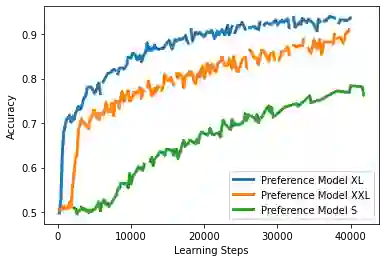
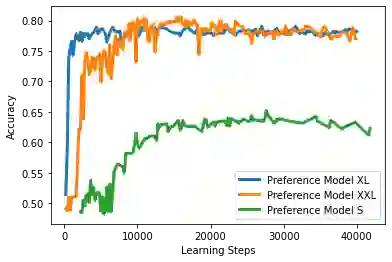
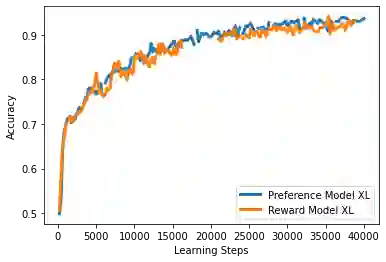
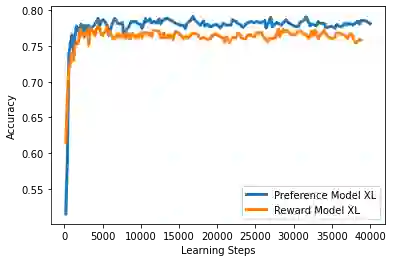
Reinforcement learning from human feedback (RLHF) has emerged as the main paradigm for aligning large language models (LLMs) with human preferences. Typically, RLHF involves the initial step of learning a reward model from human feedback, often expressed as preferences between pairs of text generations produced by a pre-trained LLM. Subsequently, the LLM's policy is fine-tuned by optimizing it to maximize the reward model through a reinforcement learning algorithm. However, an inherent limitation of current reward models is their inability to fully represent the richness of human preferences and their dependency on the sampling distribution. In this study, we introduce an alternative pipeline for the fine-tuning of LLMs using pairwise human feedback. Our approach entails the initial learning of a preference model, which is conditioned on two inputs given a prompt, followed by the pursuit of a policy that consistently generates responses preferred over those generated by any competing policy, thus defining the Nash equilibrium of this preference model. We term this approach Nash learning from human feedback (NLHF). In the context of a tabular policy representation, we present a novel algorithmic solution, Nash-MD, founded on the principles of mirror descent. This algorithm produces a sequence of policies, with the last iteration converging to the regularized Nash equilibrium. Additionally, we explore parametric representations of policies and introduce gradient descent algorithms for deep-learning architectures. To demonstrate the effectiveness of our approach, we present experimental results involving the fine-tuning of a LLM for a text summarization task. We believe NLHF offers a compelling avenue for preference learning and policy optimization with the potential of advancing the field of aligning LLMs with human preferences.
翻译:基于人类反馈的强化学习(RLHF)已成为将大型语言模型(LLMs)与人类偏好对齐的主流范式。通常,RLHF首先从人类反馈(通常表现为预训练LLM生成的文本对之间的偏好)中学习奖励模型,随后通过强化学习算法优化LLM的策略,使其最大化该奖励模型。然而,当前奖励模型存在固有局限性:无法完整表征人类偏好的丰富性,且其性能依赖于采样分布。本研究提出一种利用成对人类反馈微调LLM的替代方案。该方法首先学习一个基于给定提示、以两个输入为条件的偏好模型,随后寻求一种策略,使其生成的回答始终优于任何竞争策略生成的回答,从而定义该偏好模型的纳什均衡。我们将此方法称为"从人类反馈中学习纳什均衡"(NLHF)。针对表格策略表示形式,我们提出了一种基于镜像下降原理的新型算法解决方案——Nash-MD。该算法生成策略序列,其最终迭代收敛至正则化纳什均衡。此外,我们探究了策略的参数化表示,并引入了适用于深度学习架构的梯度下降算法。为展示方法的有效性,我们提供了针对文本摘要任务微调LLM的实验结果。我们相信NLHF为偏好学习与策略优化提供了富有前景的新途径,有望推动LLM与人类偏好对齐领域的发展。