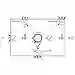
In this paper, we propose long short term memory speech enhancement network (LSTMSE-Net), an audio-visual speech enhancement (AVSE) method. This innovative method leverages the complementary nature of visual and audio information to boost the quality of speech signals. Visual features are extracted with VisualFeatNet (VFN), and audio features are processed through an encoder and decoder. The system scales and concatenates visual and audio features, then processes them through a separator network for optimized speech enhancement. The architecture highlights advancements in leveraging multi-modal data and interpolation techniques for robust AVSE challenge systems. The performance of LSTMSE-Net surpasses that of the baseline model from the COG-MHEAR AVSE Challenge 2024 by a margin of 0.06 in scale-invariant signal-to-distortion ratio (SISDR), $0.03$ in short-time objective intelligibility (STOI), and $1.32$ in perceptual evaluation of speech quality (PESQ). The source code of the proposed LSTMSE-Net is available at \url{https://github.com/mtanveer1/AVSEC-3-Challenge}.
翻译:本文提出了一种长短期记忆语音增强网络(LSTMSE-Net),这是一种视听语音增强(AVSE)方法。该创新方法利用视觉与音频信息的互补特性来提升语音信号质量。视觉特征通过视觉特征网络(VFN)提取,音频特征则通过编码器与解码器进行处理。该系统对视觉和音频特征进行缩放与拼接,随后通过一个分离器网络进行处理,以实现优化的语音增强。该架构突出了在利用多模态数据及插值技术构建鲁棒的视听语音增强挑战系统方面的进展。LSTMSE-Net 的性能超越了 2024 年 COG-MHEAR 视听语音增强挑战赛的基线模型,在尺度不变信噪比(SISDR)上超出 0.06,在短时客观可懂度(STOI)上超出 $0.03$,在语音质量感知评估(PESQ)上超出 $1.32$。所提出的 LSTMSE-Net 的源代码发布于 \url{https://github.com/mtanveer1/AVSEC-3-Challenge}。