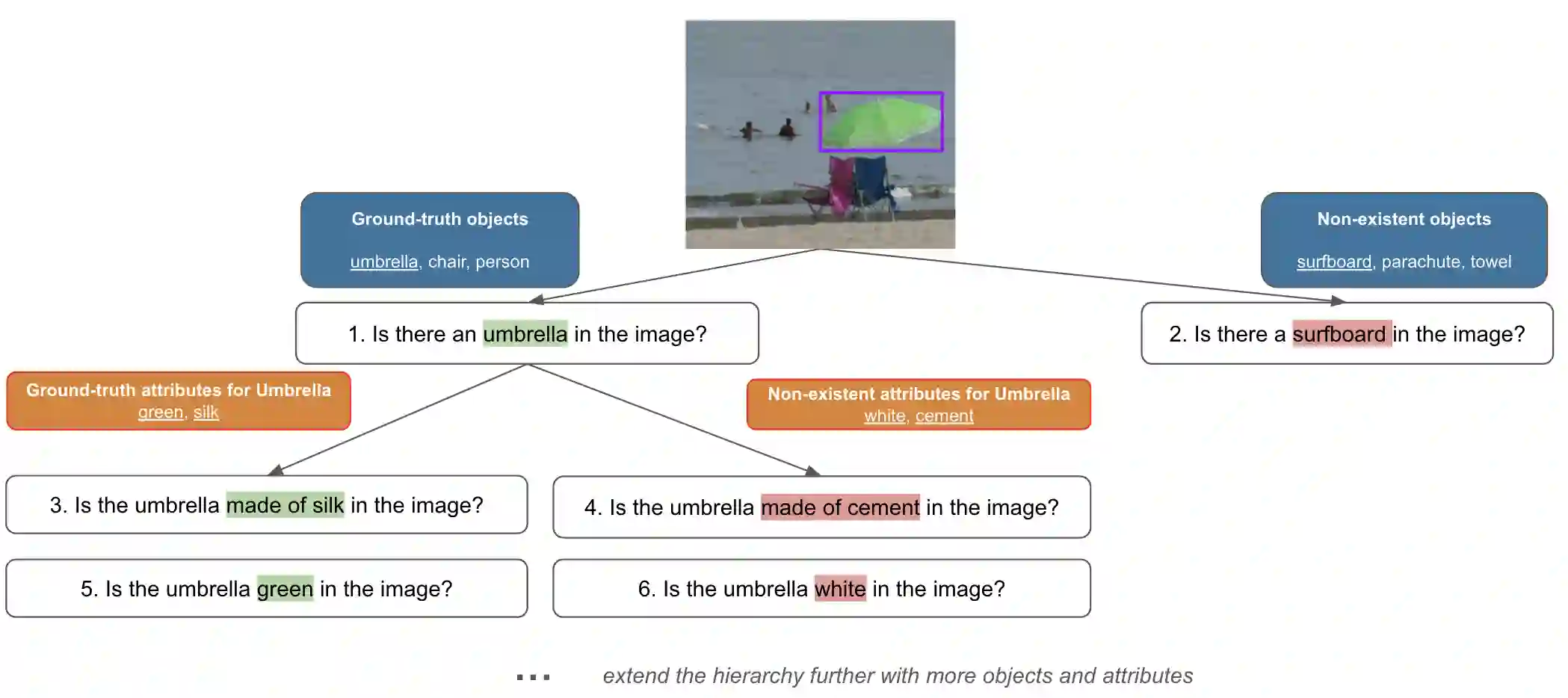
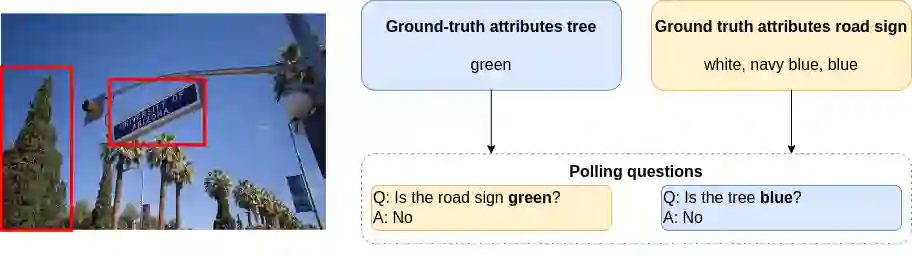
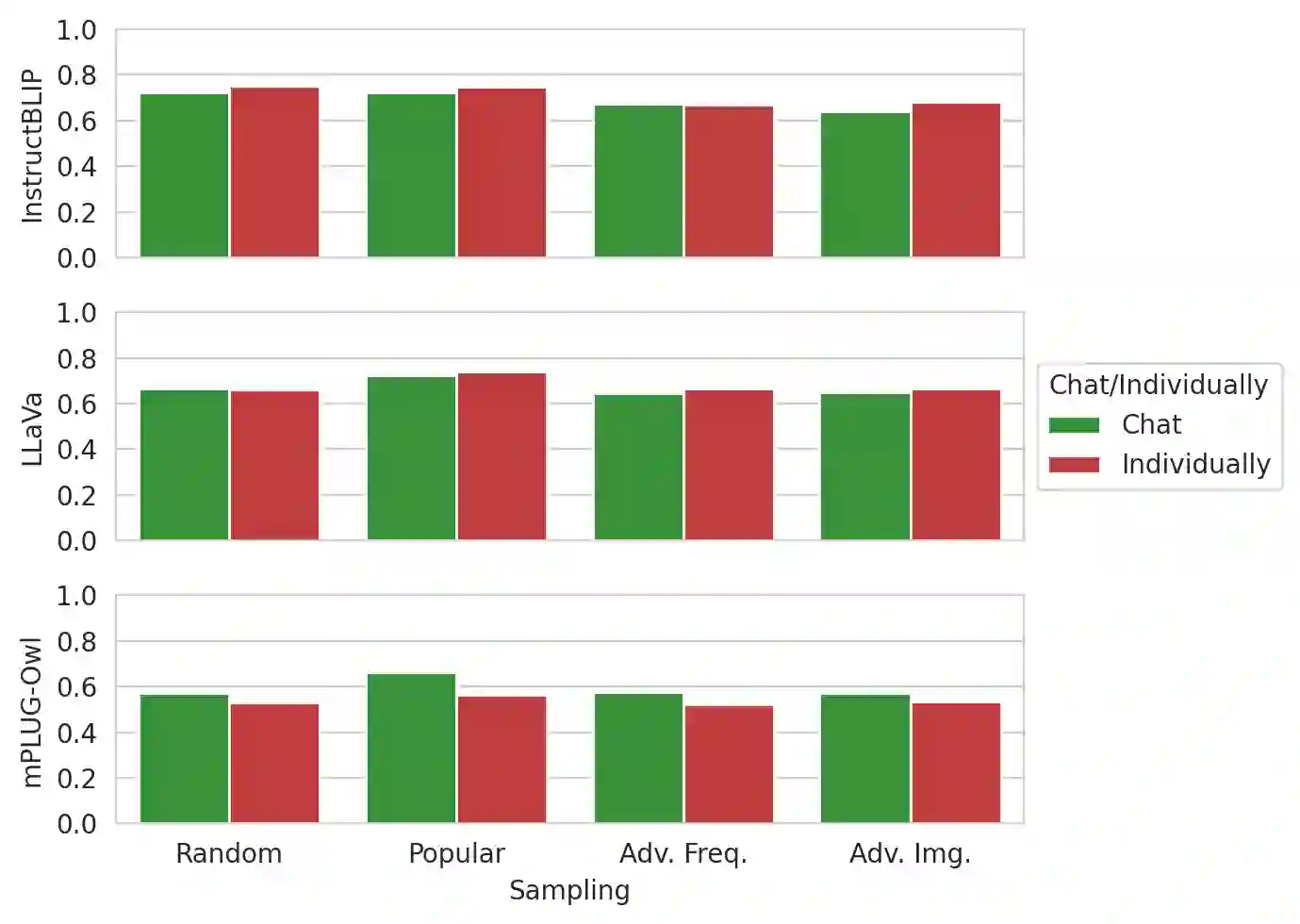
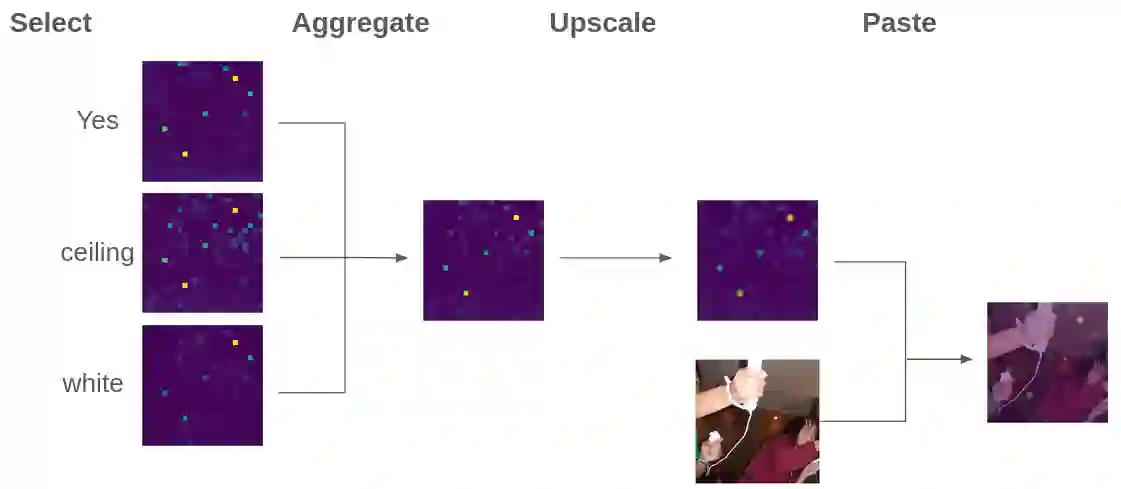
By leveraging both texts and images, large vision language models (LVLMs) have shown significant progress in various multi-modal tasks. Nevertheless, these models often suffer from hallucinations, e.g., they exhibit inconsistencies between the visual input and the textual output. To address this, we propose H-POPE, a coarse-to-fine-grained benchmark that systematically assesses hallucination in object existence and attributes. Our evaluation shows that models are prone to hallucinations on object existence, and even more so on fine-grained attributes. We further investigate whether these models rely on visual input to formulate the output texts.
翻译:通过融合文本与图像信息,大型视觉语言模型(LVLMs)在多模态任务中展现出显著进展。然而,这些模型常出现幻觉现象,例如在视觉输入与文本输出之间表现出不一致性。为此,我们提出H-POPE——一个从粗粒度到细粒度的基准测试框架,用于系统评估对象存在性及属性层面的幻觉问题。实验评估表明,现有模型在对象存在性判断上易产生幻觉,而在细粒度属性识别中该现象更为显著。我们进一步探究了这些模型是否依赖视觉输入来生成文本输出。