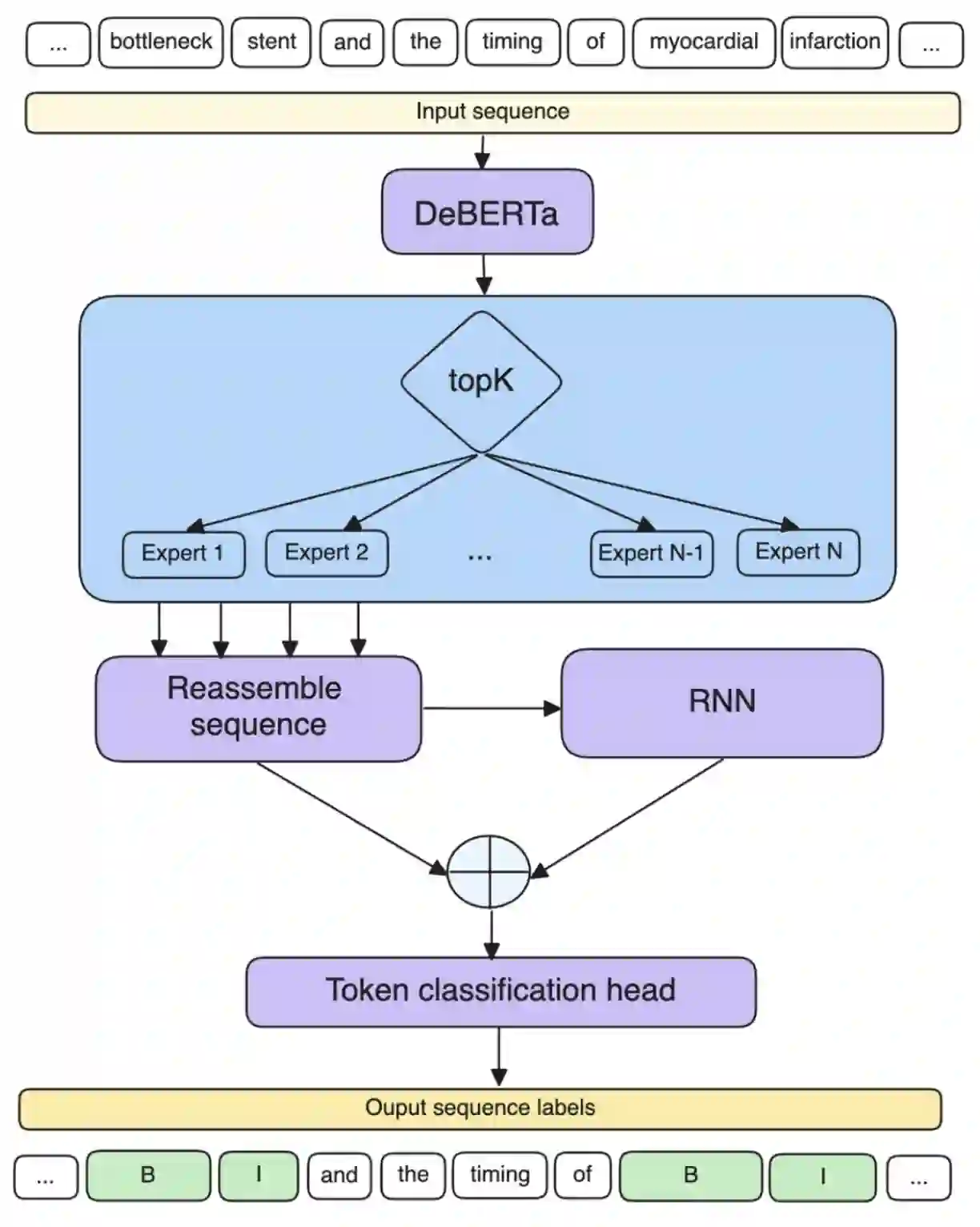
Keyword extraction involves identifying the most descriptive words in a document, allowing automatic categorisation and summarisation of large quantities of diverse textual data. Relying on the insight that real-world keyword detection often requires handling of diverse content, we propose a novel supervised keyword extraction approach based on the mixture of experts (MoE) technique. MoE uses a learnable routing sub-network to direct information to specialised experts, allowing them to specialize in distinct regions of the input space. SEKE, a mixture of Specialised Experts for supervised Keyword Extraction, uses DeBERTa as the backbone model and builds on the MoE framework, where experts attend to each token, by integrating it with a recurrent neural network (RNN), to allow successful extraction even on smaller corpora, where specialisation is harder due to lack of training data. The MoE framework also provides an insight into inner workings of individual experts, enhancing the explainability of the approach. We benchmark SEKE on multiple English datasets, achieving state-of-the-art performance compared to strong supervised and unsupervised baselines. Our analysis reveals that depending on data size and type, experts specialize in distinct syntactic and semantic components, such as punctuation, stopwords, parts-of-speech, or named entities. Code is available at: https://github.com/matejMartinc/SEKE_keyword_extraction
翻译:关键词提取旨在识别文档中最具描述性的词汇,从而实现对海量多样化文本数据的自动分类与摘要。基于现实场景中关键词检测常需处理多样化内容的洞见,本文提出一种基于专家混合模型的新型监督式关键词提取方法。MoE通过可学习的路由子网络将信息导向专用专家,使其能够专注于输入空间的不同区域。SEKE作为面向监督式关键词提取的专用专家混合模型,以DeBERTa为骨干网络,在MoE框架基础上集成循环神经网络,使专家能关注每个标记,从而即使在训练数据匮乏导致专业化难度更高的小型语料库中也能实现有效提取。MoE框架同时为解析各专家内部工作机制提供途径,增强了方法的可解释性。我们在多个英文数据集上对SEKE进行基准测试,相较于强监督与无监督基线模型均取得了最先进的性能表现。分析表明,根据数据规模与类型,专家会专注于不同的句法与语义成分,如标点符号、停用词、词性成分或命名实体。代码已开源:https://github.com/matejMartinc/SEKE_keyword_extraction