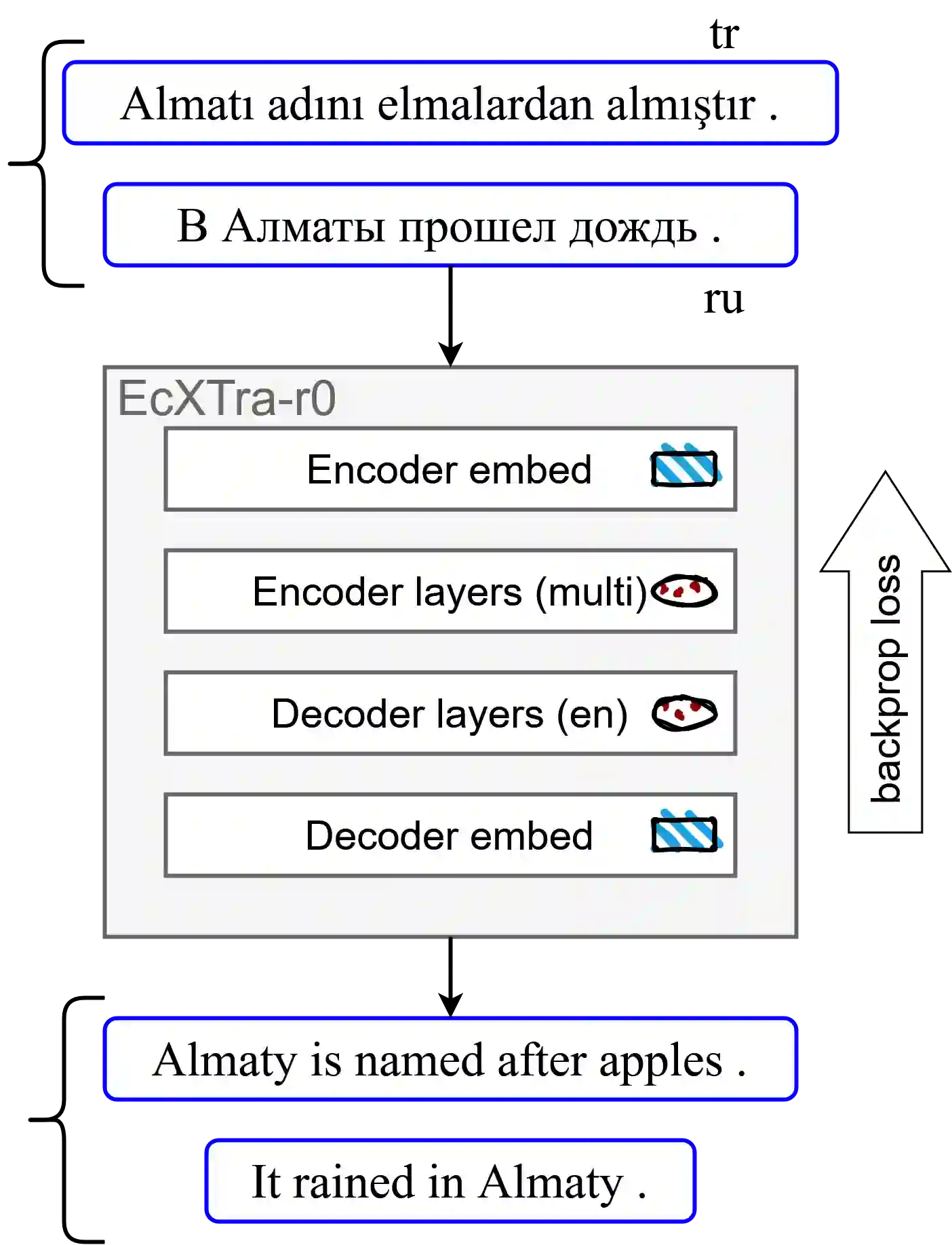
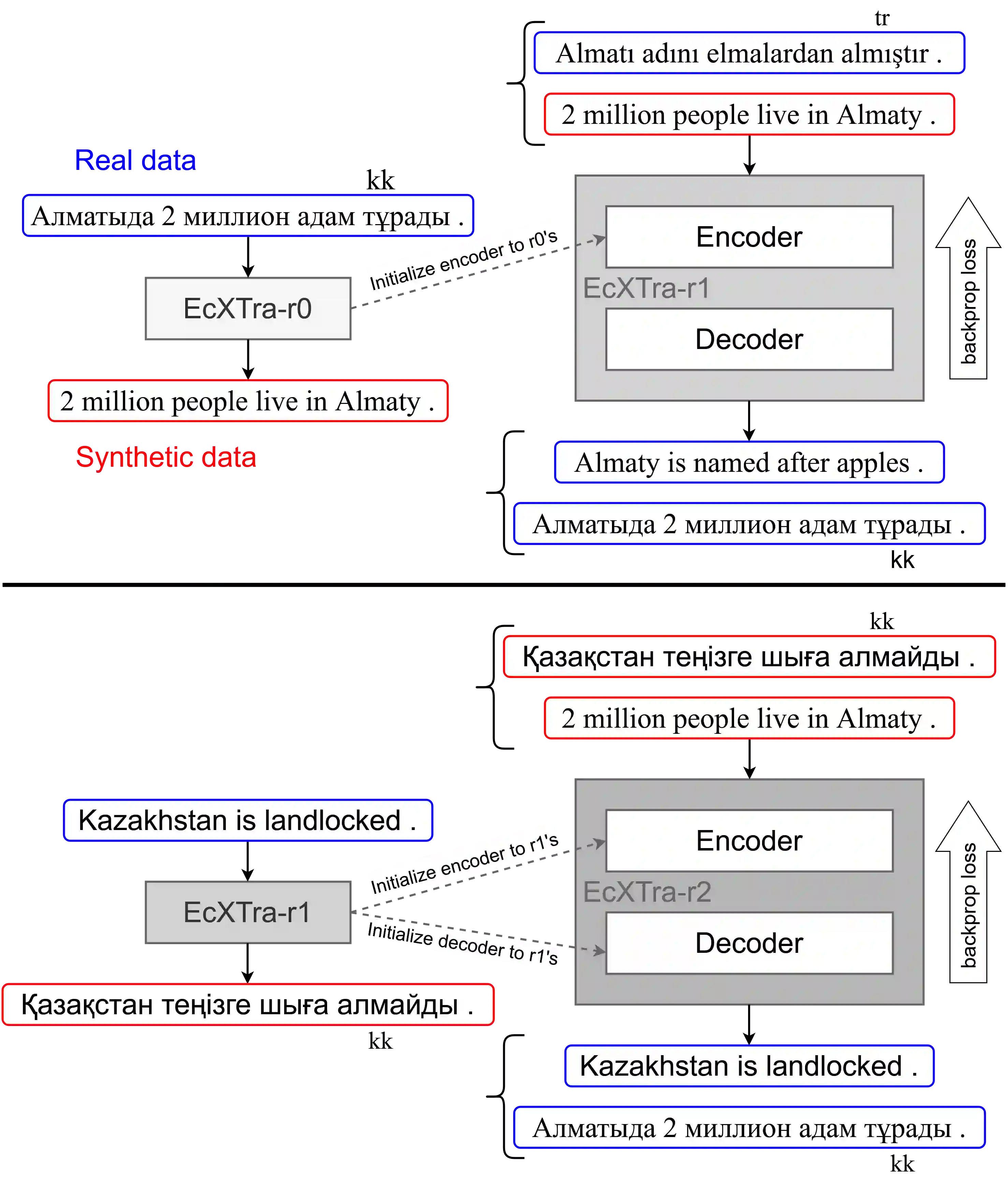
We propose a two-stage approach for training a single NMT model to translate unseen languages both to and from English. For the first stage, we initialize an encoder-decoder model to pretrained XLM-R and RoBERTa weights, then perform multilingual fine-tuning on parallel data in 40 languages to English. We find this model can generalize to zero-shot translations on unseen languages. For the second stage, we leverage this generalization ability to generate synthetic parallel data from monolingual datasets, then train with successive rounds of bidirectional back-translation. We term our approach EcXTra ({E}nglish-{c}entric Crosslingual ({X}) {Tra}nsfer). Our approach is conceptually simple, only using a standard cross-entropy objective throughout, and also is