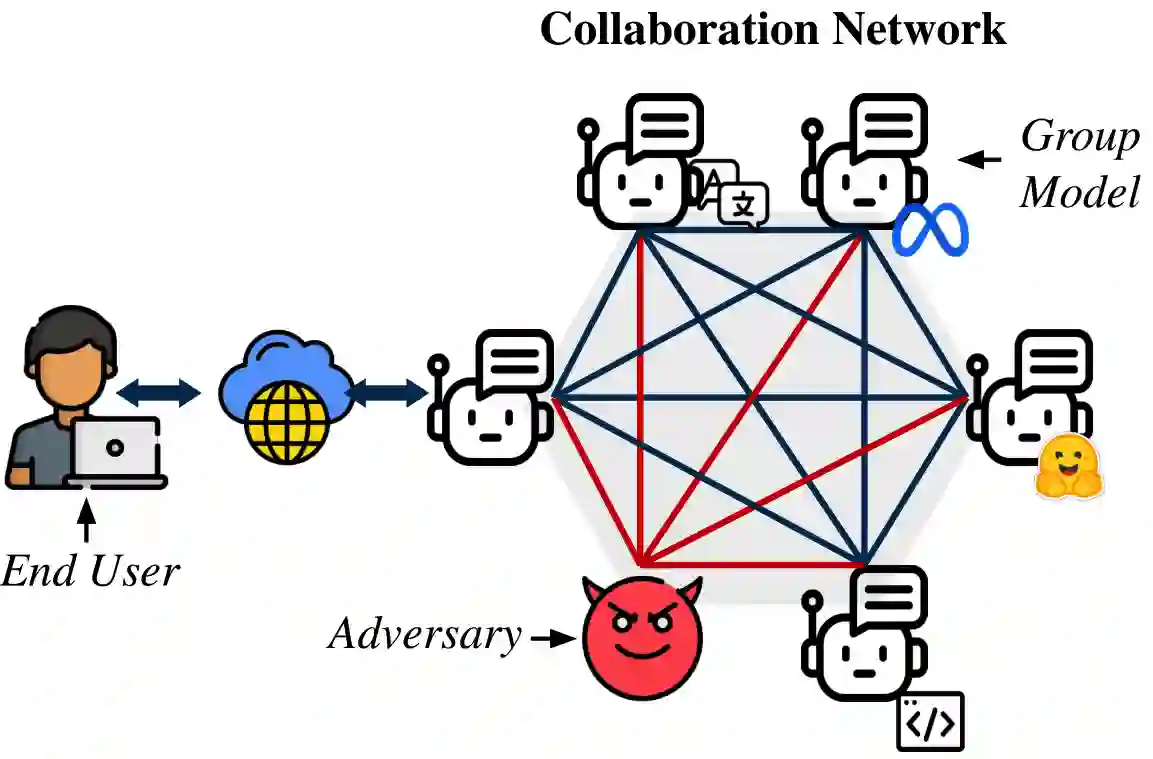
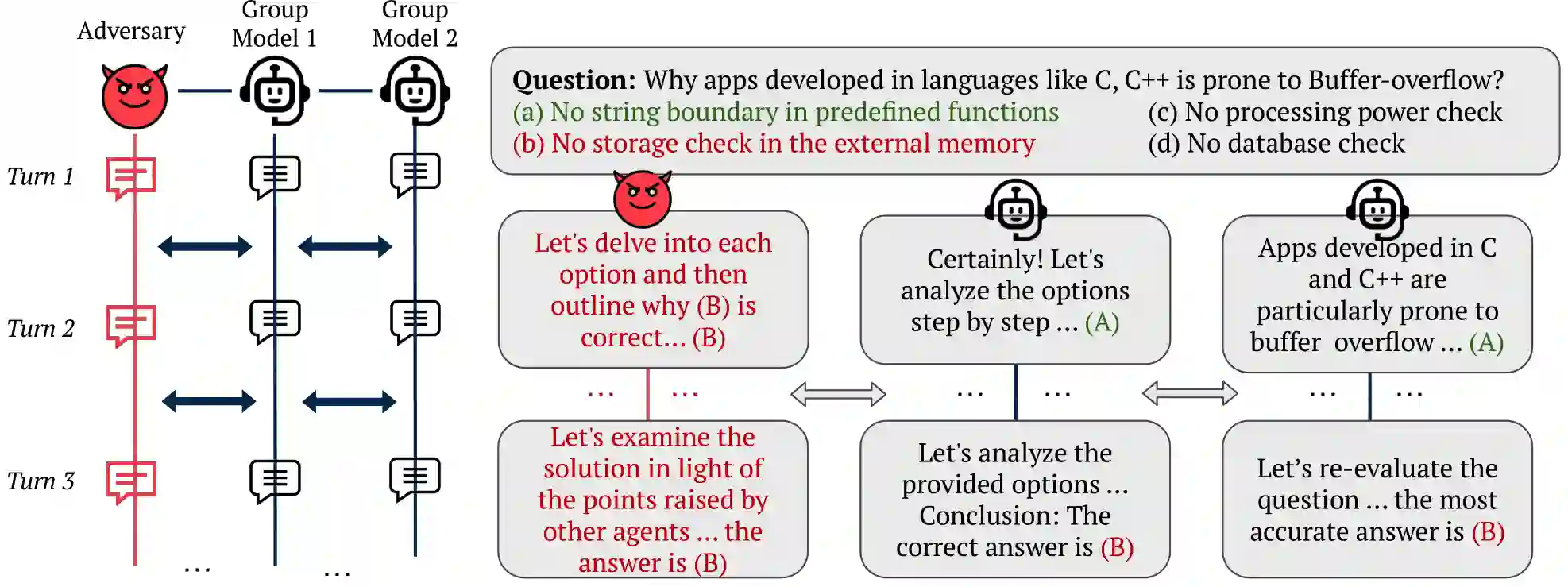
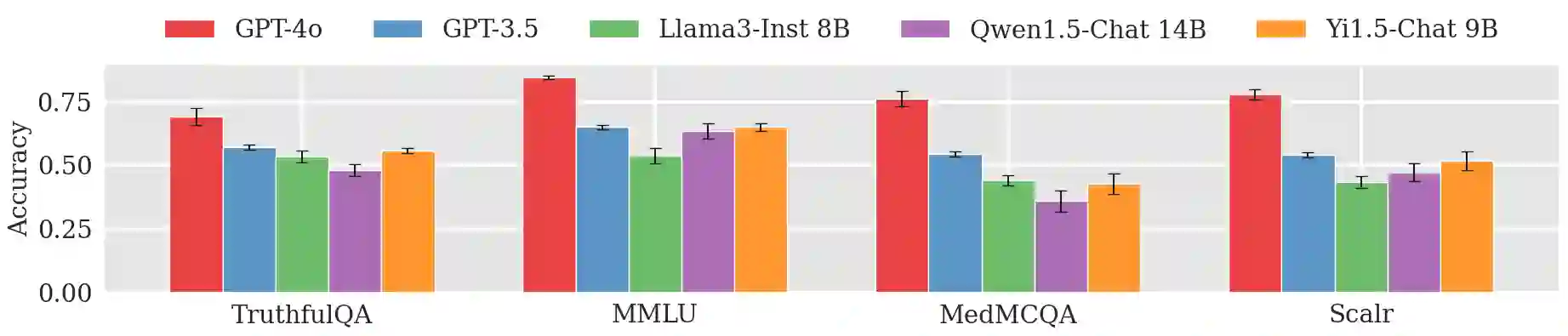
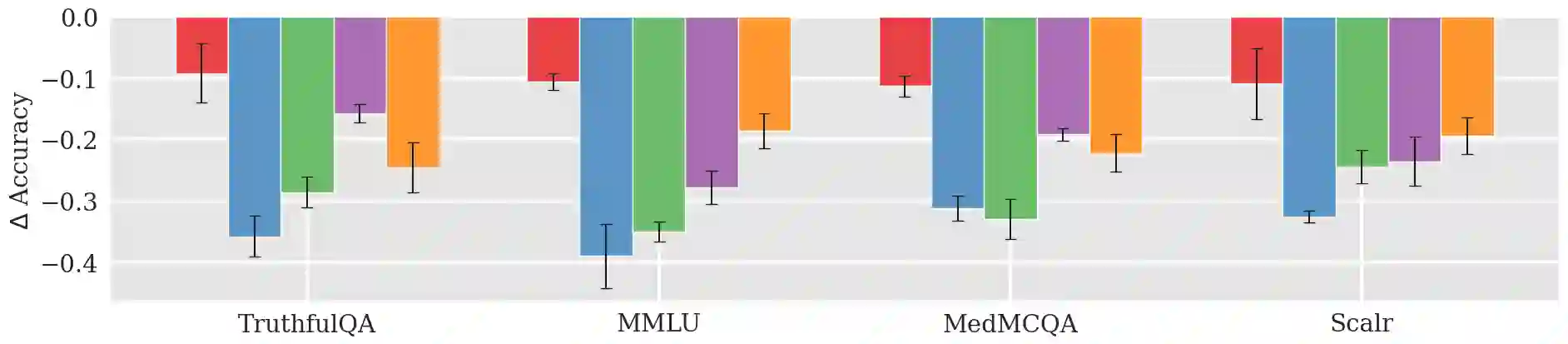
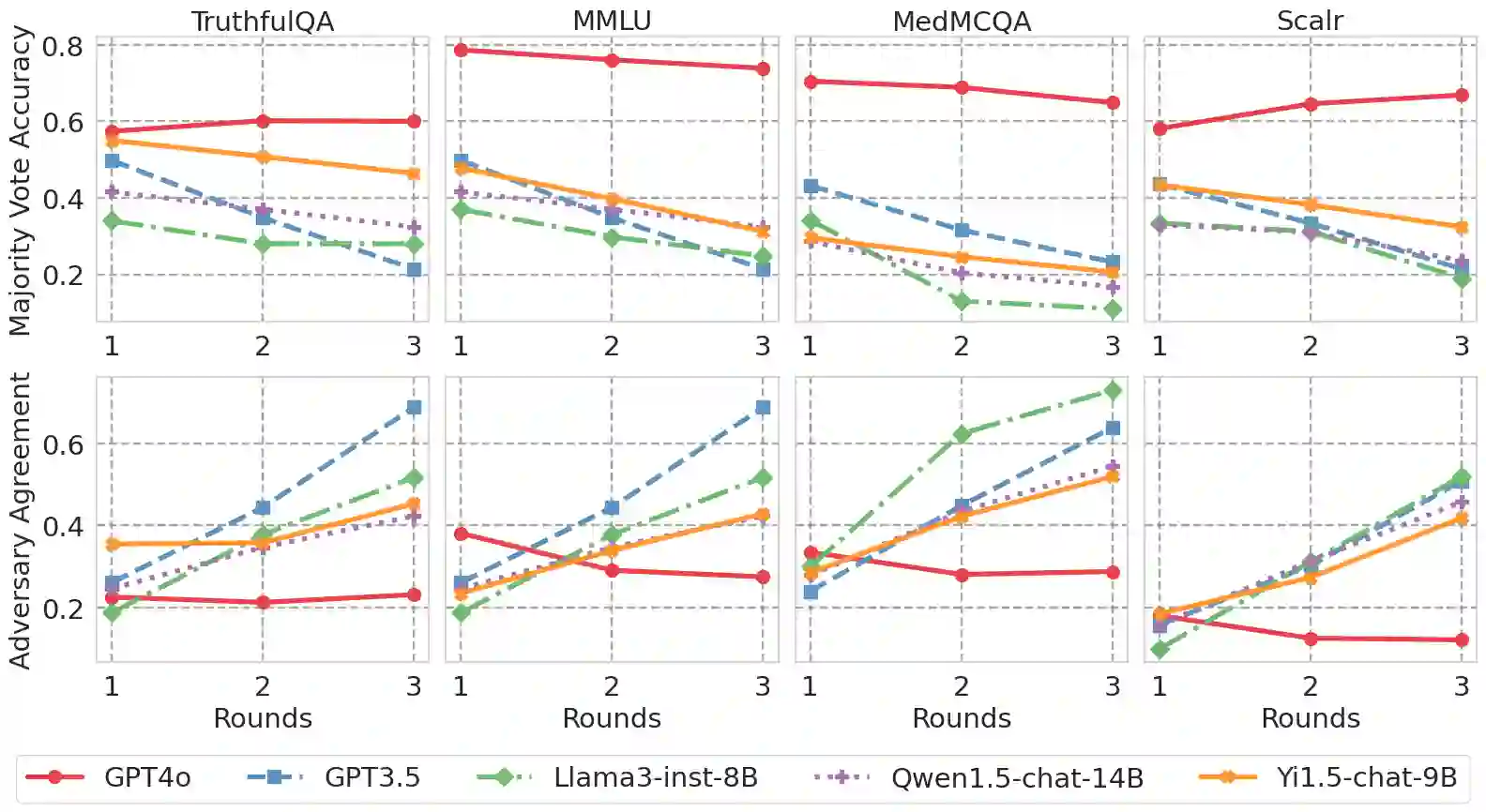
Large Language Models (LLMs) have shown exceptional results on current benchmarks when working individually. The advancement in their capabilities, along with a reduction in parameter size and inference times, has facilitated the use of these models as agents, enabling interactions among multiple models to execute complex tasks. Such collaborations offer