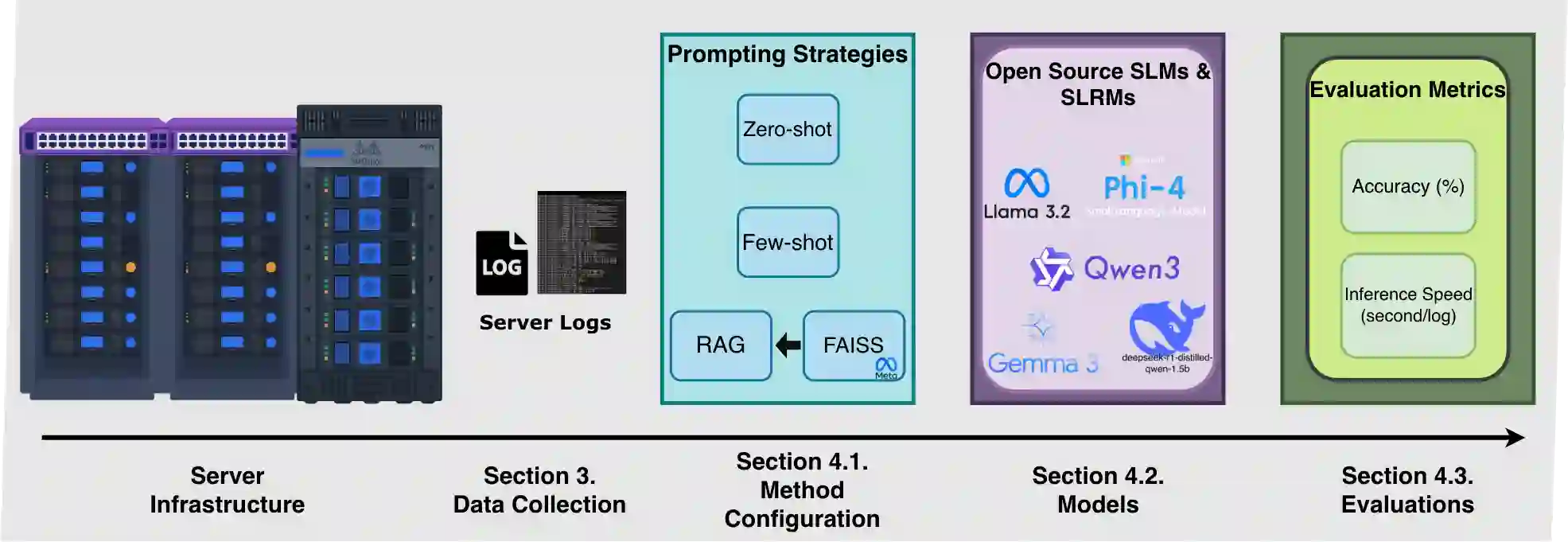
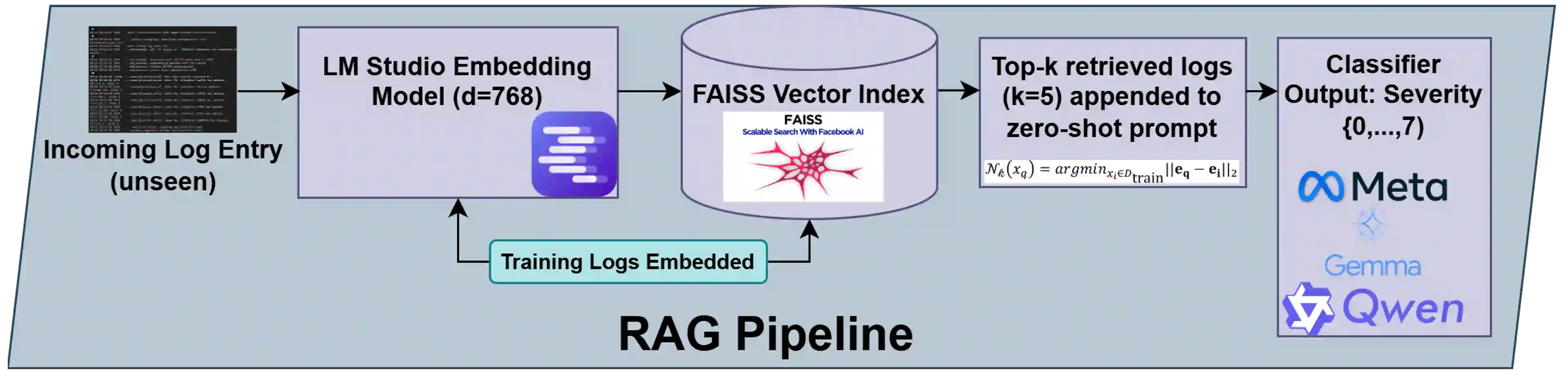
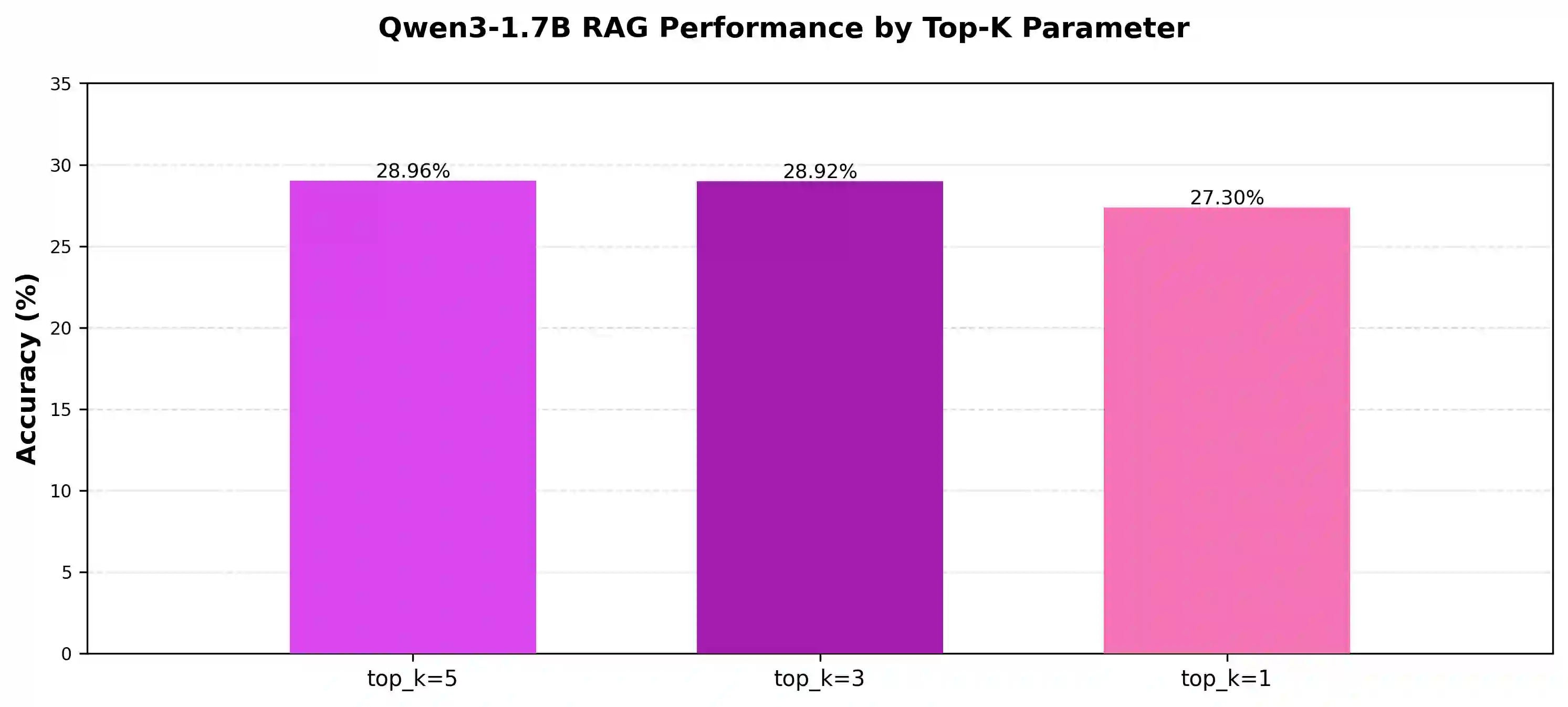
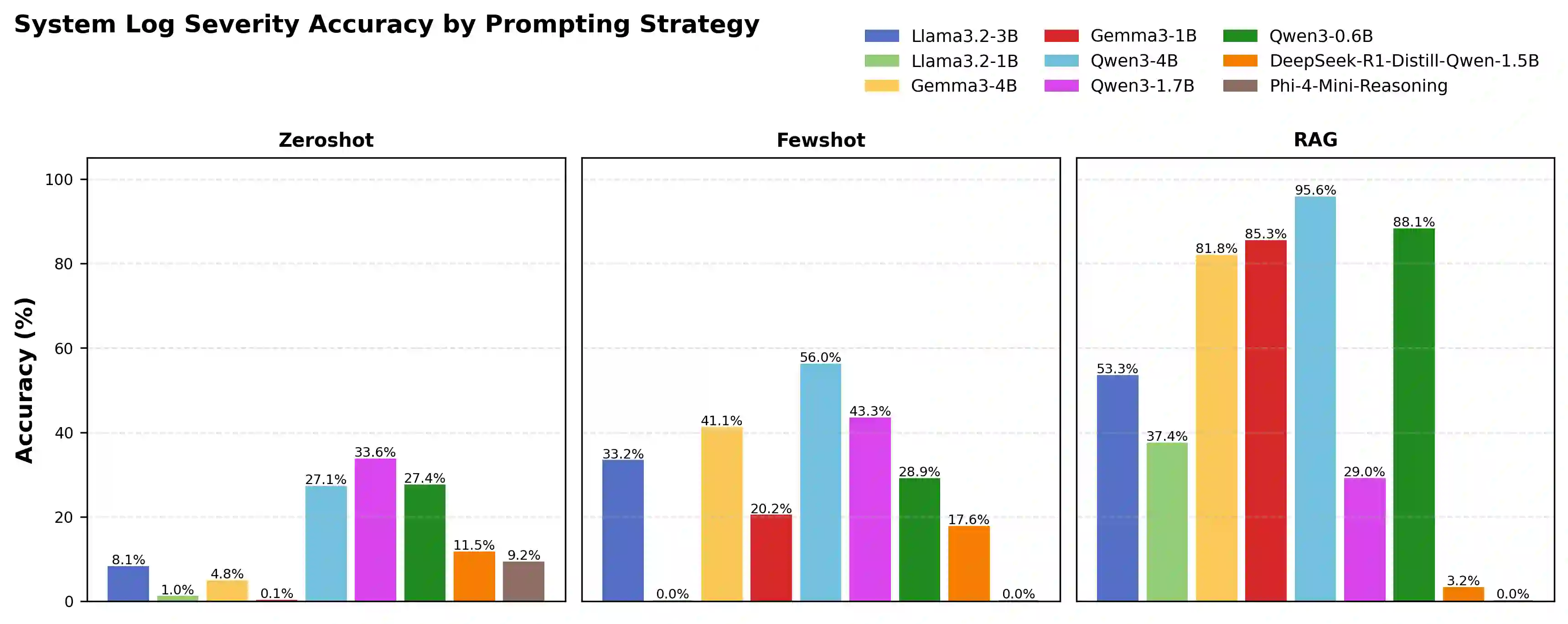
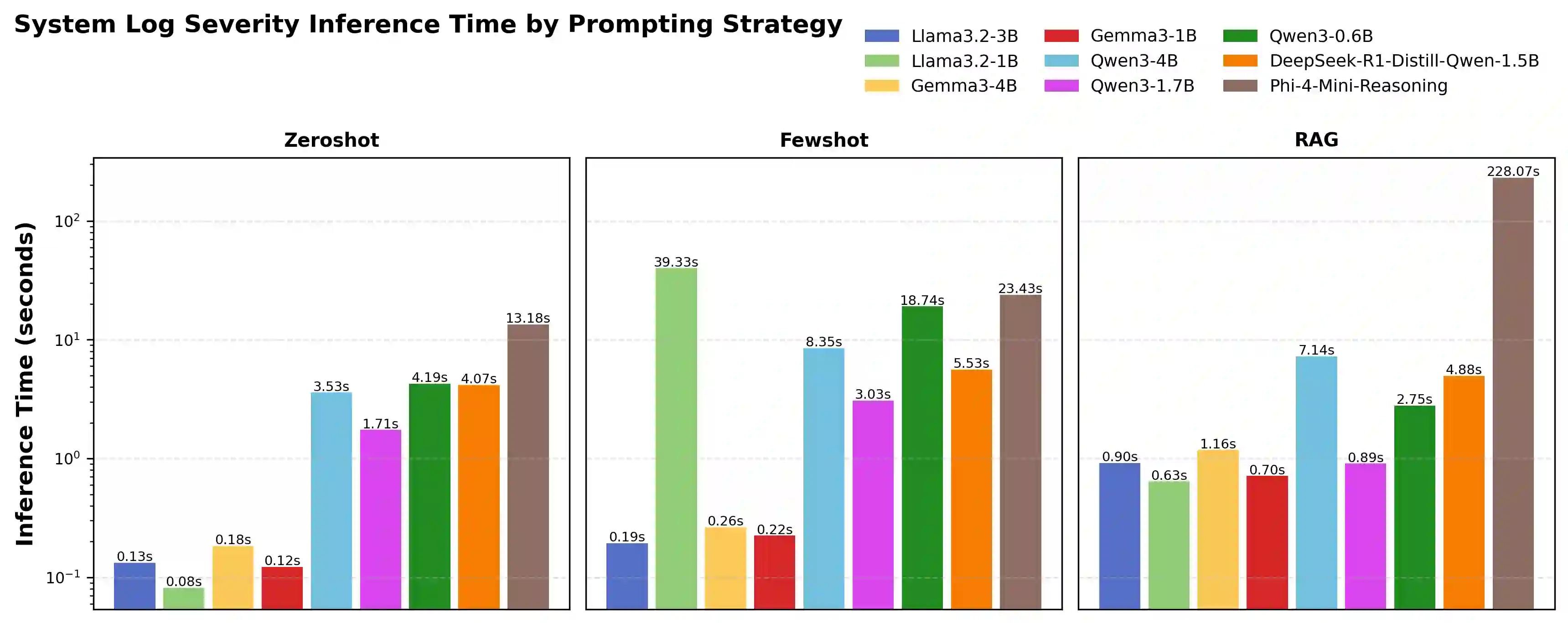
System logs are crucial for monitoring and diagnosing modern computing infrastructure, but their scale and complexity require reliable and efficient automated interpretation. Since severity levels are predefined metadata in system log messages, having a model merely classify them offers limited standalone practical value, revealing little about its underlying ability to interpret system logs. We argue that severity classification is more informative when treated as a benchmark for probing