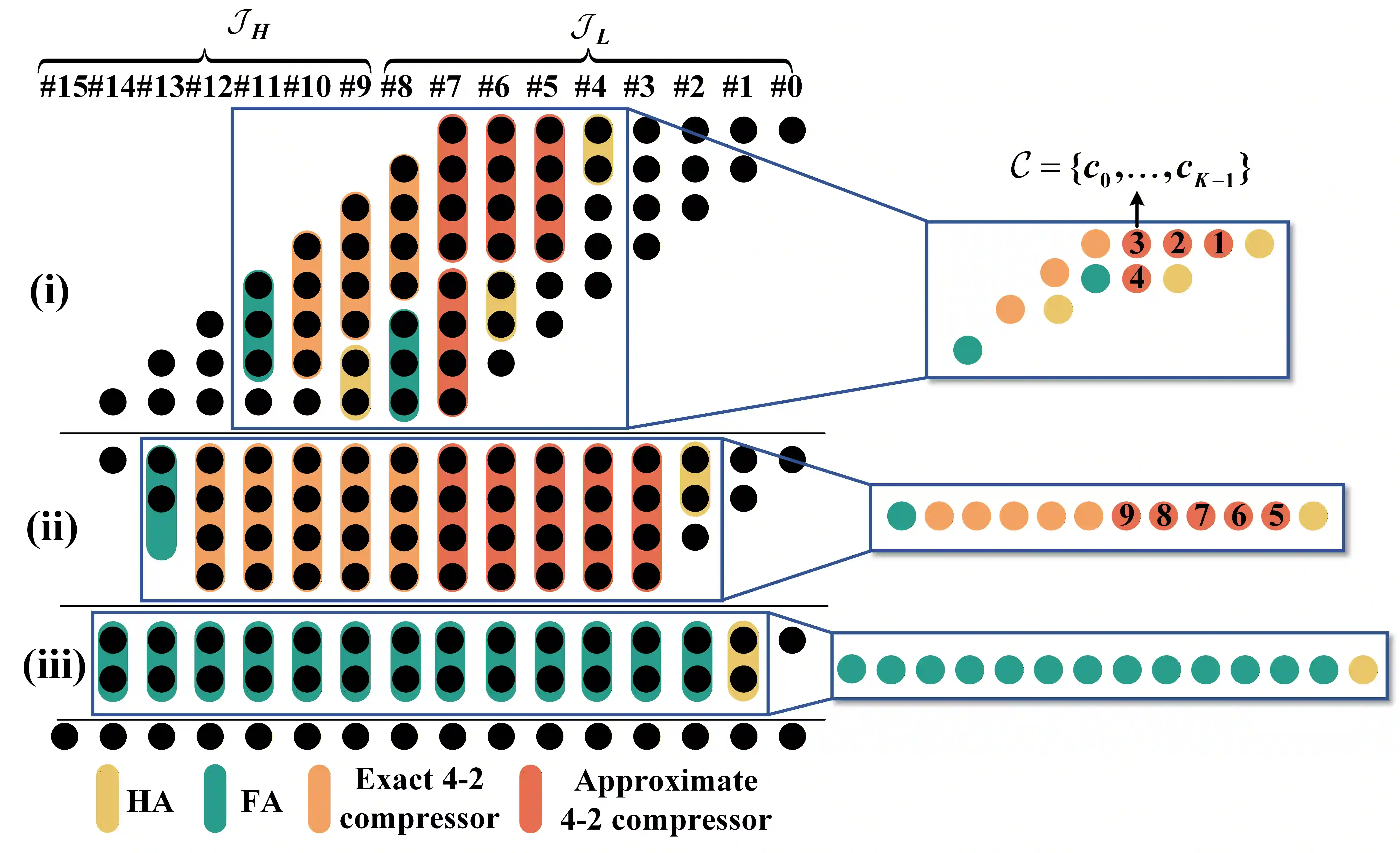
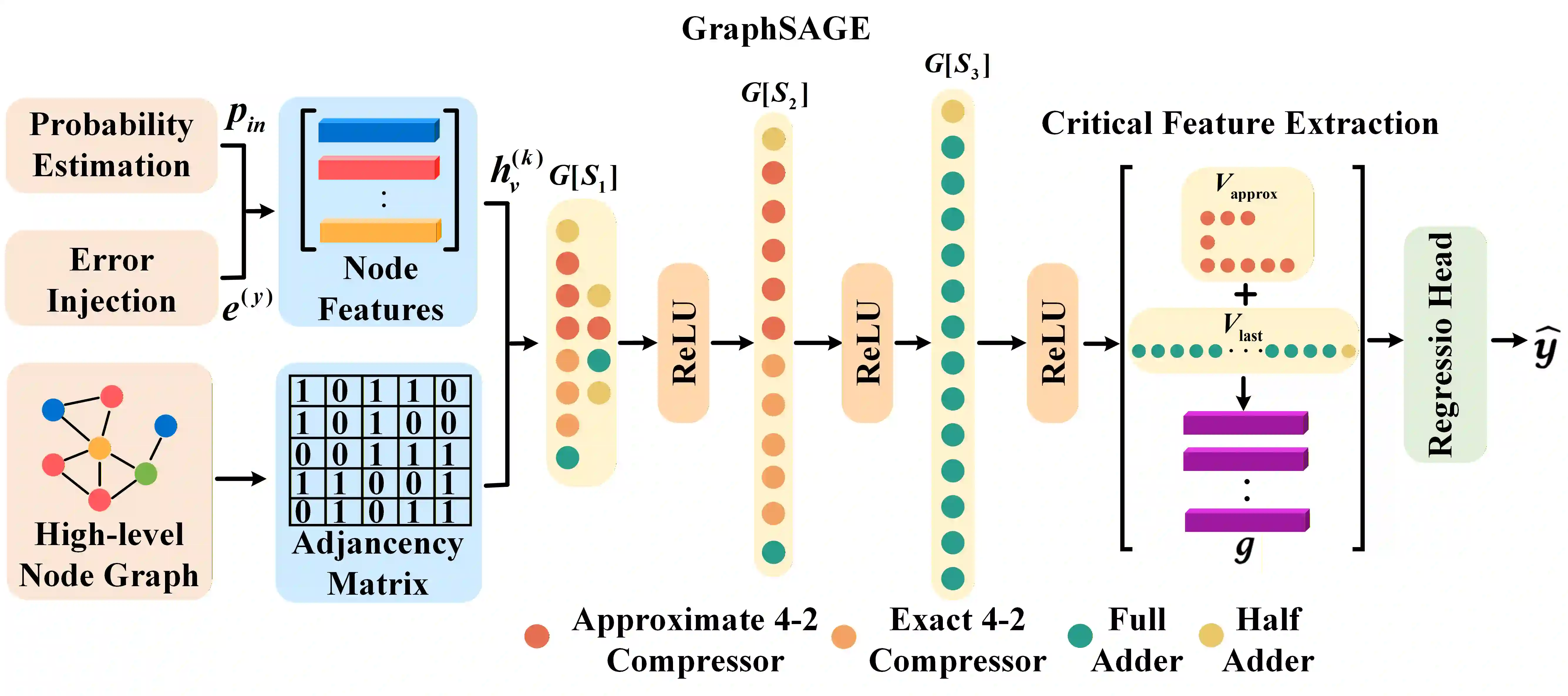
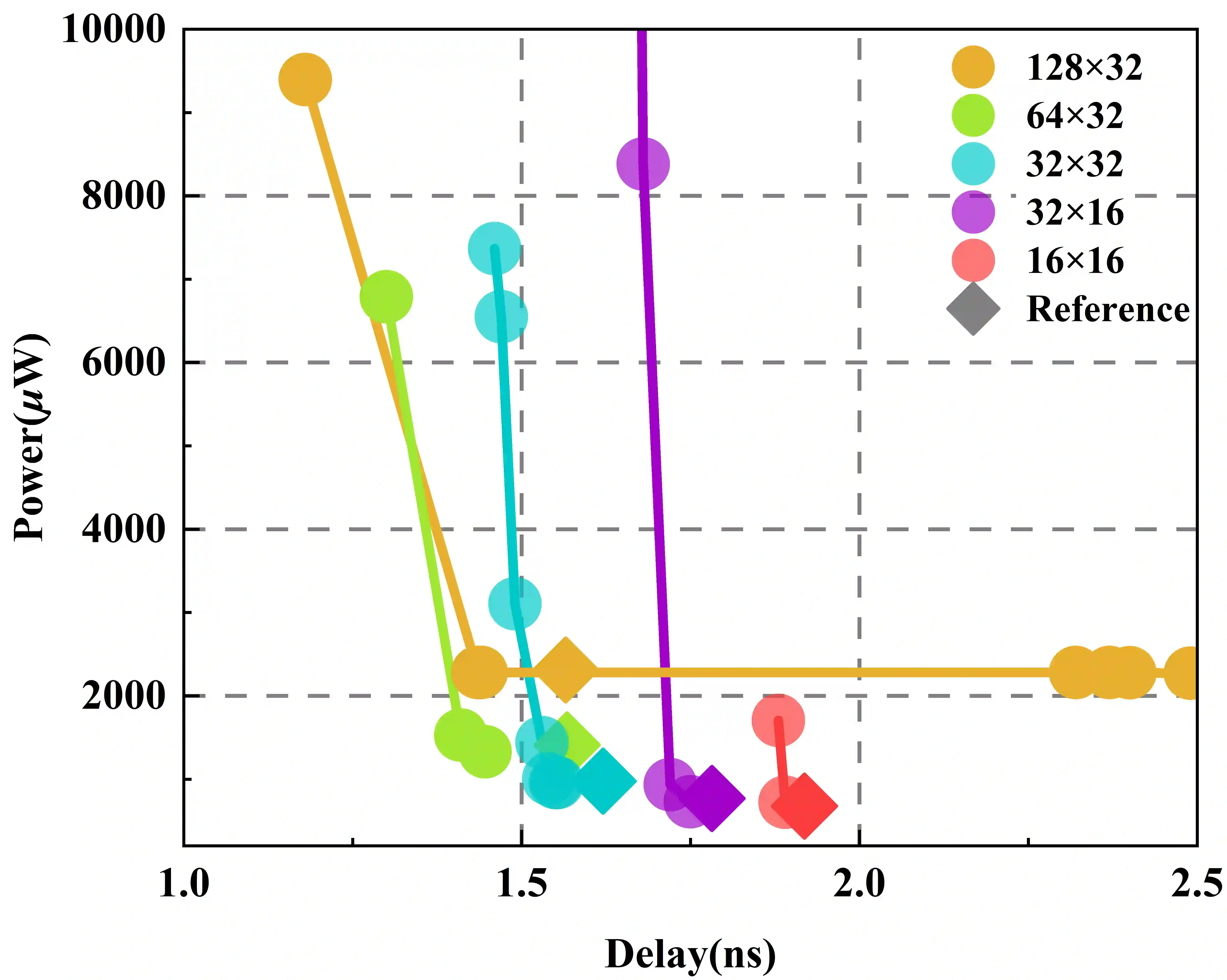
Digital Compute-in-Memory (DCiM) accelerates neural networks by reducing data movement. Approximate DCiM can further improve power-performance-area (PPA), but demands accuracy-constrained co-optimization across coupled architecture and transistor-level choices. Building on OpenYield, we introduce Accuracy-Constrained Co-Optimization (ACCO) and present OpenACMv2, an open framework that operationalizes ACCO via two-level optimization: (1) accuracy-constrained architecture search of compressor