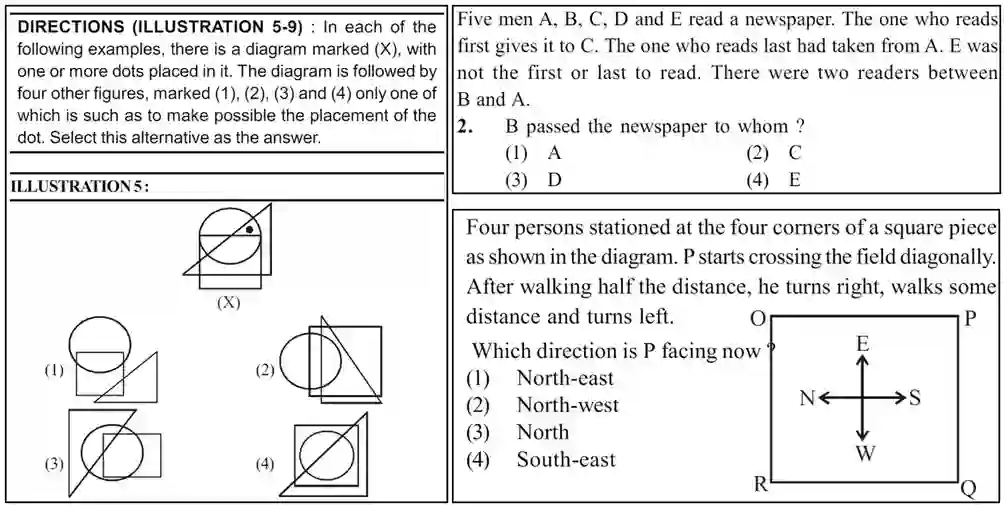
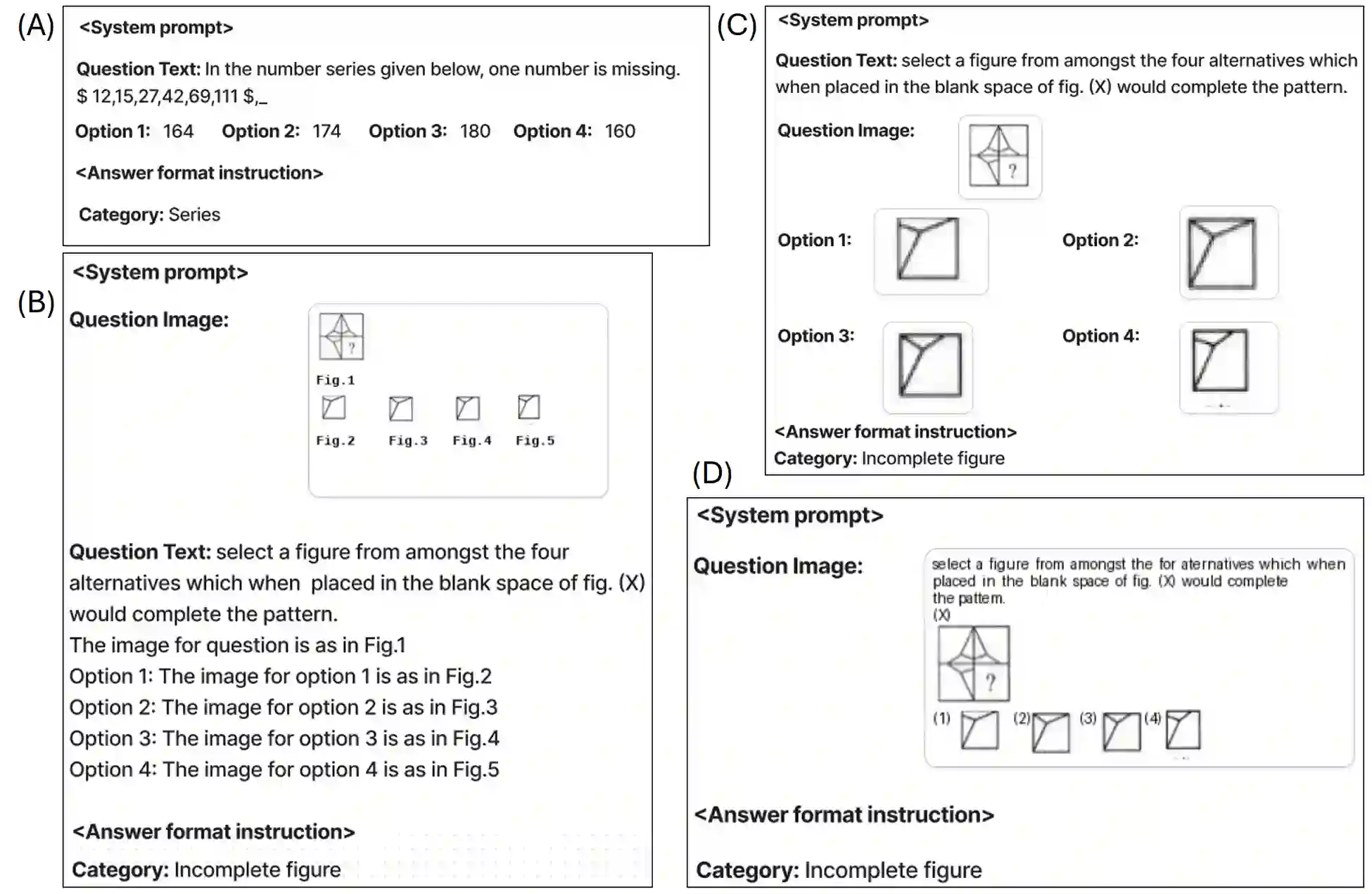
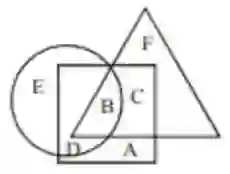
Cognitive textual and visual reasoning tasks, including puzzles, series, and analogies, demand the ability to quickly reason, decipher, and evaluate patterns both textually and spatially. Due to extensive training on vast amounts of human-curated data, LLMs and VLMs excel in common-sense reasoning tasks, however still struggle with more complex reasoning that demands deeper cognitive understanding. We introduce NTSEBench, a new dataset designed to evaluate cognitive multi-modal reasoning and problem-solving skills of large models. The dataset contains 2728 multiple-choice questions, accompanied by a total of 4,642 images, categorized into 26 different types. These questions are drawn from the nationwide NTSE examination in India and feature a mix of visual and textual general aptitude challenges, designed to assess intelligence and critical thinking skills beyond mere rote learning. We establish baselines on the dataset using state-of-the-art LLMs and VLMs. To facilitate a comparison between open source and propriety models, we propose four distinct modeling strategies to handle different modalities -- text and images -- in the dataset instances.
翻译:认知文本与视觉推理任务(包括谜题、序列和类比)要求具备快速推理、解读和评估文本与空间模式的能力。尽管大型语言模型(LLMs)和视觉语言模型(VLMs)通过海量人工标注数据的训练在常识推理任务中表现优异,但在需要更深层认知理解的复杂推理方面仍存在困难。本文提出NTSEBench——一个专为评估大模型认知多模态推理与问题解决能力而设计的新数据集。该数据集包含2728道多项选择题,并配有总计4642张图像,涵盖26种不同题型。这些问题选自印度全国性NTSE考试,融合了视觉与文本的综合能力挑战,旨在评估超越机械记忆的智力与批判性思维技能。我们采用前沿的LLMs和VLMs在数据集上建立了基线。为促进开源模型与专有模型的比较,我们针对数据实例中不同模态(文本与图像)的处理提出了四种不同的建模策略。