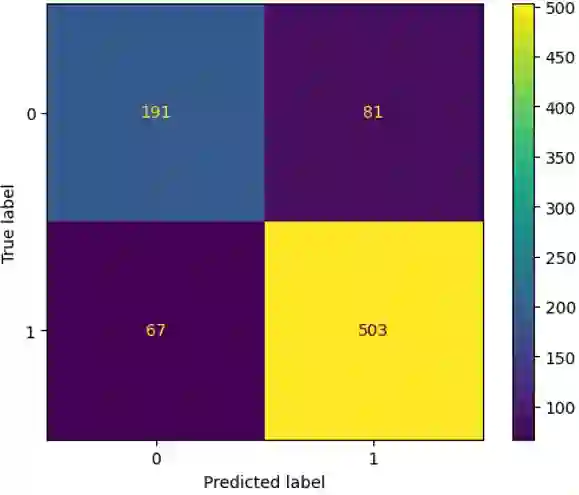
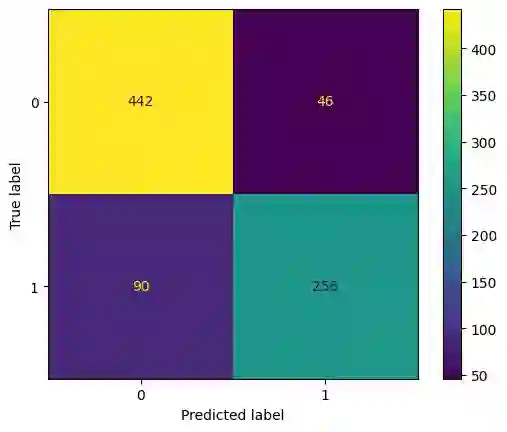
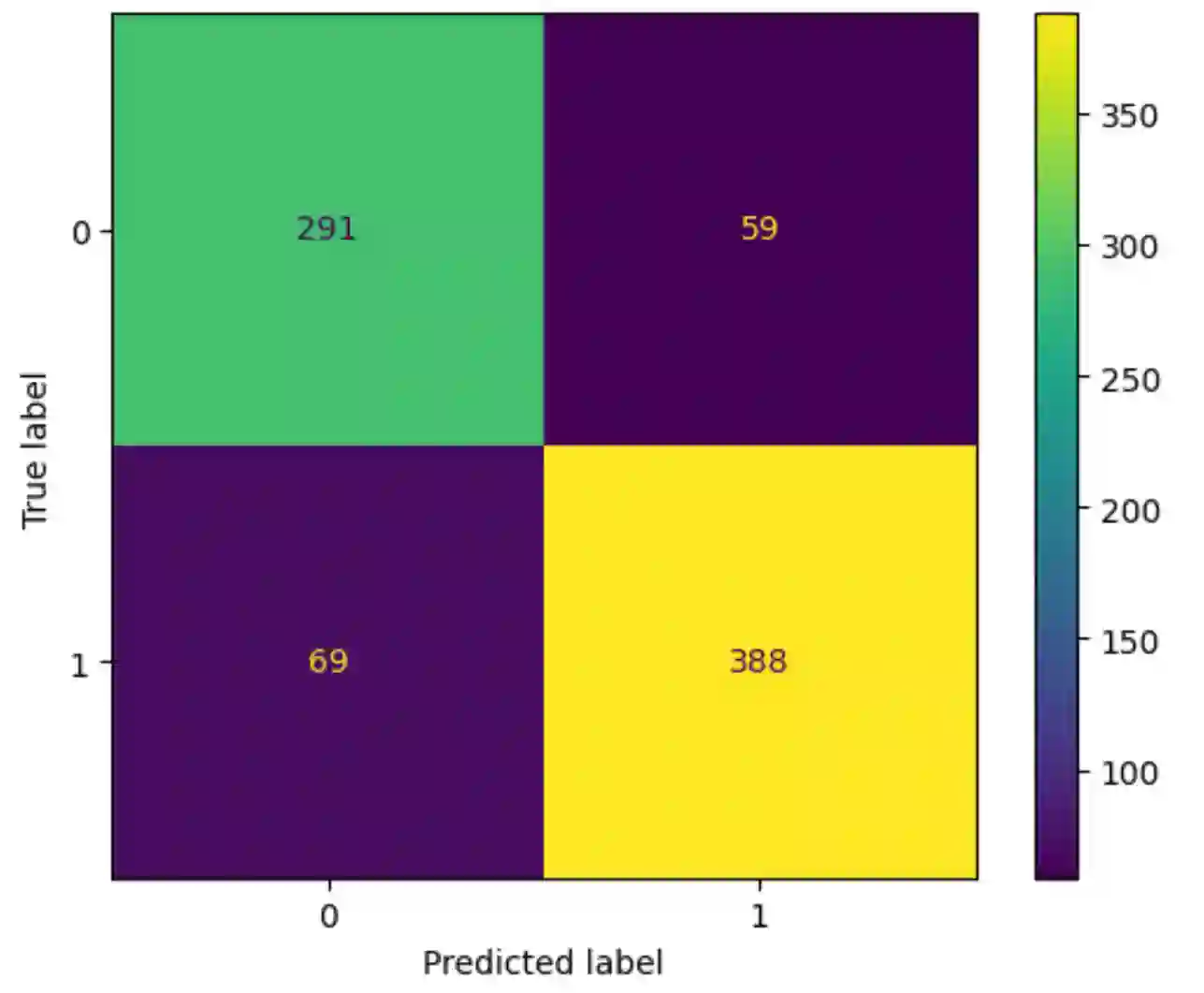
Translation Quality Evaluation (TQE) is an essential step of the modern translation production process. TQE is critical in assessing both machine translation (MT) and human translation (HT) quality without reference translations. The ability to evaluate or even simply estimate the quality of translation automatically may open significant efficiency gains through process optimisation. This work examines whether the state-of-the-art large language models (LLMs) can be used for this purpose. We take OpenAI models as the best state-of-the-art technology and approach TQE as a binary classification task. On eight language pairs including English to Italian, German, French, Japanese, Dutch, Portuguese, Turkish, and Chinese, our experimental results show that fine-tuned gpt3.5 can demonstrate good performance on translation quality prediction tasks, i.e. whether the translation needs to be edited. Another finding is that simply increasing the sizes of LLMs does not lead to apparent better performances on this task by comparing the performance of three different versions of OpenAI models: curie, davinci, and gpt3.5 with 13B, 175B, and 175B parameters, respectively.
翻译:翻译质量评估(TQE)是现代翻译生产流程中的关键环节。TQE对于在无参考译文的情况下评估机器翻译(MT)和人工翻译(HT)的质量至关重要。自动评估乃至简单估算翻译质量的能力,可通过流程优化带来显著的效率提升。本研究探讨了当前最先进的大语言模型(LLMs)能否用于此目的。我们将OpenAI模型视为当前最佳技术,并将TQE视为二元分类任务。在包括英语到意大利语、德语、法语、日语、荷兰语、葡萄牙语、土耳其语和中文的八个语言对上,实验结果表明,经过微调的gpt3.5在翻译质量预测任务(即判断译文是否需要编辑)上能表现出良好性能。另一项发现是,通过比较参数规模分别为130亿、1750亿和1750亿的三种不同版本OpenAI模型(curie、davinci和gpt3.5)的性能,单纯增加LLM的规模并未在此任务上带来明显更好的表现。