data-driven, sequentially leveraging auxiliary parallel data and monolingual data. We evaluate our unsupervised NMT results on 7 low-resource languages, and find that each round of back-translation training further refines bidirectional performance. Our final single EcXTra-trained model achieves competitive translation performance in all translation directions, notably establishing a new state-of-the-art for English-to-Kazakh (22.9 > 10.4 BLEU).
翻译:我们提出了一种两阶段方法,用于训练单个神经机器翻译(NMT)模型,使其能够将未见过的语言与英语进行双向翻译。第一阶段,我们初始化一个编码器-解码器模型,其权重基于预训练的XLM-R和RoBERTa,然后在40种语言到英语的平行数据上进行多语言微调。我们发现该模型能够泛化到未见语言的零样本翻译。第二阶段,我们利用这种泛化能力,从单语数据集中生成合成平行数据,随后通过连续轮次的双向反向翻译进行训练。我们将此方法命名为EcXTra(以英语为中心的跨语言迁移)。该方法概念上简洁,全程仅使用标准交叉熵目标函数,且为数据驱动,依次利用辅助平行数据和单语数据。我们在7种低资源语言上评估了无监督NMT结果,发现每轮反向翻译训练进一步优化了双向翻译性能。最终,单个EcXTra训练模型在所有翻译方向上均取得了具有竞争力的翻译表现,尤其在英语到哈萨克语方向上创造了新的最佳结果(BLEU值从10.4提升至22.9)。