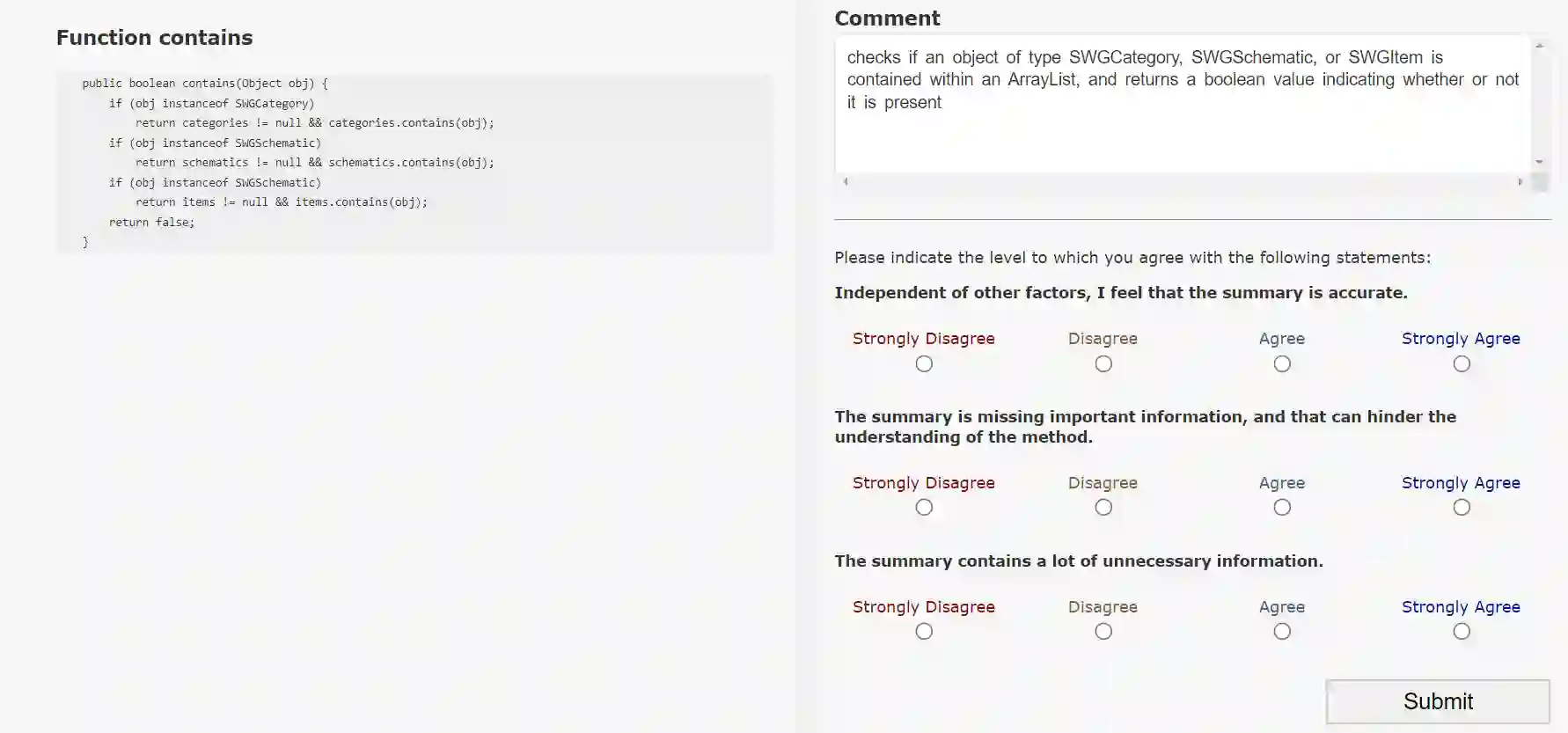
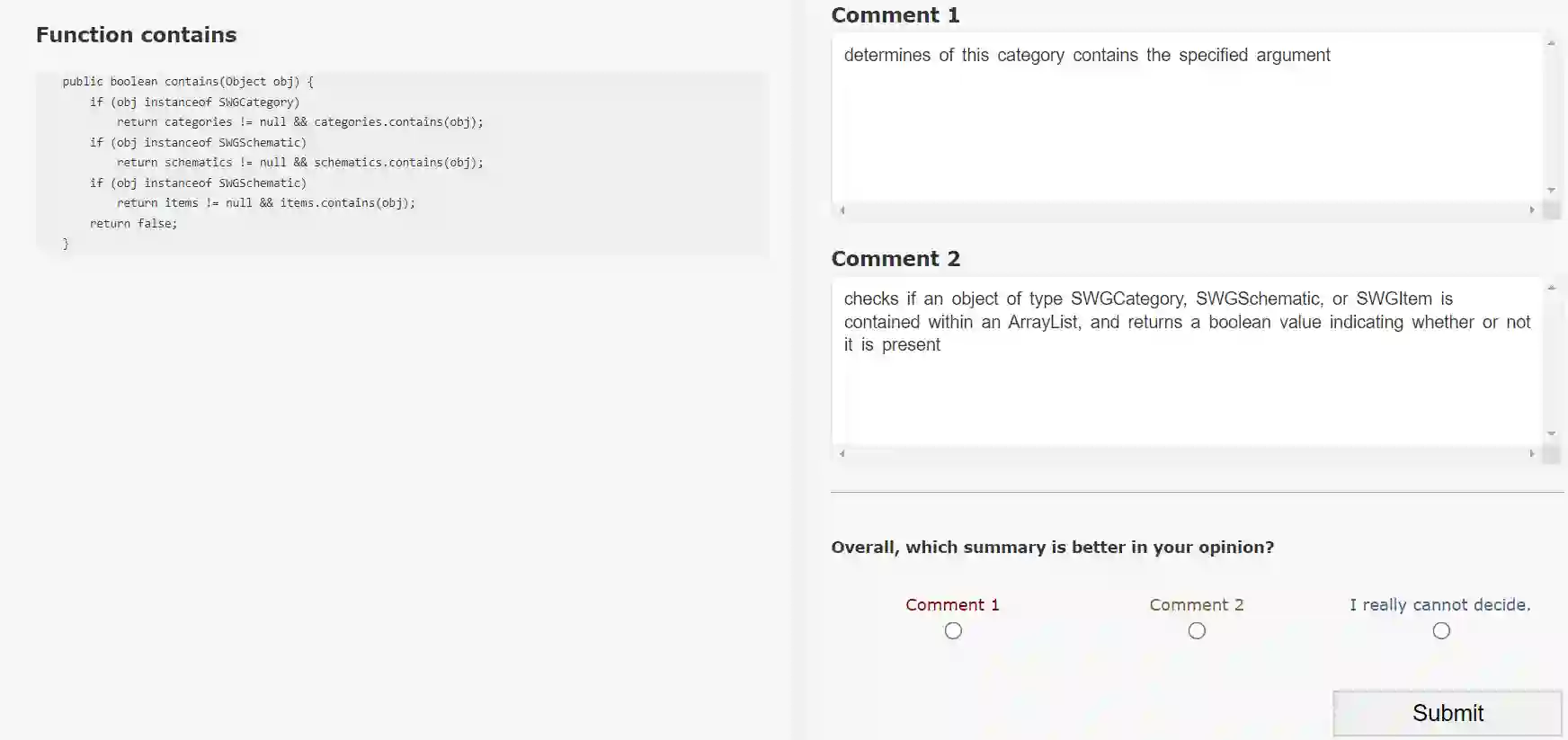
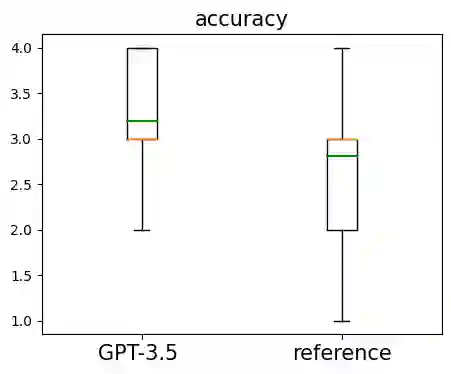
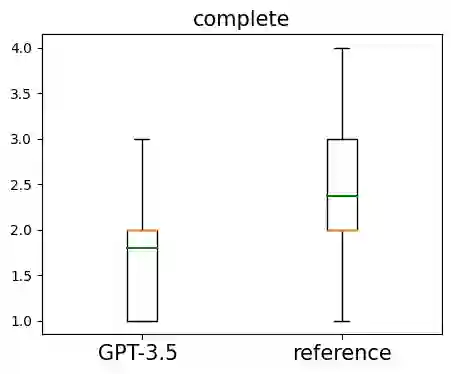
A code summary is a brief natural language description of source code. Summaries are usually only a single sentence long, and yet form the backbone of developer documentation. A short descriptions such as "changes all visible polygons to the color blue" can give a programmer a high-level idea of what code does without the effort of reading the code itself. Recently, products based on Large Language Models such as ChatGPT have demonstrated a strong ability to write these descriptions automatically. However, to use these tools, programmers must send their code to untrusted third parties for processing (e.g., via an API call). This loss of custody is not acceptable to many organizations. In this paper, we present an alternative: we train an open source model using sample output generated by GPT-3.5 in a process related to knowledge distillation. Our model is small enough (350m parameters) to be run on a single 16gb GPU, yet we show in our evaluation that it is large enough to mimic GPT-3.5 on this task.
翻译:代码摘要是对源代码的简要自然语言描述。摘要通常仅为一个句子,但构成了开发者文档的核心基础。诸如"将所有可见多边形更改为蓝色"之类的简短描述,能使程序员在不阅读代码本身的情况下理解代码的高层次功能。近期,基于ChatGPT等大型语言模型的产品已展现出自动生成这些描述的卓越能力。然而,使用这些工具时,程序员必须将代码发送给不可信的第三方进行处理(例如通过API调用)。这种代码控制权的丧失对许多组织而言不可接受。本文提出一种替代方案:我们通过知识蒸馏相关流程,利用GPT-3.5生成的样本输出来训练开源模型。该模型参数量仅3.5亿,可在单块16GB GPU上运行,而我们的评估表明其容量足以在摘要任务中模仿GPT-3.5的性能。