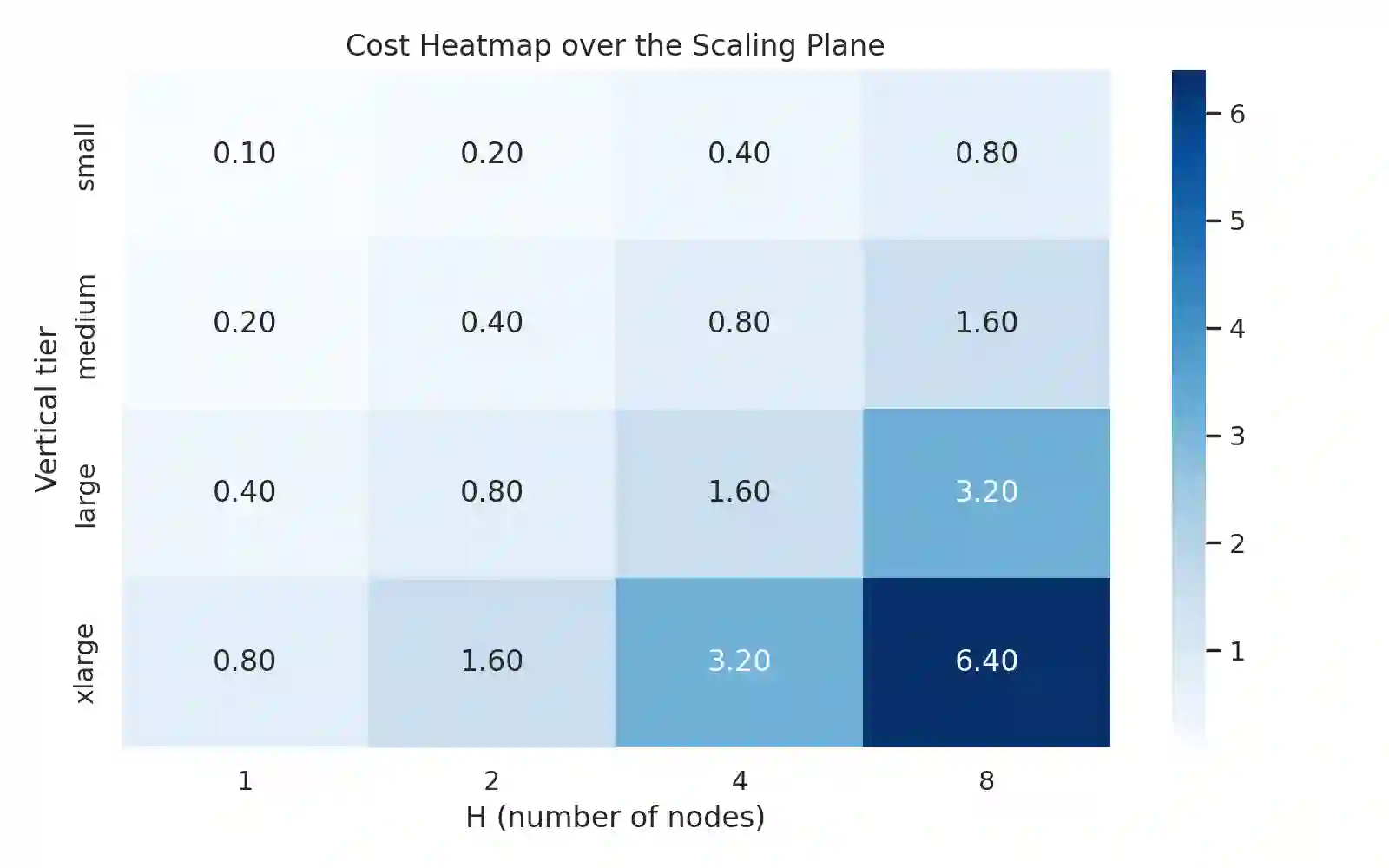
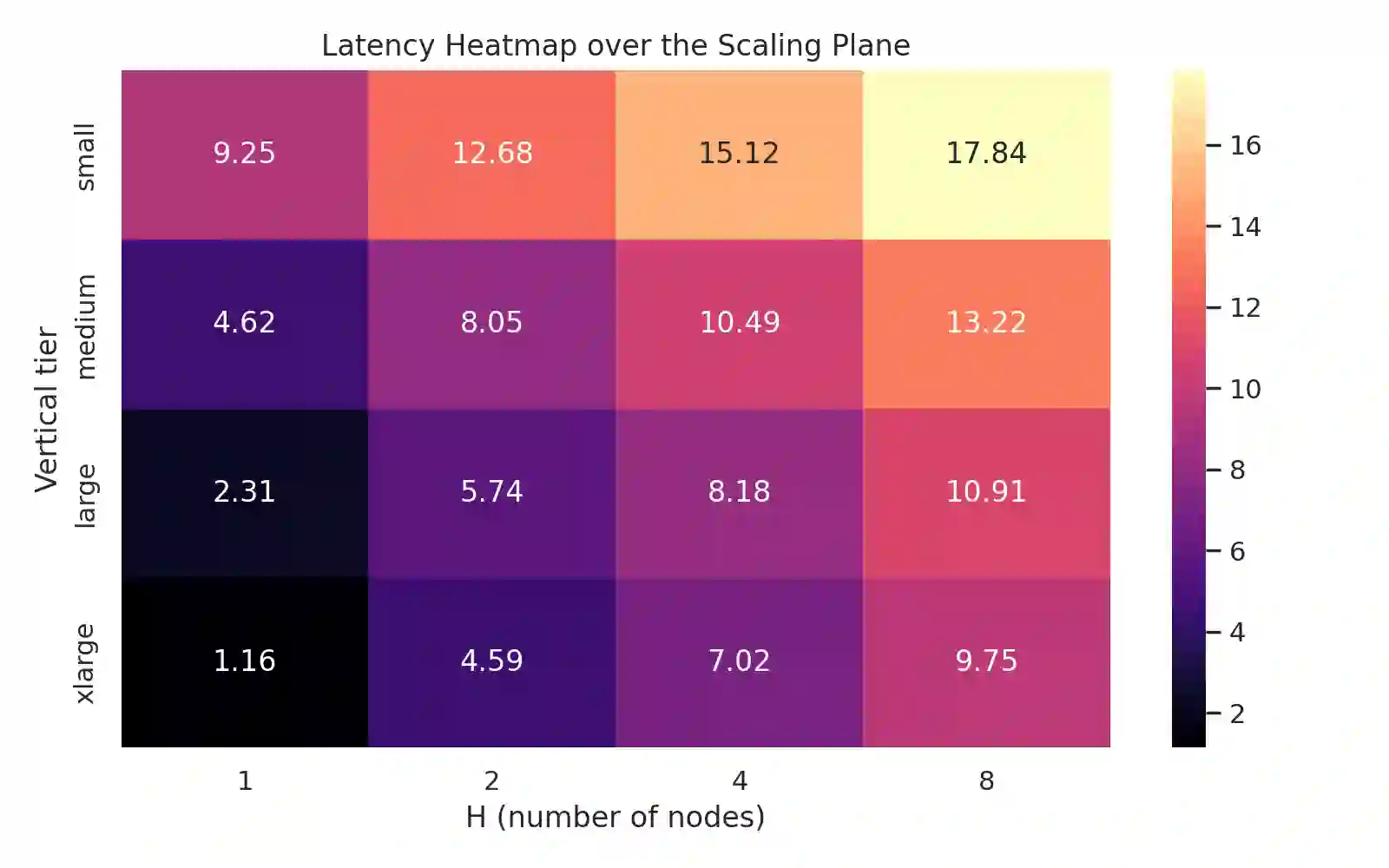
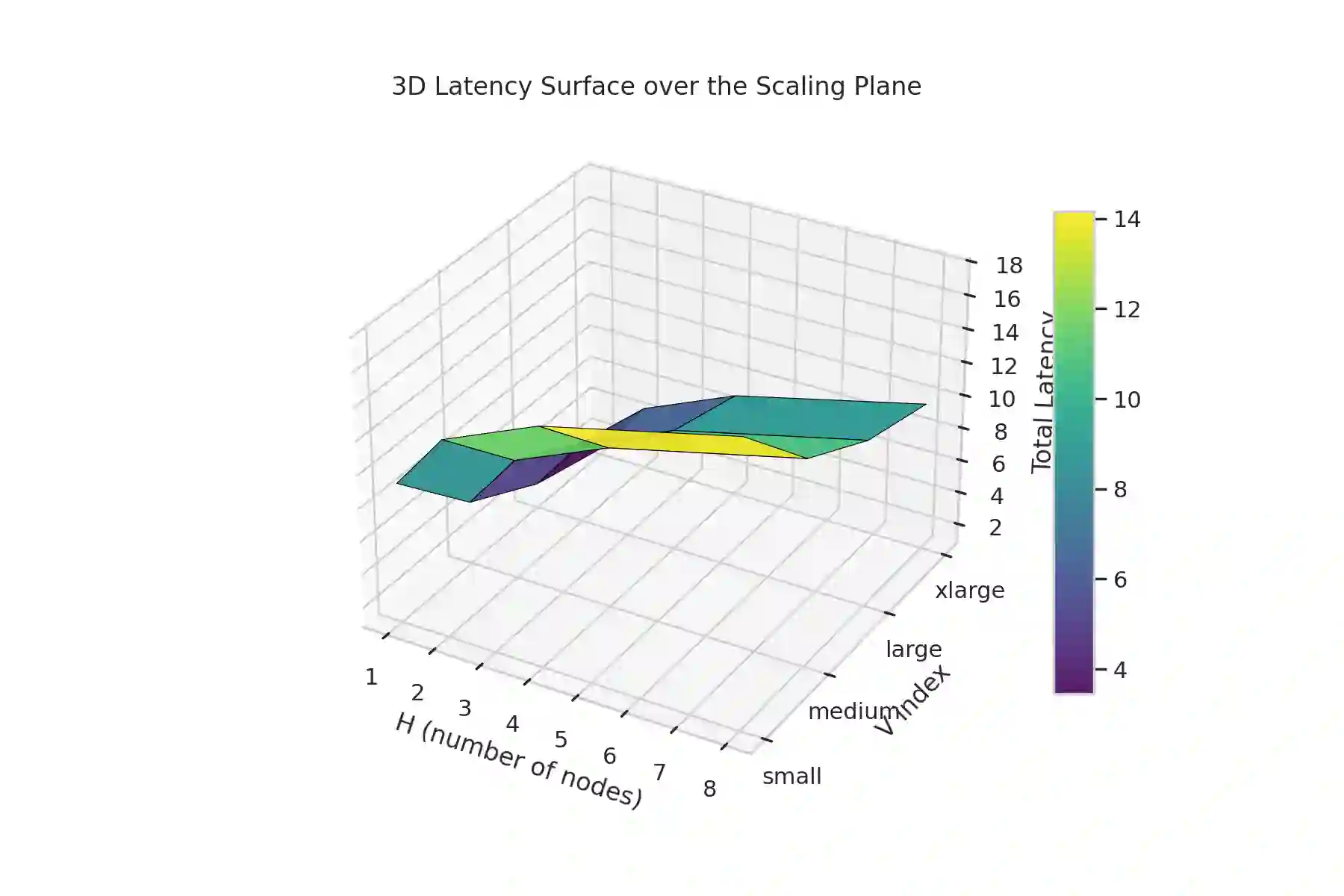
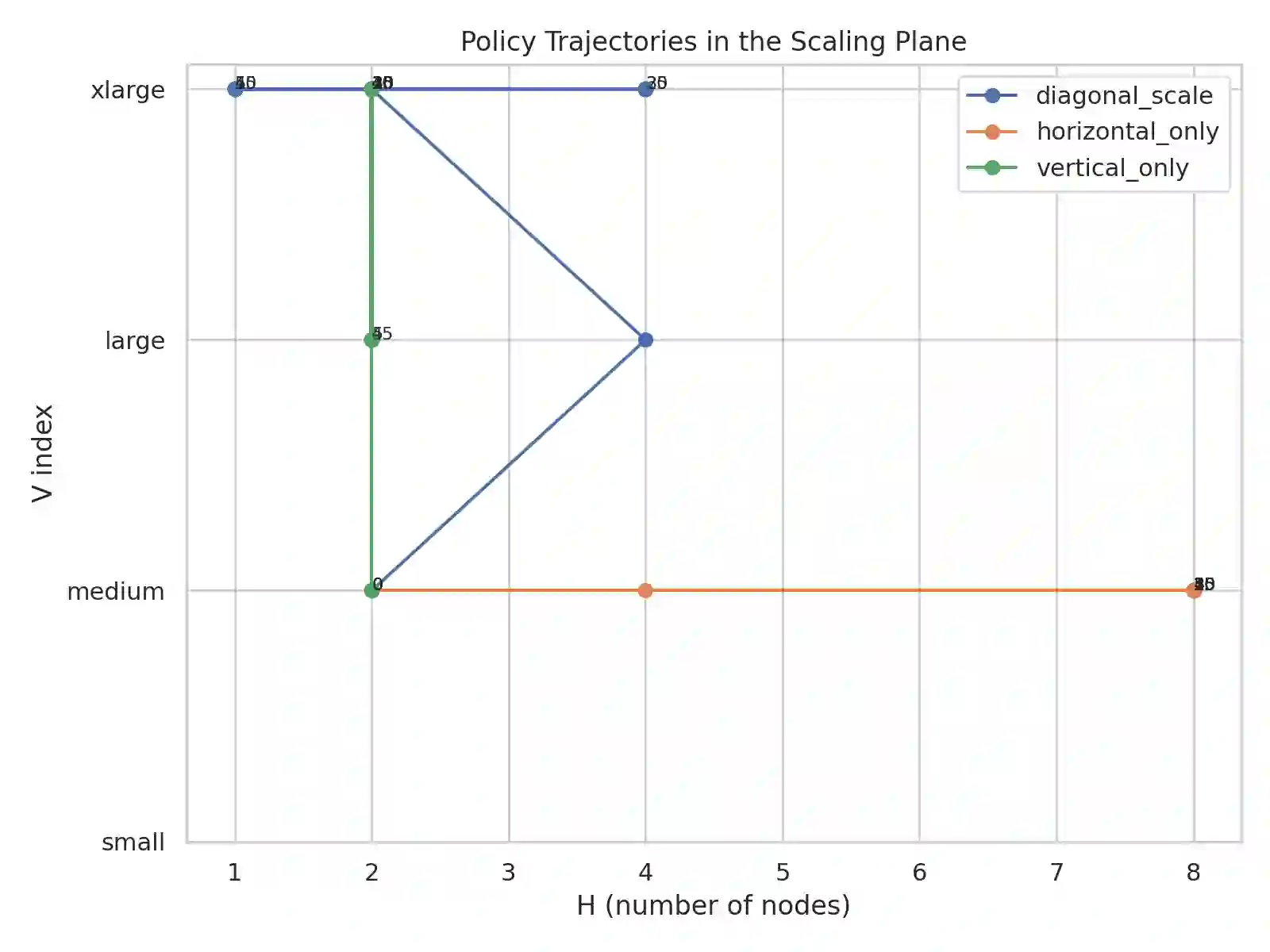
Modern cloud databases present scaling as a binary decision: scale-out by adding nodes or scale-up by increasing per-node resources. This one-dimensional view is limiting because database performance, cost, and coordination overhead emerge from the joint interaction of horizontal elasticity and per-node CPU, memory, network bandwidth, and storage IOPS. As a result, systems often overreact to load spikes, underreact to memory pressure, or oscillate between