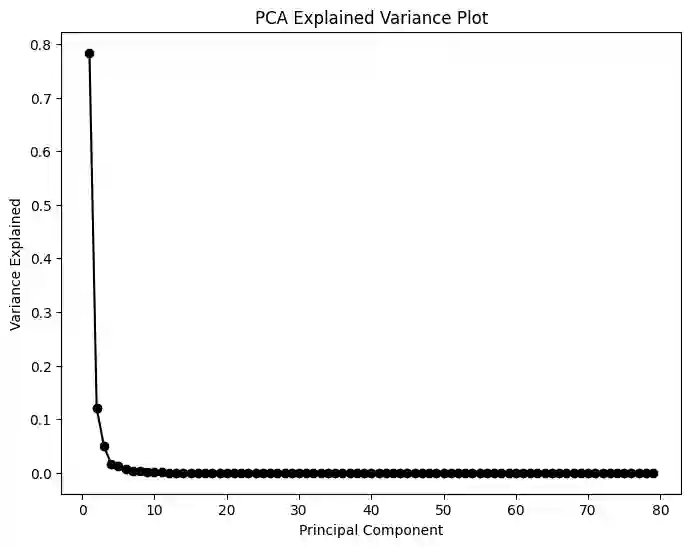
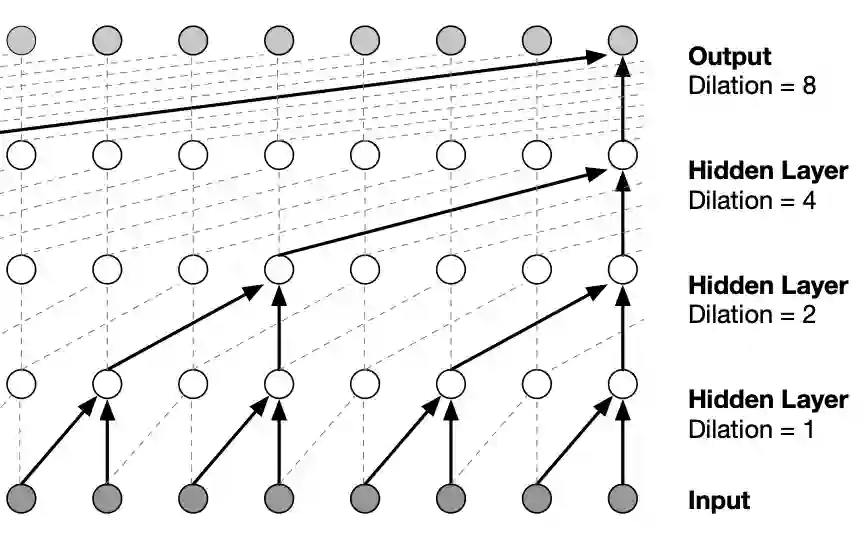
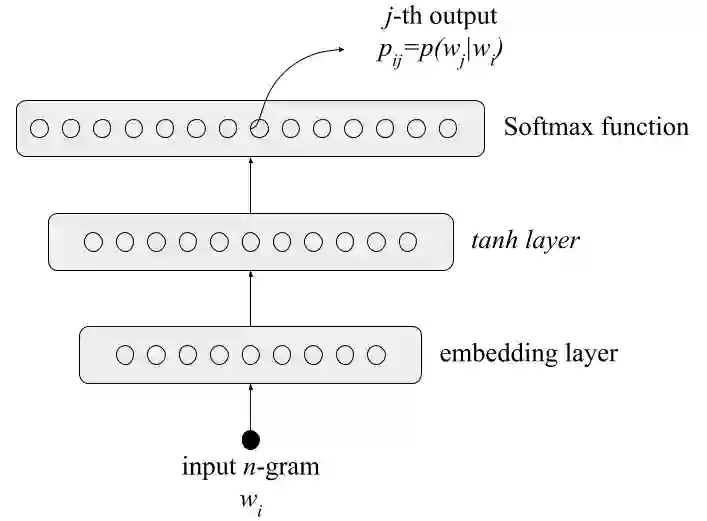
Artificial Intelligence (AI) research often aims to develop models that can generalize reliably across complex datasets, yet this remains challenging in fields where data is scarce, intricate, or inaccessible. This paper introduces a novel approach that leverages three generative models of varying complexity to synthesize one of the most demanding structured datasets: Malicious Network Traffic. Our approach uniquely transforms numerical data into text, re-framing data generation as a language modeling task, which not only enhances data regularization but also significantly improves generalization and the quality of the synthetic data. Extensive statistical analyses demonstrate that our method surpasses state-of-the-art generative models in producing high-fidelity synthetic data. Additionally, we conduct a comprehensive study on synthetic data applications, effectiveness, and evaluation strategies, offering valuable insights into its role across various domains. Our code and pre-trained models are openly accessible at Github, enabling further exploration and application of our methodology. Index Terms: Data synthesis, machine learning, traffic generation, privacy preserving data, generative models.
翻译:人工智能(AI)研究常致力于开发能够在复杂数据集上可靠泛化的模型,然而在数据稀缺、结构复杂或难以获取的领域,这仍具挑战性。本文提出了一种新颖方法,利用三种不同复杂度的生成模型来合成最具挑战性的结构化数据集之一:恶意网络流量。该方法创新性地将数值数据转换为文本,将数据生成任务重新定义为语言建模任务,这不仅增强了数据正则化,还显著提升了泛化能力和合成数据的质量。广泛的统计分析表明,我们的方法在生成高保真合成数据方面超越了当前最先进的生成模型。此外,我们对合成数据的应用、有效性及评估策略进行了全面研究,为跨领域应用提供了有价值的见解。我们的代码与预训练模型已在GitHub上开源,以便进一步探索和应用本方法。索引术语:数据合成,机器学习,流量生成,隐私保护数据,生成模型。