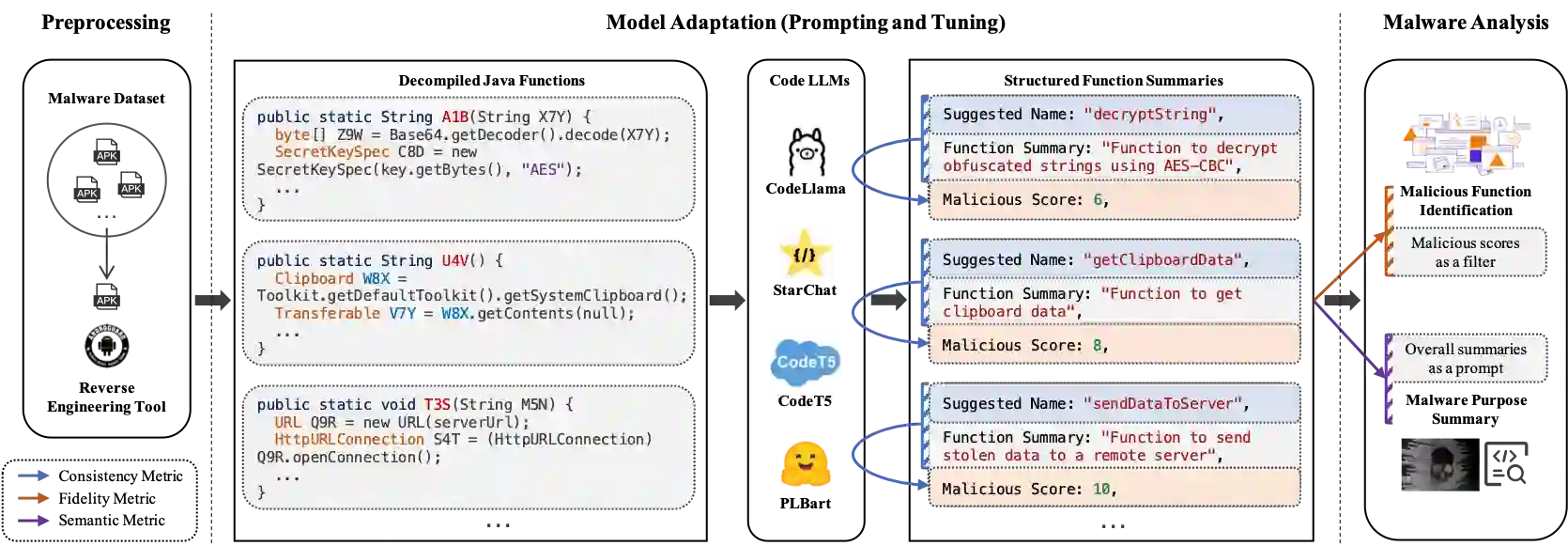
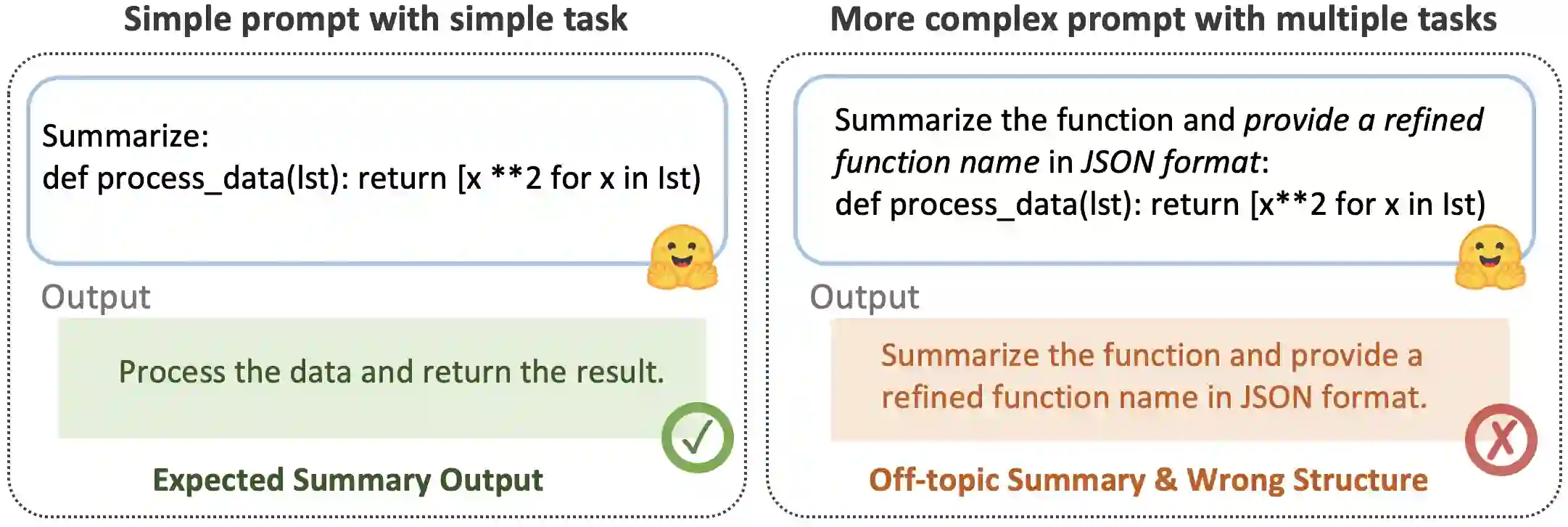
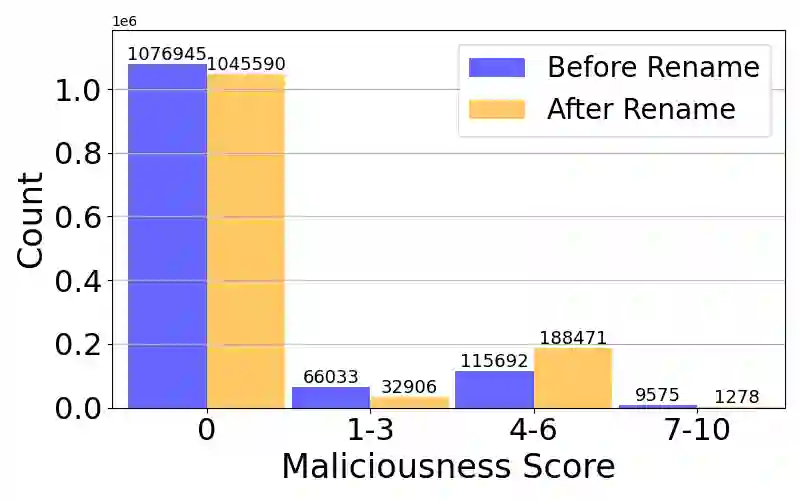
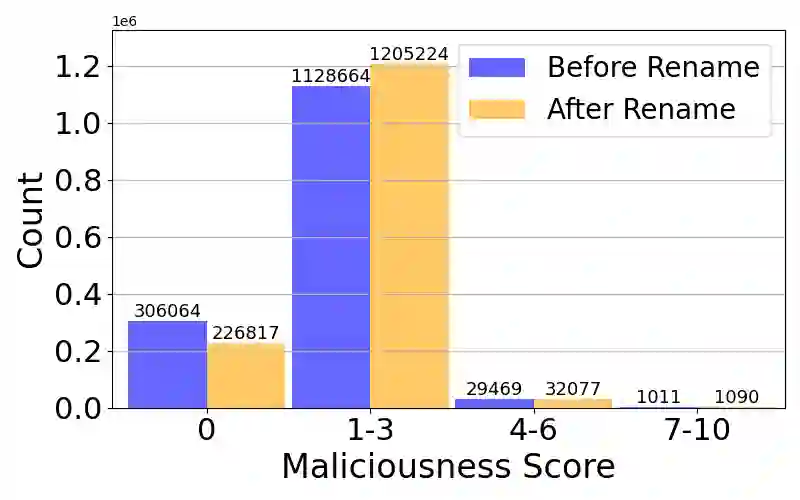
Large Language Models (LLMs) have demonstrated strong capabilities in various code intelligence tasks. However, their effectiveness for Android malware analysis remains underexplored. Decompiled Android code poses unique challenges for analysis, primarily due to its large volume of functions and the frequent absence of meaningful function names. This paper presents Cama, a benchmarking framework designed to systematically evaluate the effectiveness of Code LLMs in Android malware analysis tasks. Cama specifies structured model outputs (comprising function summaries, refined function names, and maliciousness scores) to support key malware analysis tasks, including malicious function identification and malware purpose summarization. Built on these, it integrates three domain-specific evaluation