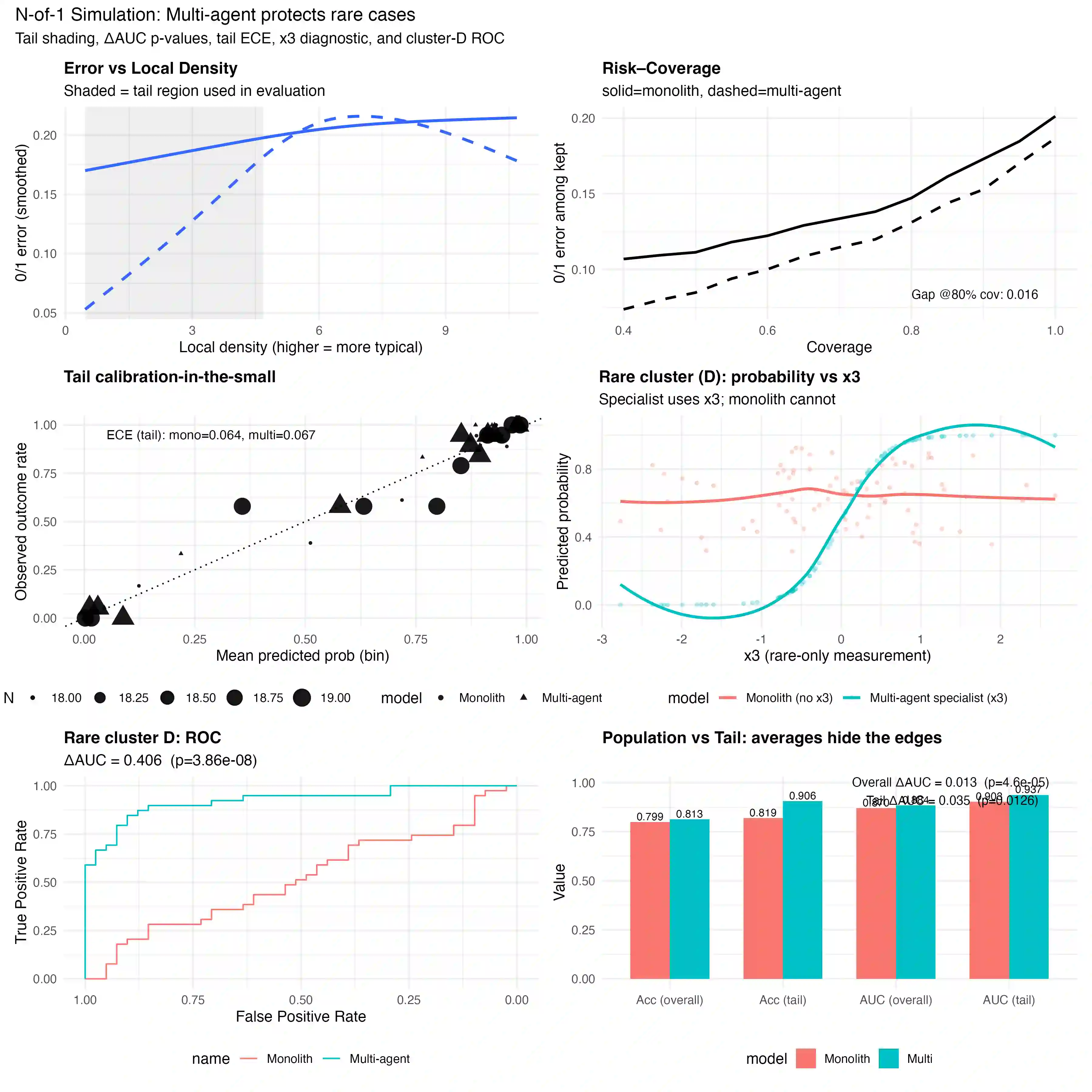
Artificial intelligence in medicine is built to serve the average patient. By minimizing error across large datasets, most systems deliver strong aggregate accuracy yet falter at the margins: patients with rare variants, multimorbidity, or underrepresented demographics. This average patient fallacy erodes both equity and trust. We propose a different design: a multi-agent ecosystem for N-of-1 decision support. In this environment, agents clustered by organ systems, patient populations, and analytic modalities draw on a shared library of models and evidence synthesis tools. Their results converge in a coordination layer that weighs reliability, uncertainty, and data density before presenting the clinician with a decision-support packet: risk estimates bounded by confidence ranges, outlier flags, and linked evidence. Validation shifts from population averages to individual reliability, measured by error in low-density regions, calibration in the small, and risk--coverage trade-offs. Anticipated challenges include computational demands, automation bias, and regulatory fit, addressed through caching strategies, consensus checks, and adaptive trial frameworks. By moving from monolithic models to orchestrated intelligence, this approach seeks to align medical AI with the first principle of medicine: care that is transparent, equitable, and centered on the individual.
翻译:医学人工智能系统通常为平均患者设计。通过在大规模数据集上最小化误差,多数系统虽能实现较高的整体准确率,却在边缘病例上表现不佳:如罕见变异患者、多病共存患者或代表性不足的人群。这种‘平均患者谬误’既损害公平性,也削弱信任度。我们提出一种全新设计:面向N-of-1决策支持的多智能体生态系统。在该环境中,按器官系统、患者群体和分析模式聚类的智能体,共享模型库与证据合成工具。其输出结果在协调层汇聚,该层综合评估可靠性、不确定性与数据密度后,向临床医生呈现决策支持包:包含置信区间限定的风险估计、异常值标记及关联证据链。验证标准从群体平均值转向个体可靠性,通过低数据密度区域的误差测量、小样本校准及风险-覆盖范围权衡进行评估。预期挑战包括计算需求、自动化偏差与监管适配,将通过缓存策略、共识校验和适应性试验框架予以应对。通过从单一模型转向协同智能,本方案旨在使医疗AI与医学首要原则对齐:提供透明、公平且以个体为中心的诊疗服务。