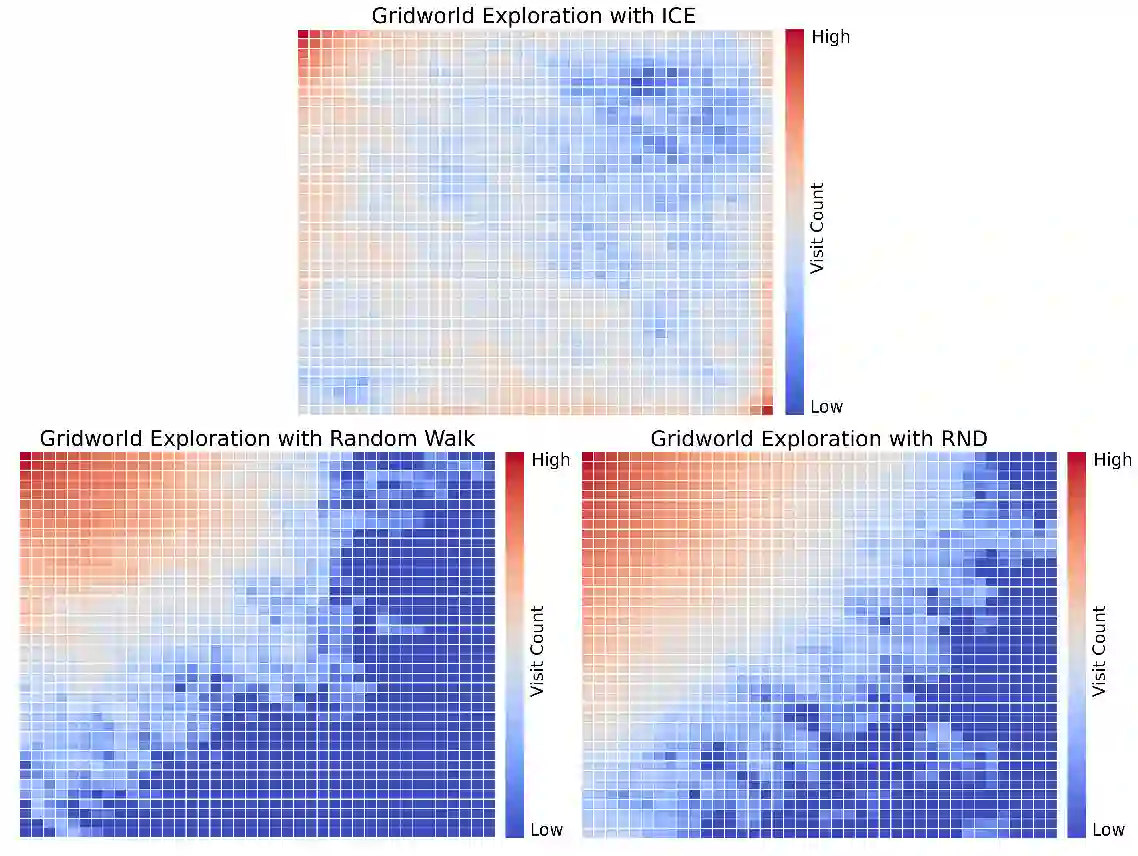
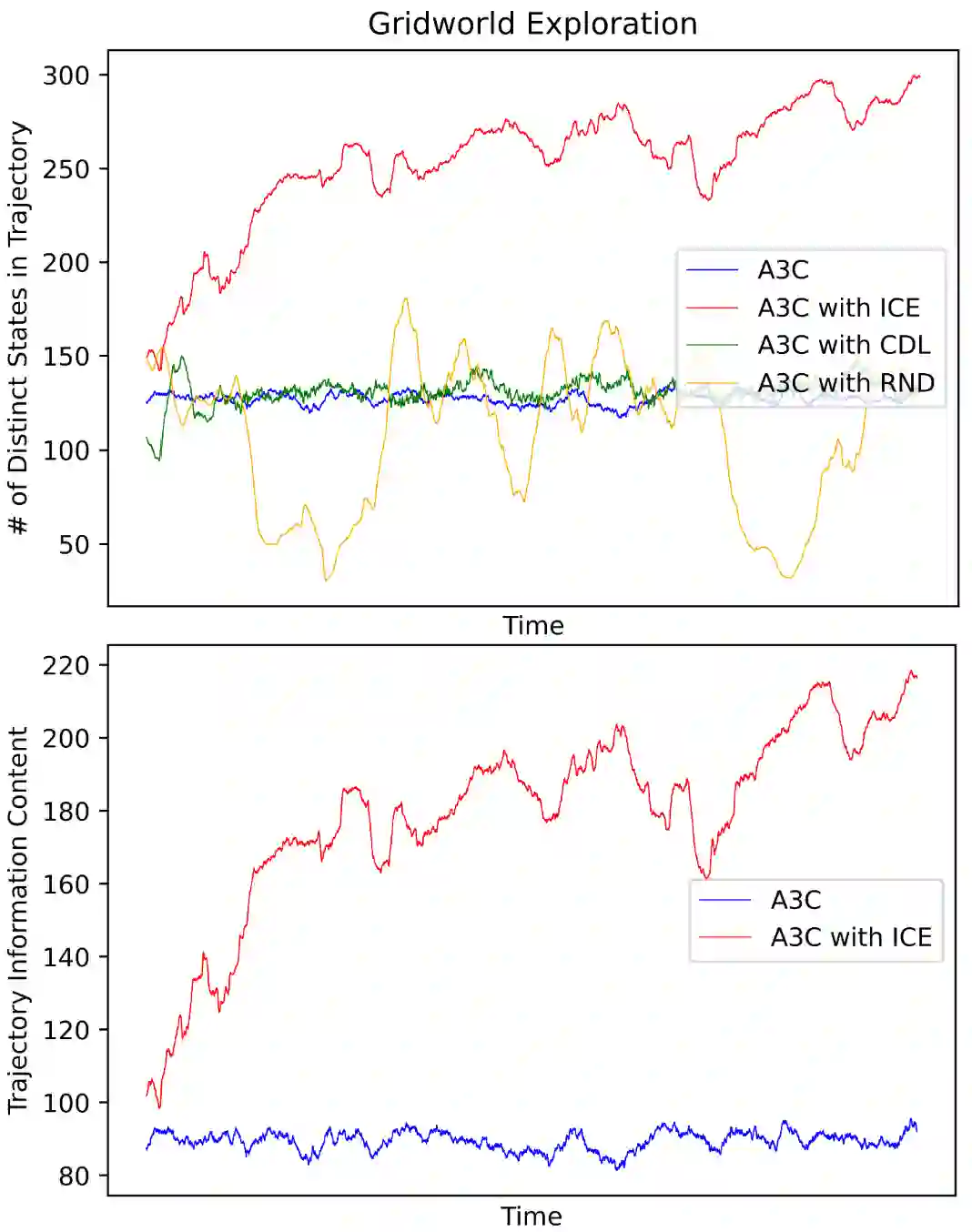
Sparse reward environments are known to be challenging for reinforcement learning agents. In such environments, efficient and scalable exploration is crucial. Exploration is a means by which an agent gains information about the environment. We expand on this topic and propose a new intrinsic reward that systemically quantifies exploratory behavior and promotes state coverage by maximizing the information content of a trajectory taken by an agent. We compare our method to alternative exploration based intrinsic reward techniques, namely Curiosity Driven Learning and Random Network Distillation. We show that our information theoretic reward induces efficient exploration and outperforms in various games, including Montezuma Revenge, a known difficult task for reinforcement learning. Finally, we propose an extension that maximizes information content in a discretely compressed latent space which boosts sample efficiency and generalizes to continuous state spaces.
翻译:稀疏奖励环境对强化学习智能体而言极具挑战性。在此类环境中,高效且可扩展的探索至关重要。探索是智能体获取环境信息的一种手段。我们对此主题进行深入拓展,提出了一种新的内在奖励机制,该机制通过最大化智能体轨迹的信息内容,系统性地量化探索行为并促进状态覆盖。我们将所提方法与基于探索的替代性内在奖励技术——即好奇心驱动学习与随机网络蒸馏——进行了比较。实验表明,我们基于信息论的奖励机制能诱发高效探索,并在包括《蒙特祖玛复仇》这一公认的强化学习难题在内的多种游戏中表现更优。最后,我们提出了一项扩展方案,在离散压缩的潜在空间中最大化信息内容,该方案提升了样本效率并泛化至连续状态空间。