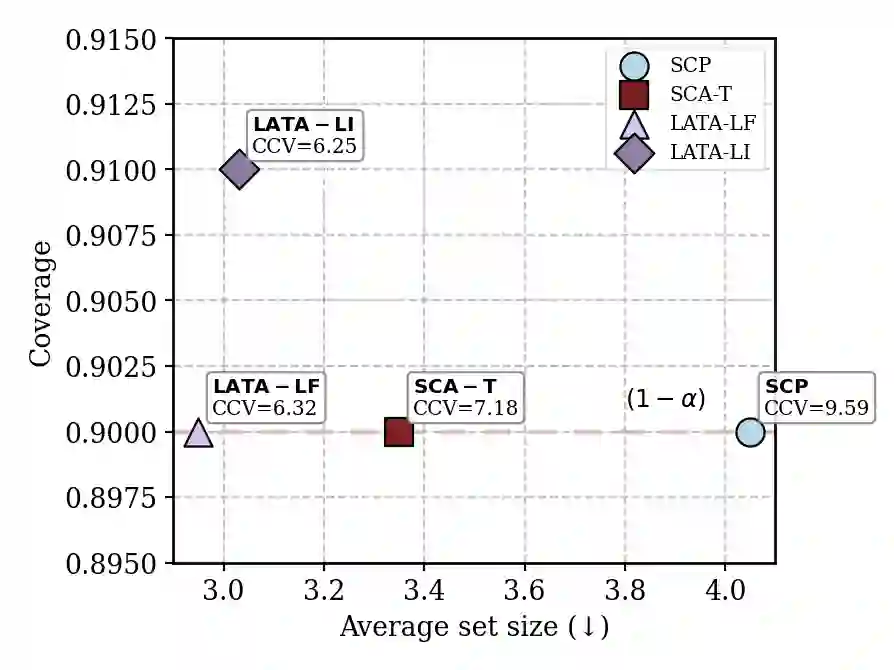
Medical vision-language models (VLMs) are strong zero-shot recognizers for medical imaging, but their reliability under domain shift hinges on calibrated uncertainty with guarantees. Split conformal prediction (SCP) offers finite-sample coverage, yet prediction sets often become large (low efficiency) and class-wise coverage unbalanced-high class-conditioned coverage gap (CCV), especially in few-shot, imbalanced regimes; moreover, naively adapting to calibration labels breaks exchangeability and voids guarantees. We propose \texttt{\textbf{LATA}} (Laplacian-Assisted Transductive Adaptation), a \textit{training- and label-free} refinement that operates on the joint calibration and test pool by smoothing zero-shot probabilities over an image-image k-NN graph using a small number of CCCP mean-field updates, preserving SCP validity via a deterministic transform. We further introduce a \textit{failure-aware} conformal score that plugs into the vision-language uncertainty (ViLU) framework, providing instance-level difficulty and label plausibility to improve prediction set efficiency and class-wise balance at fixed coverage. \texttt{\textbf{LATA}} is black-box (no VLM updates), compute-light (windowed transduction, no backprop), and includes an optional prior knob that can run strictly label-free or, if desired, in a label-informed variant using calibration marginals once. Across \textbf{three} medical VLMs and \textbf{nine} downstream tasks, \texttt{\textbf{LATA}} consistently reduces set size and CCV while matching or tightening target coverage, outperforming prior transductive baselines and narrowing the gap to label-using methods, while using far less compute. Comprehensive ablations and qualitative analyses show that \texttt{\textbf{LATA}} sharpens zero-shot predictions without compromising exchangeability.
翻译:医学视觉语言模型(VLMs)是医学影像领域强大的零样本识别器,但其在领域偏移下的可靠性依赖于具有保证的校准不确定性。分割保形预测(SCP)提供了有限样本覆盖保证,但预测集通常变得过大(效率低下)且类别间覆盖不平衡——存在较高的类别条件覆盖差距(CCV),尤其在少样本、不平衡场景下;此外,直接适应校准标签会破坏可交换性并使保证失效。我们提出 \texttt{\textbf{LATA}}(拉普拉斯辅助转导适应),这是一种\textit{无需训练和标签}的优化方法,它通过少量CCCP平均场更新在图像-图像k近邻图上平滑零样本概率,对联合校准池和测试池进行操作,并通过确定性变换保持SCP的有效性。我们进一步引入一种\textit{失败感知}保形评分,可嵌入视觉语言不确定性(ViLU)框架,提供实例级难度和标签合理性,以在固定覆盖水平下提高预测集效率和类别间平衡。\texttt{\textbf{LATA}}是黑盒方法(无需更新VLM)、计算轻量(窗口化转导,无需反向传播),并包含一个可选的先验调节旋钮,可以严格在无标签模式下运行,或者如果需要,也可使用一次校准边缘分布以标签知情变体运行。在\textbf{三个}医学VLM和\textbf{九个}下游任务中,\texttt{\textbf{LATA}}持续减小集合大小和CCV,同时匹配或收紧目标覆盖,优于先前的转导基线,并缩小了与使用标签方法的差距,同时计算量远少于后者。全面的消融实验和定性分析表明,\texttt{\textbf{LATA}}在不损害可交换性的前提下锐化了零样本预测。