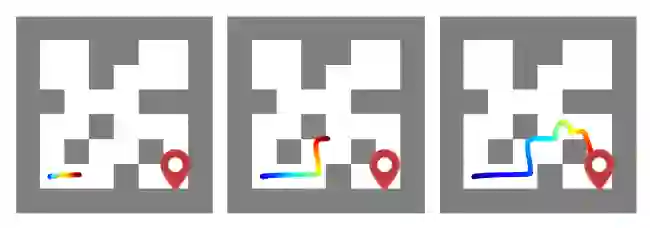
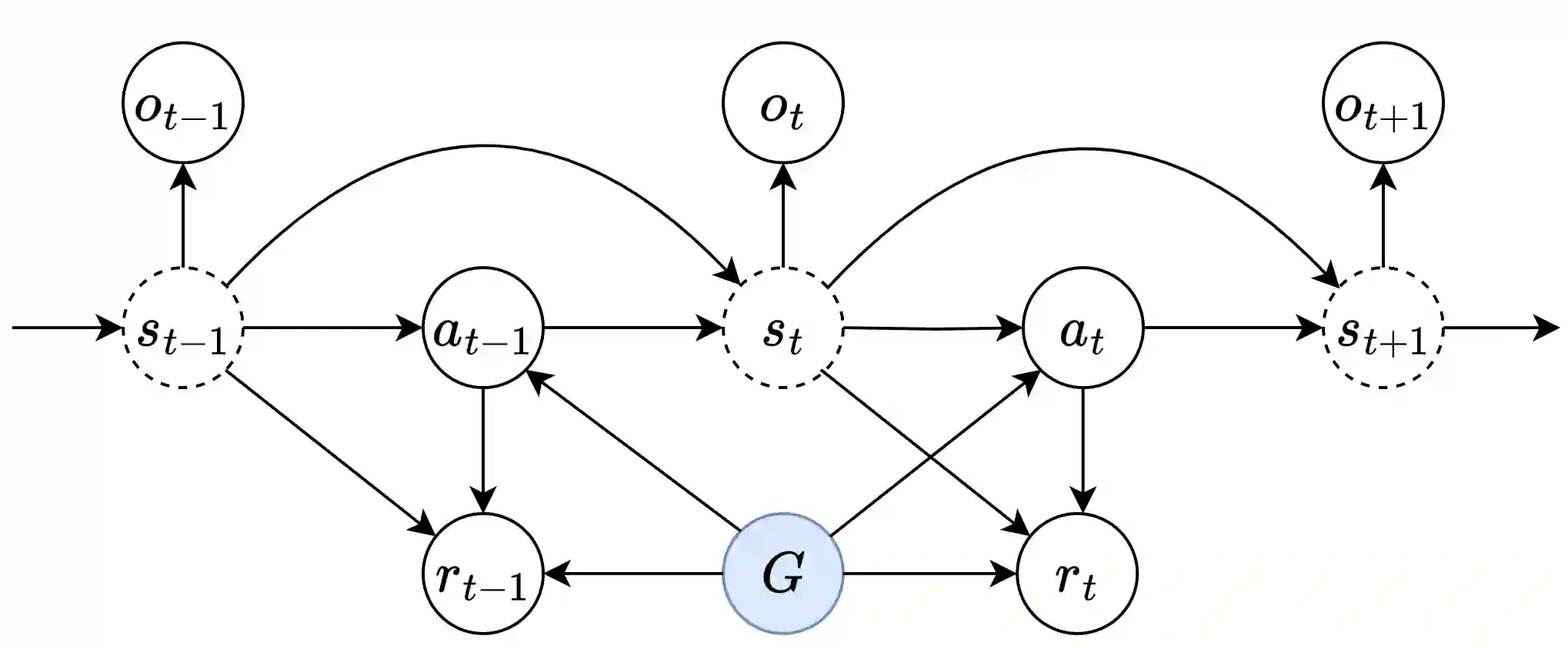
Reinforcement learning presents an attractive paradigm to reason about several distinct aspects of sequential decision making, such as specifying complex goals, planning future observations and actions, and critiquing their utilities. However, the combined integration of these capabilities poses competing algorithmic challenges in retaining maximal expressivity while allowing for flexibility in modeling choices for efficient learning and inference. We present Decision Stacks, a generative framework that decomposes goal-conditioned policy agents into 3 generative modules. These modules simulate the temporal evolution of observations, rewards, and actions via independent generative models that can be learned in parallel via teacher forcing. Our framework guarantees both expressivity and flexibility in designing individual modules to account for key factors such as architectural bias, optimization objective and dynamics, transferrability across domains, and inference speed. Our empirical results demonstrate the effectiveness of Decision Stacks for offline policy optimization for several MDP and POMDP environments, outperforming existing methods and enabling flexible generative decision making.
翻译:强化学习为推理顺序决策中的多个不同方面提供了有吸引力的范式,例如指定复杂目标、规划未来的观察与动作以及评判其效用。然而,这些能力的整合在保留最大表达力的同时,要求对建模选择保持灵活性以实现高效学习与推理,这构成了算法上的竞争性挑战。我们提出决策堆栈(Decision Stacks),这是一个生成式框架,将目标条件策略智能体分解为3个生成模块。这些模块通过可并行学习(使用教师强制法)的独立生成模型,模拟观察、奖励和动作的时间演化。我们的框架保证了在设计独立模块时的表达力与灵活性,可处理架构偏差、优化目标与动力学、跨领域迁移能力以及推理速度等关键因素。实证结果表明,决策堆栈在多个MDP和POMDP环境下的离线策略优化中表现出色,优于现有方法,并实现了灵活生成式决策。