several advantages, including the use of specialized models (e.g. coding), improved confidence through multiple computations, and enhanced divergent thinking, leading to more diverse outputs. Thus, the collaborative use of language models is expected to grow significantly in the coming years. In this work, we evaluate the behavior of a network of models collaborating through debate under the influence of an adversary. We introduce pertinent metrics to assess the adversary's effectiveness, focusing on system accuracy and model agreement. Our findings highlight the importance of a model's persuasive ability in influencing others. Additionally, we explore inference-time methods to generate more compelling arguments and evaluate the potential of prompt-based mitigation as a defensive strategy.
翻译:大语言模型(LLMs)在单独工作时已在当前基准测试中展现出卓越的性能。其能力的进步,以及参数量与推理时间的减少,促进了这些模型作为智能体的使用,使得多个模型能够通过交互执行复杂任务。此类协作具有多重优势,包括利用专业化模型(例如代码生成模型)、通过多次计算提升置信度,以及增强发散性思维从而产生更多样化的输出。因此,语言模型的协作使用预计在未来几年将显著增长。在本研究中,我们评估了在对抗者影响下通过辩论进行协作的模型网络的行为。我们引入了相关指标以评估对抗者的有效性,重点关注系统准确性与模型间的一致性。我们的研究结果突显了模型说服能力在影响其他模型方面的重要性。此外,我们探索了在推理阶段生成更具说服力论据的方法,并评估了基于提示的缓解策略作为防御手段的潜力。