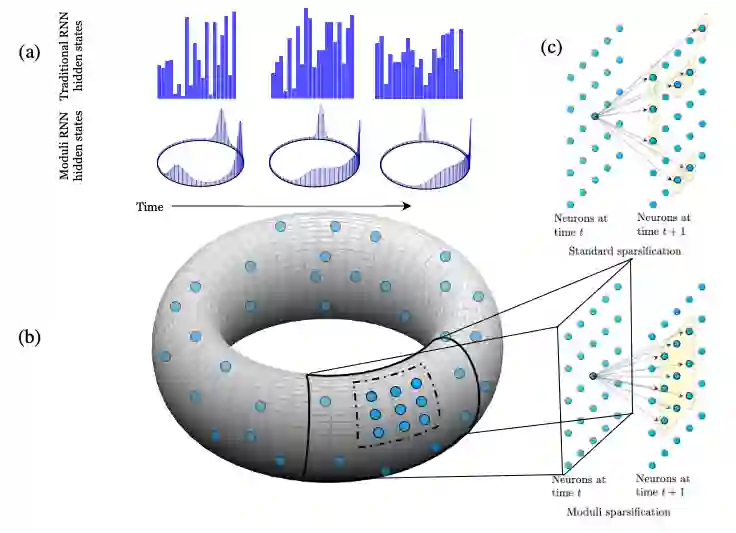
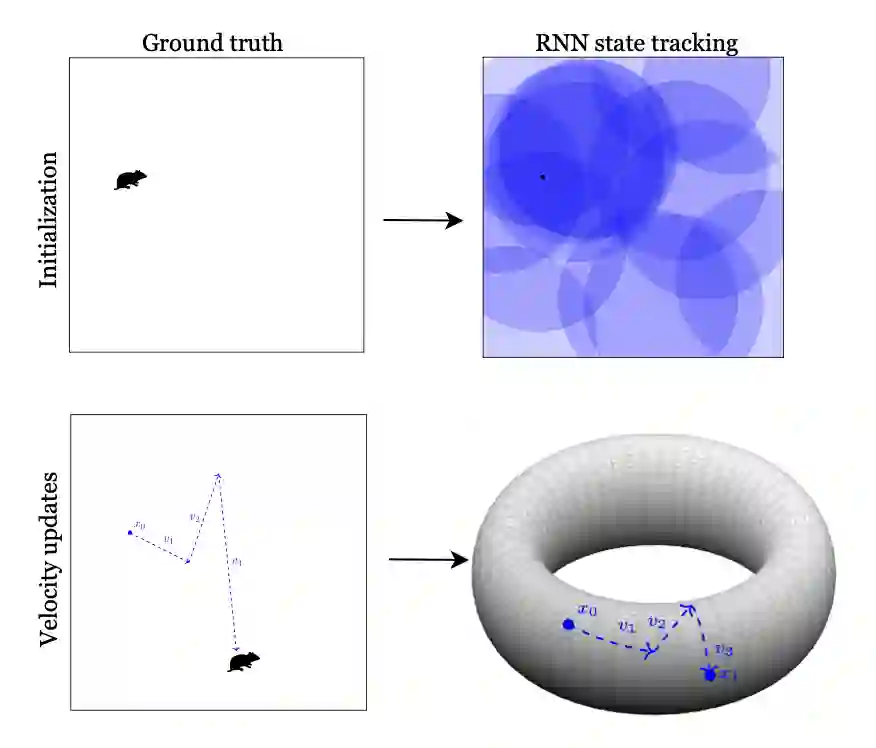
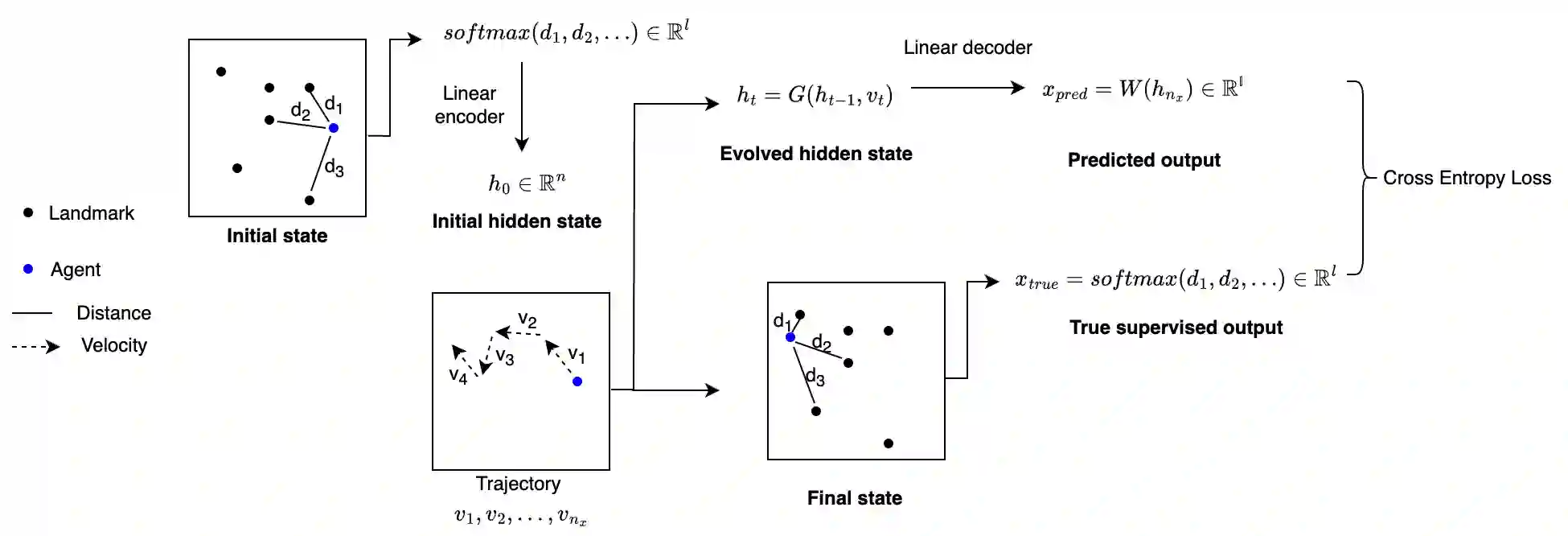
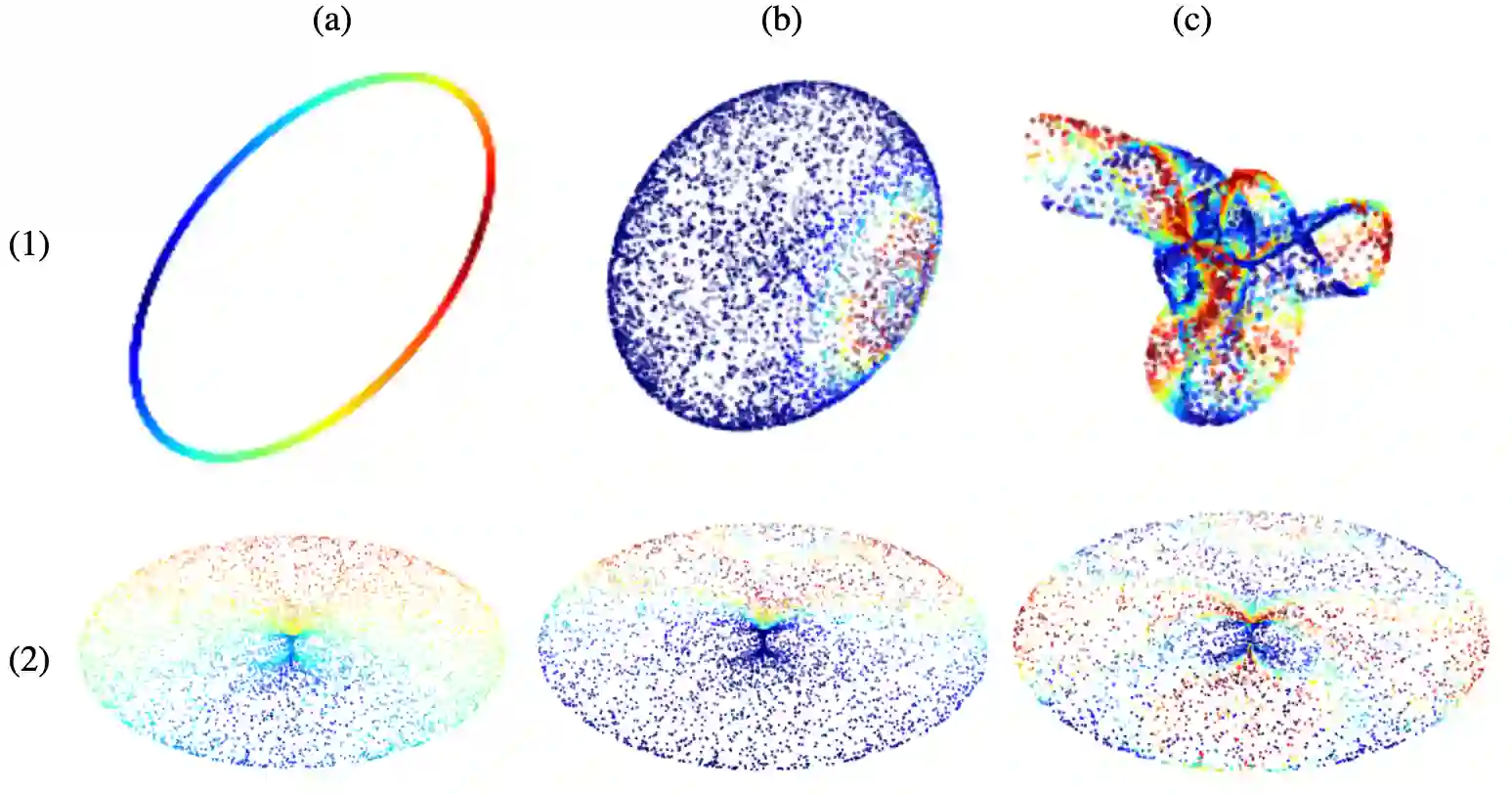
A common technique for ameliorating the computational costs of running large neural models is sparsification, or the pruning of neural connections during training. Sparse models are capable of maintaining the high accuracy of state of the art models, while functioning at the cost of more parsimonious models. The structures which underlie sparse architectures are, however, poorly understood and not consistent between differently trained models and sparsification schemes. In this paper, we propose a new technique for sparsification of recurrent neural nets (RNNs), called moduli regularization, in