metrics, consistency, fidelity, and semantic relevance, enabling rigorous stability and effectiveness assessment and cross-model comparison. We construct a benchmark dataset consisting of 118 Android malware samples, encompassing over 7.5 million distinct functions, and use Cama to evaluate four popular open-source models. Our experiments provide insights into how Code LLMs interpret decompiled code and quantify the sensitivity to function renaming, highlighting both the potential and current limitations of Code LLMs in malware analysis tasks.
翻译:大语言模型(LLMs)在各种代码智能任务中展现出强大能力。然而,其在安卓恶意软件分析中的有效性尚未得到充分探索。反编译的安卓代码因其庞大的函数数量及频繁缺失有意义的函数名,给分析工作带来了独特挑战。本文提出Cama,一个旨在系统评估代码大语言模型在安卓恶意软件分析任务中有效性的基准测试框架。Cama规定了结构化的模型输出(包括函数摘要、精炼的函数名和恶意性评分),以支持关键的恶意软件分析任务,如恶意函数识别和恶意软件目的摘要。在此基础上,它整合了三个领域特定的评估指标——一致性、保真度和语义相关性,从而能够进行严格的稳定性与有效性评估及跨模型比较。我们构建了一个包含118个安卓恶意软件样本的基准数据集,涵盖超过750万个独立函数,并使用Cama评估了四种流行的开源模型。我们的实验揭示了代码大语言模型如何解释反编译代码,并量化了其对函数重命名的敏感性,同时凸显了代码大语言模型在恶意软件分析任务中的潜力与当前局限。