suboptimal states. We introduce the Scaling Plane, a two-dimensional model in which each distributed database configuration is represented as a point (H, V), with H denoting node count and V a vector of resources. Over this plane, we define smooth approximations of latency, throughput, coordination overhead, and monetary cost, providing a unified view of performance trade-offs. We show analytically and empirically that optimal scaling trajectories frequently lie along diagonal paths: sequences of joint horizontal and vertical adjustments that simultaneously exploit cluster parallelism and per-node improvements. To compute such actions, we propose DIAGONALSCALE, a discrete local-search algorithm that evaluates horizontal, vertical, and diagonal moves in the Scaling Plane and selects the configuration minimizing a multi-objective function subject to SLA constraints. Using synthetic surfaces, microbenchmarks, and experiments on distributed SQL and KV systems, we demonstrate that diagonal scaling reduces p95 latency by up to 40 percent, lowers cost-per-query by up to 37 percent, and reduces rebalancing by 2 to 5 times compared to horizontal-only and vertical-only autoscaling. Our results highlight the need for multi-dimensional scaling models and provide a foundation for next-generation autoscaling in cloud database systems.
翻译:现代云数据库将弹性伸缩视为一种二元决策:通过添加节点进行水平扩展,或通过增加每节点资源进行垂直扩展。这种一维视角具有局限性,因为数据库性能、成本和协调开销是由水平弹性与每节点CPU、内存、网络带宽及存储IOPS的联合交互共同决定的。因此,系统常对负载峰值反应过度,对内存压力反应不足,或在次优状态间振荡。我们提出缩放平面这一二维模型,其中每个分布式数据库配置表示为点(H, V),H表示节点数量,V表示资源向量。在此平面上,我们定义了延迟、吞吐量、协调开销和货币成本的平滑近似函数,提供性能权衡的统一视图。我们通过分析和实验证明,最优缩放轨迹通常沿对角路径:即同时利用集群并行性和每节点优化的联合水平与垂直调整序列。为计算此类操作,我们提出DIAGONALSCALE算法,这是一种离散局部搜索算法,在缩放平面中评估水平、垂直和对角移动,并选择在满足SLA约束条件下最小化多目标函数的配置。通过合成曲面、微基准测试以及在分布式SQL和KV系统上的实验,我们证明与仅水平或仅垂直的自动缩放相比,对角缩放将p95延迟降低高达40%,每次查询成本降低高达37%,并将重平衡次数减少2至5倍。我们的研究结果凸显了多维缩放模型的必要性,并为云数据库系统中下一代自动缩放奠定了基础。