combination with magnitude pruning. Moduli regularization leverages the dynamical system induced by the recurrent structure to induce a geometric relationship between neurons in the hidden state of the RNN. By making our regularizing term explicitly geometric, we provide the first, to our knowledge, a priori description of the desired sparse architecture of our neural net, as well as explicit end-to-end learning of RNN geometry. We verify the effectiveness of our scheme under diverse conditions, testing in navigation, natural language processing, and addition RNNs. Navigation is a structurally geometric task, for which there are known moduli spaces, and we show that regularization can be used to reach 90% sparsity while maintaining model performance only when coefficients are chosen in accordance with a suitable moduli space. Natural language processing and addition, however, have no known moduli space in which computations are performed. Nevertheless, we show that moduli regularization induces more stable recurrent neural nets, and achieves high fidelity models above 90% sparsity.
翻译:缓解大型神经网络模型计算开销的一种常用技术是稀疏化,即在训练过程中剪除神经连接。稀疏模型能够保持最先进模型的高精度,同时以更经济的模型成本运行。然而,稀疏架构背后的结构尚不明确,且在不同训练模型和稀疏化方案之间缺乏一致性。本文提出一种结合幅度剪枝的循环神经网络(RNNs)稀疏化新技术,称为模正则化。该技术利用循环结构诱导的动力学系统,在RNN隐藏状态中建立神经元间的几何关系。通过使正则化项具有明确的几何特性,我们首次(据我们所知)实现了对神经网络期望稀疏架构的先验描述,以及RNN几何结构的端到端显式学习。我们在多种条件下验证了该方案的有效性,包括导航、自然语言处理和加法RNN等任务。导航任务具有结构性几何特征,且存在已知模空间;我们证明只有当系数选取符合适当模空间时,正则化才能在保持模型性能的同时达到90%的稀疏度。自然语言处理和加法任务虽无已知的计算模空间,但模正则化仍能诱导出更稳定的循环神经网络,并在超过90%的稀疏度下实现高保真度模型。