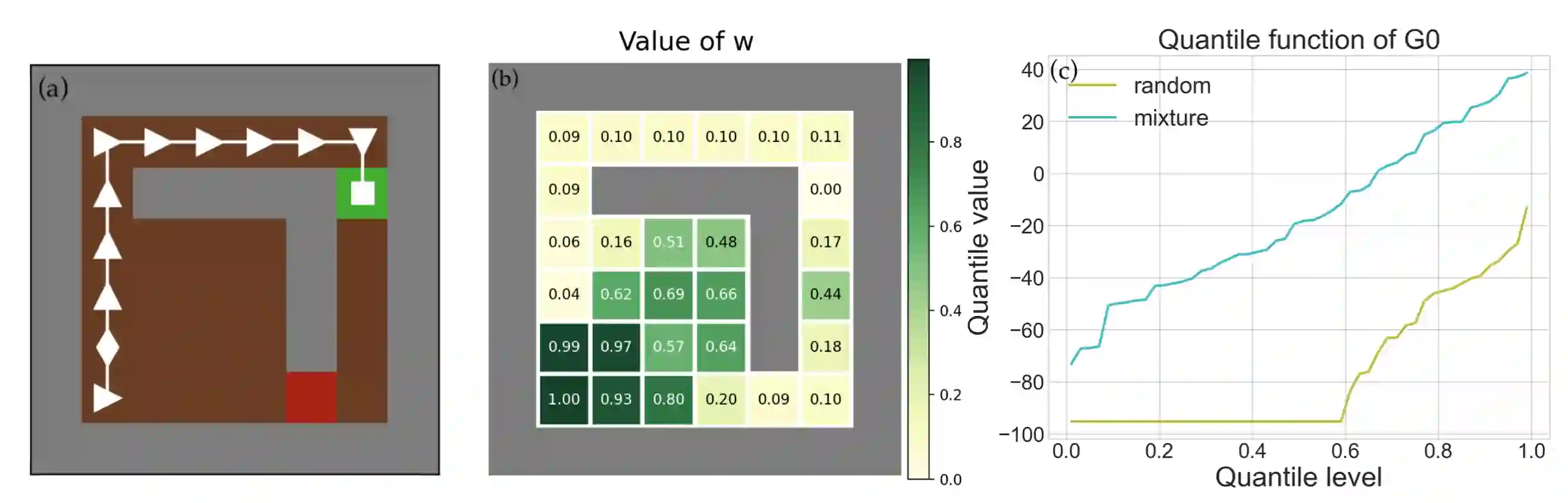
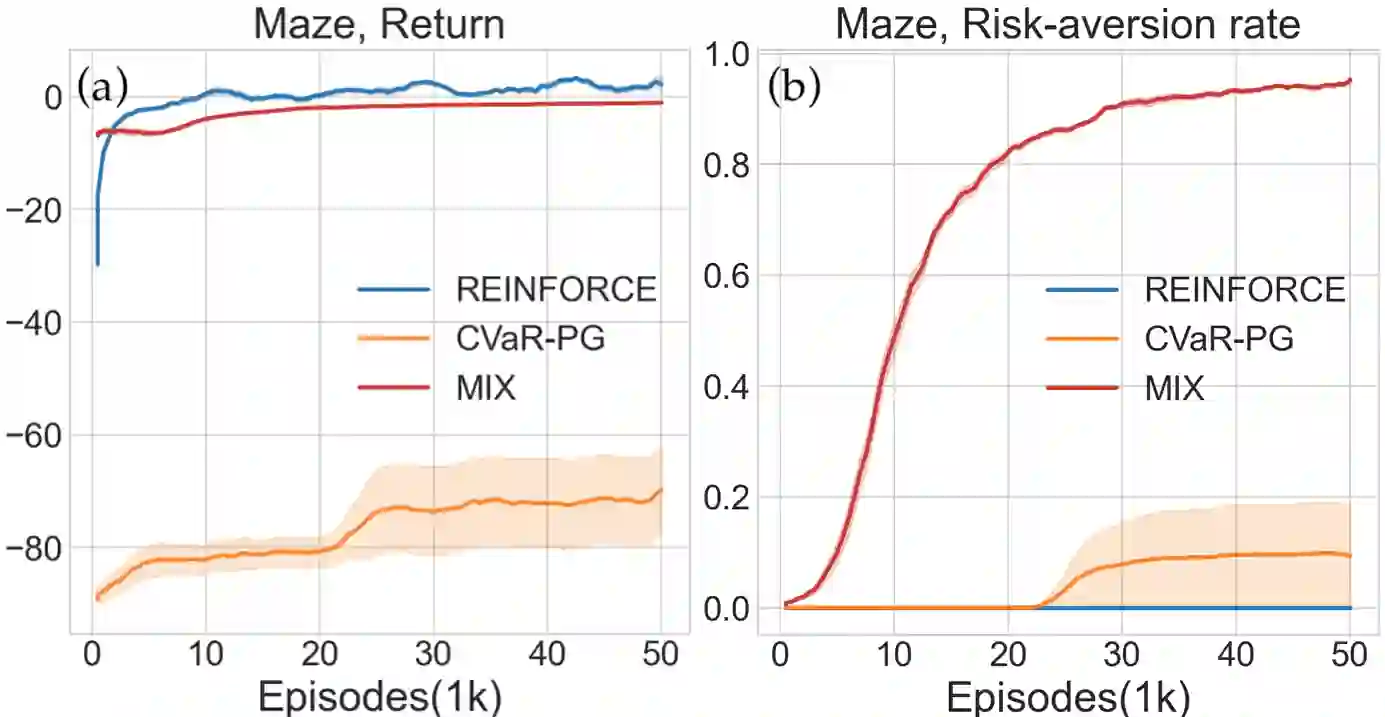
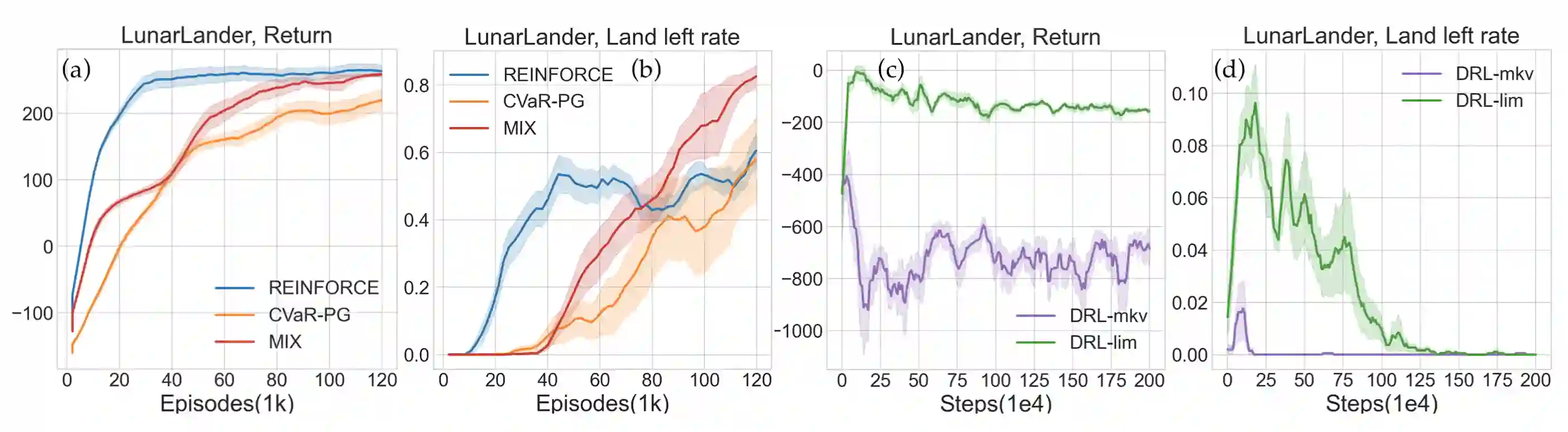
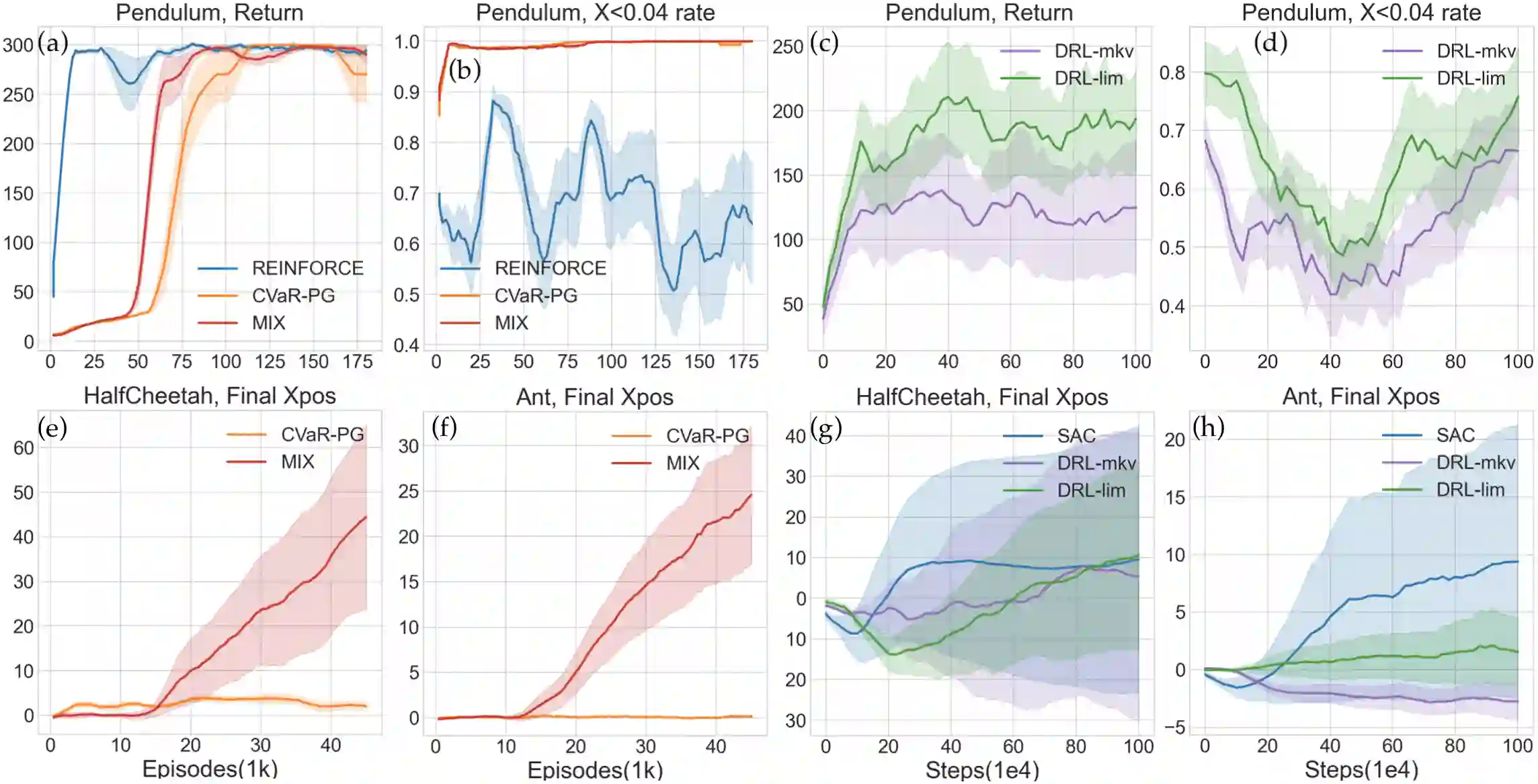
Reinforcement learning algorithms utilizing policy gradients (PG) to optimize Conditional Value at Risk (CVaR) face significant challenges with sample inefficiency, hindering their practical applications. This inefficiency stems from two main facts: a focus on tail-end performance that overlooks many sampled trajectories, and the potential of gradient vanishing when the lower tail of