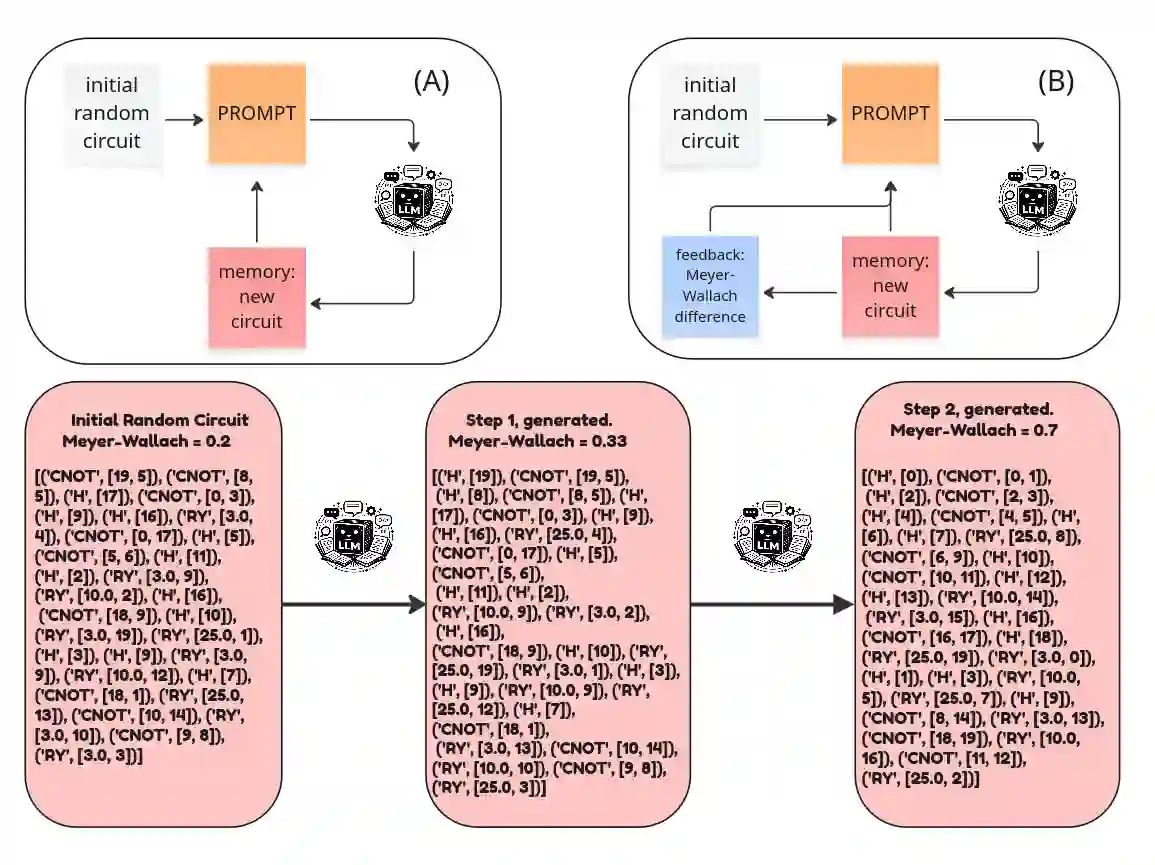
Large language models (LLMs) can generate structured artifacts, but using them as dependable optimizers for scientific design requires a mechanism for iterative improvement under black-box evaluation. Here, we cast quantum circuit synthesis as a closed-loop, test-time optimization problem: an LLM proposes edits to a fixed-length gate list, and an external simulator evaluates the resulting state with the Meyer-Wallach (MW) global entanglement measure. We introduce a lightweight test-time learning recipe that can reuse prior high-performing candidates as an explicit memory trace, augments prompts with a score-difference feedback, and applies restart-from-the-best sampling to escape potential plateaus. Across fixed 20-qubit settings, the loop without feedback and restart-from-the-best improves random initial circuits over a range of gate budgets. To lift up this performance and success rate, we use the full learning strategy. For the 25-qubit, it mitigates a pronounced performance plateau when naive querying is used. Beyond raw scores, we analyze the structure of synthesized states and find that high MW solutions can correspond to stabilizer or graph-state-like constructions, but full connectivity is not guaranteed due to the metric property and prompt design. These results illustrate both the promise and the pitfalls of memory evaluator-guided LLM optimization for circuit synthesis, highlighting the critical role of prior human-made theoretical theorems to optimally design a custom tool in support of research.
翻译:大型语言模型(LLM)能够生成结构化产物,但将其作为科学设计的可靠优化器使用,需要一种在黑盒评估下进行迭代改进的机制。本文将量子电路综合构建为一个闭环的测试时优化问题:LLM 对固定长度的门列表提出编辑建议,外部模拟器则使用 Meyer-Wallach (MW) 全局纠缠度量来评估生成的状态。我们提出了一种轻量级的测试时学习方案,该方案能够复用先前的高性能候选电路作为显式记忆轨迹,通过分数差异反馈来增强提示,并应用“从最佳重启”采样以逃离可能的性能平台期。在固定的 20 量子比特设置下,即使没有反馈和“从最佳重启”机制的优化循环,也能在一系列门预算范围内改进随机初始电路。为了提升性能和成功率,我们使用了完整的学习策略。对于 25 量子比特的情况,该策略缓解了在单纯查询时出现的显著性能平台期。除了原始分数,我们还分析了合成状态的结构,发现高 MW 分数的解可能对应于稳定子态或类图态结构,但由于度量特性和提示设计,并不能保证完全连通性。这些结果既说明了记忆评估器引导的 LLM 优化在电路综合中的潜力,也揭示了其局限,并凸显了利用既有的人为理论定理来优化设计定制化研究工具的关键作用。