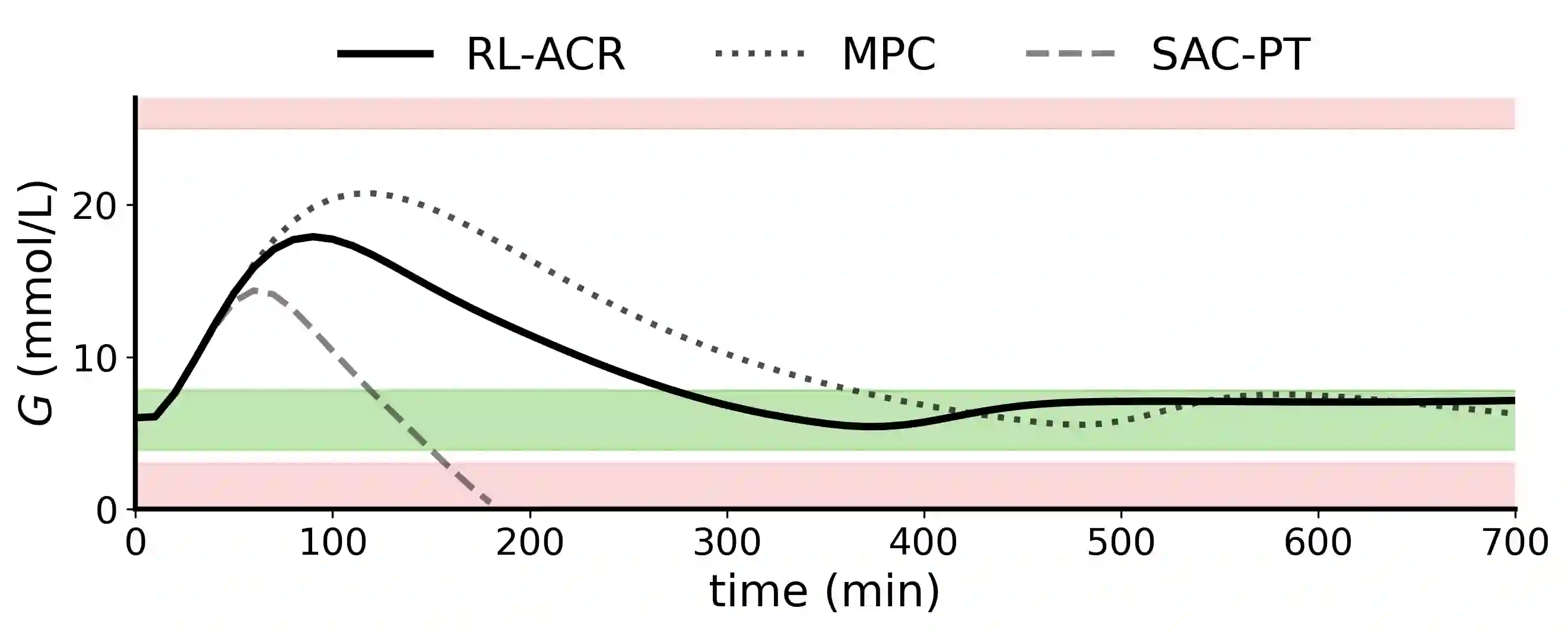
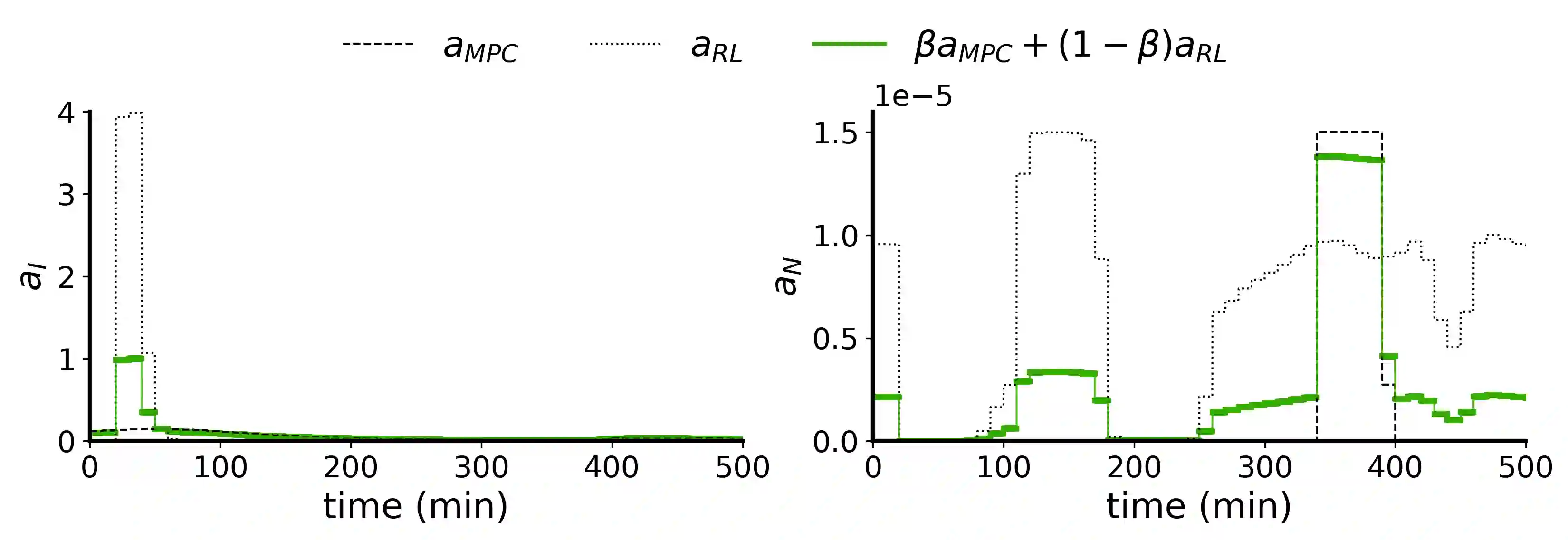
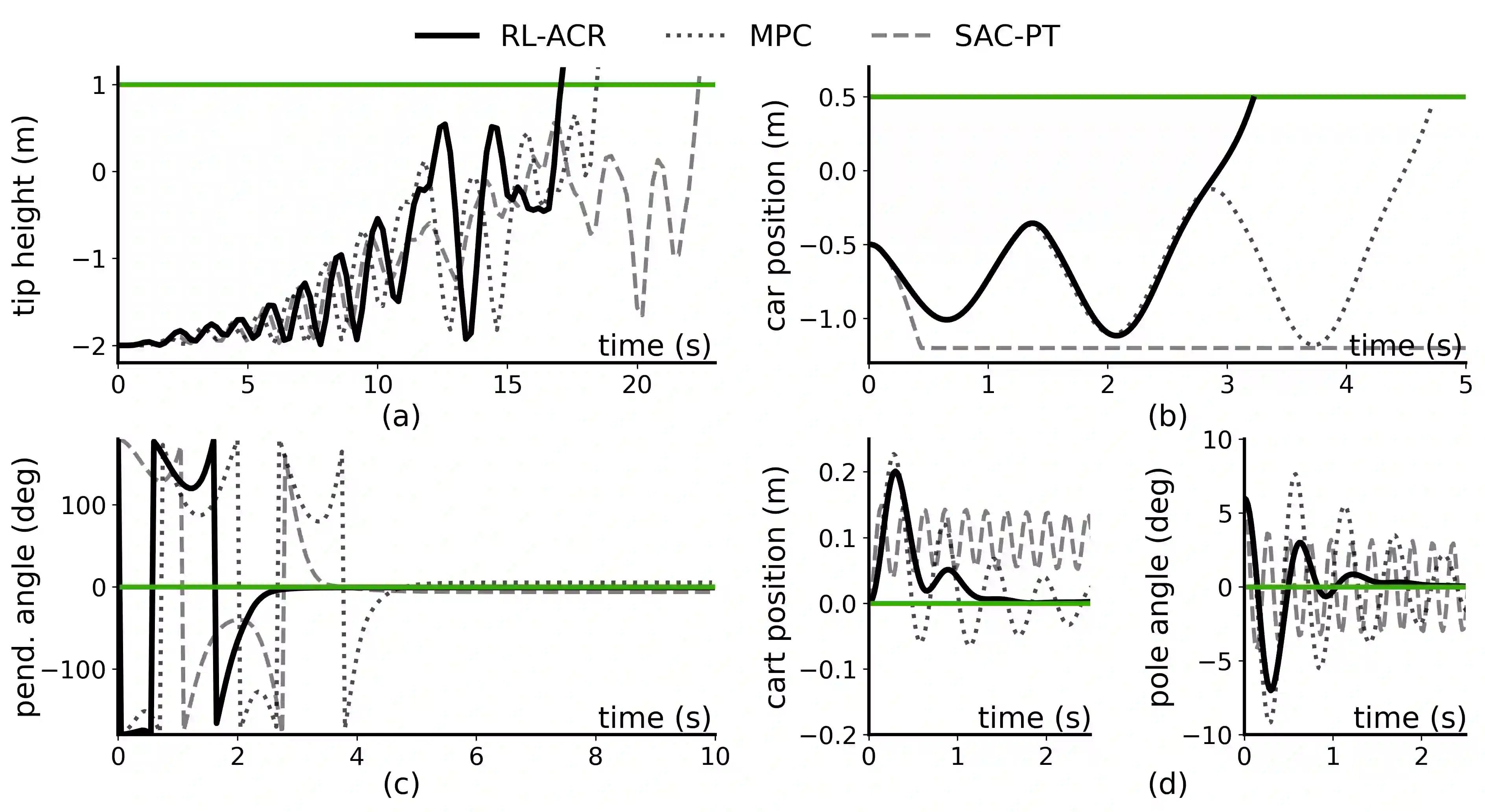
Reinforcement Learning (RL) is a powerful method for controlling dynamic systems, but its learning mechanism can lead to unpredictable actions that undermine the safety of critical systems. Here, we propose RL with Adaptive Control Regularization (RL-ACR) that ensures RL safety by combining the RL policy with a control regularizer that hard-codes safety constraints over forecasted system behaviors. The adaptability is achieved by using a learnable "focus" weight trained to maximize the cumulative reward of the policy combination. As the RL policy improves through off-policy learning, the focus weight improves the initial sub-optimum strategy by gradually relying more on the RL policy. We demonstrate the effectiveness of RL-ACR in a critical medical control application and further investigate its performance in four classic control environments.
翻译:强化学习是控制动态系统的强有力方法,但其学习机制可能导致不可预测的动作,进而危及关键系统的安全性。本文提出了一种带自适应控制正则化的强化学习(RL-ACR)方法,通过将强化学习策略与硬编码安全约束的控制正则化器相结合,对系统行为的预测进行安全约束,从而确保强化学习的安全性。自适应能力通过一个可学习的“焦点”权重实现,该权重训练目标是最大化策略组合的累积奖励。随着强化学习策略通过离策略学习逐步优化,焦点权重能够逐渐更多地依赖强化学习策略,从而改善初始的次优策略。我们在关键医疗控制应用中验证了RL-ACR的有效性,并进一步在四个经典控制环境中探究了其性能表现。