the return distribution is overly flat. To address these challenges, we propose a simple mixture policy parameterization. This method integrates a risk-neutral policy with an adjustable policy to form a risk-averse policy. By employing this strategy, all collected trajectories can be utilized for policy updating, and the issue of vanishing gradients is counteracted by stimulating higher returns through the risk-neutral component, thus lifting the tail and preventing flatness. Our empirical study reveals that this mixture parameterization is uniquely effective across a variety of benchmark domains. Specifically, it excels in identifying risk-averse CVaR policies in some Mujoco environments where the traditional CVaR-PG fails to learn a reasonable policy.
翻译:利用策略梯度优化条件风险价值的强化学习算法面临样本效率低下的显著挑战,这阻碍了其实际应用。这种低效源于两个主要原因:对尾部性能的关注忽略了大量采样轨迹,以及当回报分布的下尾过于平坦时可能出现的梯度消失问题。为解决这些挑战,我们提出了一种简单的混合策略参数化方法。该方法通过整合一个风险中性策略与一个可调节策略来构成风险规避策略。采用此策略后,所有收集到的轨迹均可用于策略更新,且梯度消失问题通过风险中性组件激励更高回报得到缓解,从而提升尾部并防止平坦化。我们的实证研究表明,这种混合参数化方法在多种基准领域中具有独特优势。具体而言,它在部分Mujoco环境中能有效识别风险规避的条件风险价值策略,而传统的条件风险价值-策略梯度方法在这些环境中无法学习到合理策略。