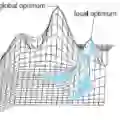
*Relative overgeneralization* (RO) occurs in cooperative multi-agent learning tasks when agents converge towards a suboptimal joint policy due to overfitting to suboptimal behavior of other agents. No methods have been proposed for addressing RO in multi-agent policy gradient (MAPG) methods although these methods produce state-of-the-art results. To address this gap, we propose a general, yet simple, framework to enable optimistic updates in MAPG methods that alleviate the RO problem. Our approach involves clipping the advantage to eliminate negative values, thereby facilitating optimistic updates in MAPG. The optimism prevents individual agents from quickly converging to a local optimum. Additionally, we provide a formal analysis to show that the proposed method retains optimality at a fixed point. In extensive evaluations on a diverse set of tasks including the *Multi-agent MuJoCo* and *Overcooked* benchmarks, our method outperforms strong baselines on 13 out of 19 tested tasks and matches the performance on the rest.
翻译:*相对过度泛化*(RO)问题出现在合作式多智能体学习任务中,当智能体因过度适应其他智能体的次优行为而收敛至次优联合策略时即发生此现象。尽管多智能体策略梯度(MAPG)方法能够取得最先进的结果,但目前尚未有针对MAPG方法解决RO问题的方案。为填补这一空白,我们提出了一个通用且简洁的框架,使MAPG方法能够执行乐观更新以缓解RO问题。我们的方法通过对优势函数进行截断以消除负值,从而促进MAPG中的乐观更新。这种乐观性防止了个体智能体快速收敛至局部最优解。此外,我们提供了形式化分析,证明所提方法在不动点处保持最优性。在包括*多智能体MuJoCo*和*Overcooked*基准测试在内的多样化任务集上进行广泛评估后,我们的方法在19个测试任务中的13个上超越了强基线模型,并在其余任务上取得了与之相当的性能。