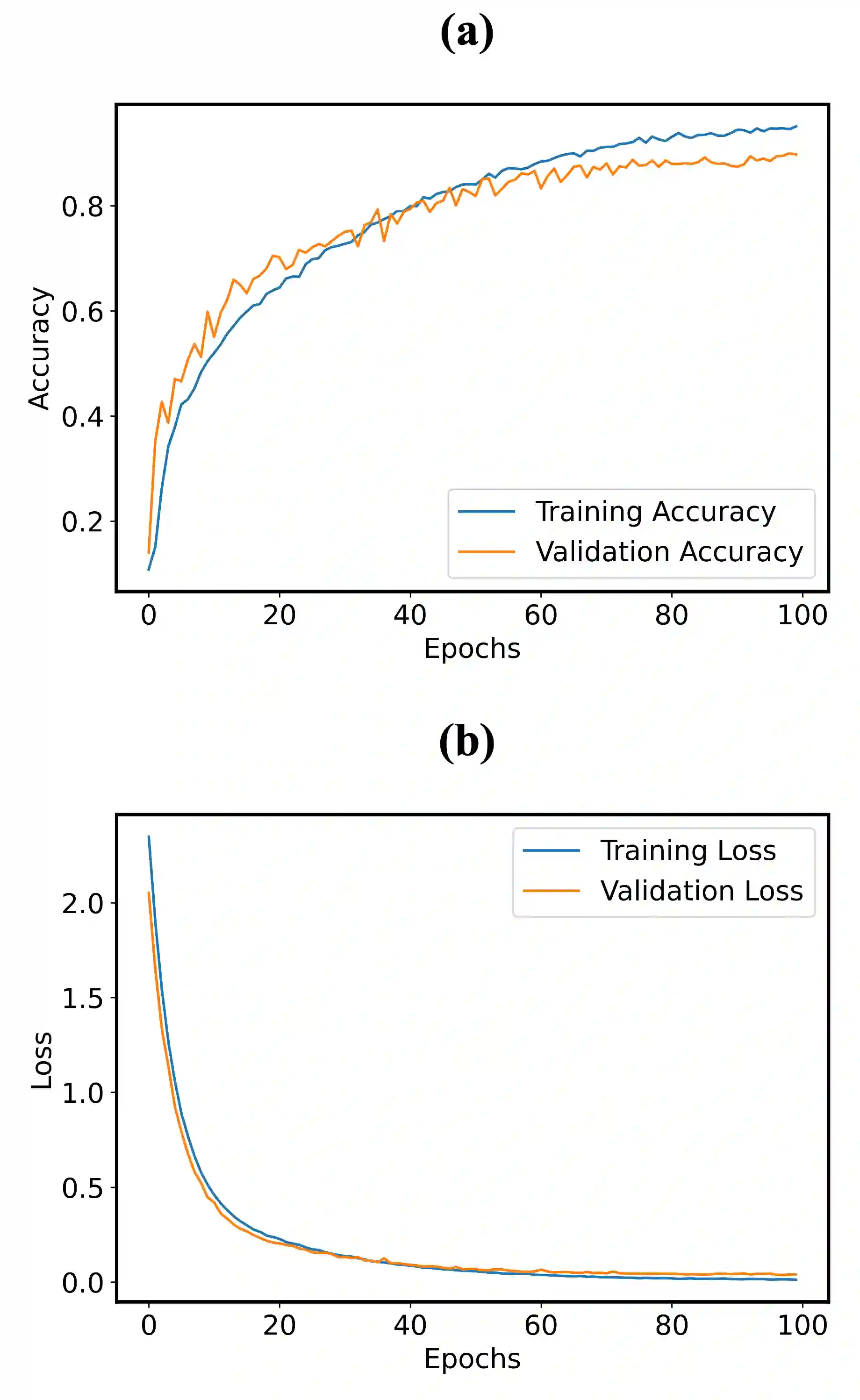
This paper presents the External Attention Vision Transformer (EAViT) model, a novel approach designed to enhance audio classification accuracy. As digital audio resources proliferate, the demand for precise and efficient audio classification systems has intensified, driven by the need for improved recommendation systems and user personalization in various applications, including music streaming platforms and environmental sound recognition. Accurate audio classification is crucial for organizing vast audio libraries into coherent categories, enabling users to find and interact with their preferred audio content more effectively. In this study, we utilize the GTZAN dataset, which comprises 1,000 music excerpts spanning ten diverse genres. Each 30-second audio clip is segmented into 3-second excerpts to enhance dataset robustness and mitigate overfitting risks, allowing for more granular feature analysis. The EAViT model integrates multi-head external attention (MEA) mechanisms into the Vision Transformer (ViT) framework, effectively capturing long-range dependencies and potential correlations between samples. This external attention (EA) mechanism employs learnable memory units that enhance the network's capacity to process complex audio features efficiently. The study demonstrates that EAViT achieves a remarkable overall accuracy of 93.99%, surpassing state-of-the-art models.
翻译:本文提出了外部注意力视觉Transformer(EAViT)模型,这是一种旨在提升音频分类准确性的新颖方法。随着数字音频资源的激增,在音乐流媒体平台和环境声音识别等多种应用中,改进推荐系统和用户个性化的需求日益迫切,从而推动了对精确高效音频分类系统的强烈需求。准确的音频分类对于将庞大的音频库组织成连贯的类别至关重要,使用户能够更有效地查找并与其偏好的音频内容进行交互。在本研究中,我们采用GTZAN数据集,该数据集包含涵盖十种不同流派的1000个音乐片段。每个30秒的音频片段被分割为3秒的片段,以增强数据集的鲁棒性并降低过拟合风险,从而实现更细粒度的特征分析。EAViT模型将多头外部注意力(MEA)机制集成到视觉Transformer(ViT)框架中,有效捕获样本间的长程依赖性和潜在相关性。这种外部注意力(EA)机制采用可学习的记忆单元,增强了网络高效处理复杂音频特征的能力。研究表明,EAViT实现了93.99%的卓越总体准确率,超越了现有最先进的模型。