combinations and SRAM macro parameters, driven by a fast GNN-based surrogate for PPA and error; and (2) variation- and PVT-aware transistor sizing for standard cells and SRAM bitcells using Monte Carlo. By decoupling ACCO into architecture-level exploration and circuit-level sizing, OpenACMv2 integrates classic single- and multi-objective optimizers to deliver strong PPA-accuracy tradeoffs and robust convergence. The workflow is compatible with FreePDK45 and OpenROAD, supporting reproducible evaluation and easy adoption. Experiments demonstrate significant PPA improvements under controlled accuracy budgets, enabling rapid "what-if" exploration for approximate DCiM. The framework is available on https://github.com/ShenShan123/OpenACM.
翻译:数字存内计算(DCiM)通过减少数据移动来加速神经网络。近似DCiM可以进一步提升功耗-性能-面积(PPA)指标,但需要在耦合的架构和晶体管级选择之间进行精度约束的协同优化。基于OpenYield,我们提出了精度约束协同优化(ACCO)方法,并介绍了OpenACMv2——一个通过两级优化实现ACCO的开源框架:(1)在精度约束下,基于快速图神经网络(GNN)代理模型对PPA和误差进行评估,从而对压缩器组合和SRAM宏参数进行架构搜索;(2)利用蒙特卡洛方法,对标准单元和SRAM位单元进行考虑工艺偏差及PVT(工艺、电压、温度)变化的晶体管尺寸优化。通过将ACCO解耦为架构级探索和电路级尺寸优化,OpenACMv2集成了经典的单目标与多目标优化器,能够提供优异的PPA-精度权衡并实现稳健收敛。该工作流兼容FreePDK45和OpenROAD,支持可复现的评估和便捷的采用。实验表明,在受控的精度预算下,框架能实现显著的PPA提升,从而支持针对近似DCiM的快速“假设”探索。该框架已在 https://github.com/ShenShan123/OpenACM 开源。