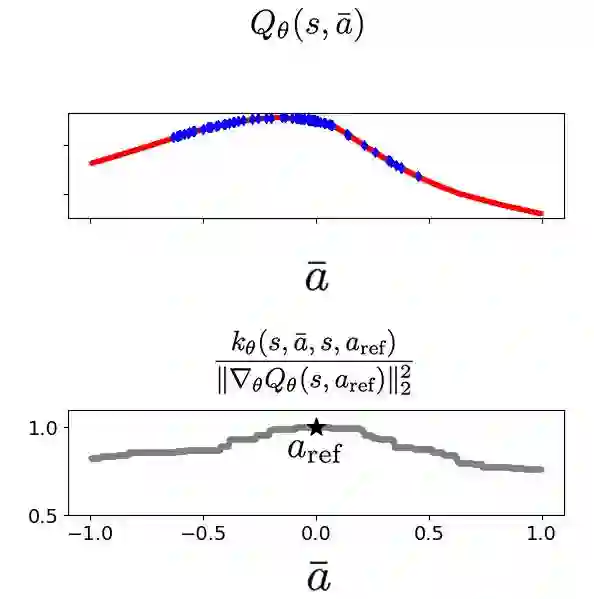
Offline reinforcement learning (RL) has progressed with return-conditioned supervised learning (RCSL), but its lack of stitching ability remains a limitation. We introduce $Q$-Aided Conditional Supervised Learning (QCS), which effectively combines the stability of RCSL with the stitching capability of $Q$-functions. By analyzing $Q$-function over-generalization, which impairs stable stitching, QCS adaptively integrates $Q$-aid into RCSL's loss function based on trajectory return. Empirical results show that QCS significantly outperforms RCSL and value-based methods, consistently achieving or exceeding the maximum trajectory returns across diverse offline RL benchmarks.
翻译:离线强化学习(RL)在基于回报的条件监督学习(RCSL)的推动下取得了进展,但其缺乏拼接能力仍然是一个局限。我们提出了Q值辅助的条件监督学习(QCS),该方法有效地将RCSL的稳定性与Q函数的拼接能力相结合。通过分析损害稳定拼接的Q函数过度泛化问题,QCS根据轨迹回报自适应地将Q值辅助整合到RCSL的损失函数中。实证结果表明,QCS在多种离线RL基准测试中显著优于RCSL和基于价值的方法,持续达到或超过最大轨迹回报。