runtime log comprehension rather than as an end task. Using real-world journalctl data from Linux production servers, we evaluate nine small language models (SLMs) and small reasoning language models (SRLMs) under zero-shot, few-shot, and retrieval-augmented generation (RAG) prompting. The results reveal strong stratification. Qwen3-4B achieves the highest accuracy at 95.64% with RAG, while Gemma3-1B improves from 20.25% under few-shot prompting to 85.28% with RAG. Notably, the tiny Qwen3-0.6B reaches 88.12% accuracy despite weak performance without retrieval. In contrast, several SRLMs, including Qwen3-1.7B and DeepSeek-R1-Distill-Qwen-1.5B, degrade substantially when paired with RAG. Efficiency measurements further separate models: most Gemma and Llama variants complete inference in under 1.2 seconds per log, whereas Phi-4-Mini-Reasoning exceeds 228 seconds per log while achieving <10% accuracy. These findings suggest that (1) architectural design, (2) training objectives, and (3) the ability to integrate retrieved context under strict output constraints jointly determine performance. By emphasizing small, deployable models, this benchmark aligns with real-time requirements of digital twin (DT) systems and shows that severity classification serves as a lens for evaluating model competence and real-time deployability, with implications for root cause analysis (RCA) and broader DT integration.
翻译:系统日志对于监控和诊断现代计算基础设施至关重要,但其规模和复杂性需要可靠且高效的自动化解读。由于严重性级别是系统日志消息中预定义的元数据,仅让模型对其进行分类提供的独立实用价值有限,难以揭示其解读系统日志的底层能力。我们认为,将严重性分类视为探究运行时日志理解能力的基准测试,而非最终任务,能提供更多信息。利用来自Linux生产服务器的真实journalctl数据,我们在零样本、少样本和检索增强生成(RAG)提示下评估了九种小型语言模型(SLM)和小型推理语言模型(SRLM)。结果显示出明显的分层现象。Qwen3-4B在RAG下达到最高准确率95.64%,而Gemma3-1B则从少样本提示下的20.25%提升至RAG下的85.28%。值得注意的是,微型的Qwen3-0.6B在没有检索时表现较弱,但仍达到了88.12%的准确率。相比之下,包括Qwen3-1.7B和DeepSeek-R1-Distill-Qwen-1.5B在内的几种SRLM在与RAG结合时性能大幅下降。效率测量进一步区分了模型:大多数Gemma和Llama变体在每条日志1.2秒内完成推理,而Phi-4-Mini-Reasoning每条日志耗时超过228秒,准确率却低于10%。这些发现表明:(1)架构设计,(2)训练目标,以及(3)在严格输出约束下整合检索上下文的能力共同决定了性能。通过强调小型、可部署模型,此基准测试符合数字孪生(DT)系统的实时性要求,并表明严重性分类可作为评估模型能力和实时可部署性的透镜,对根本原因分析(RCA)及更广泛的DT集成具有启示意义。