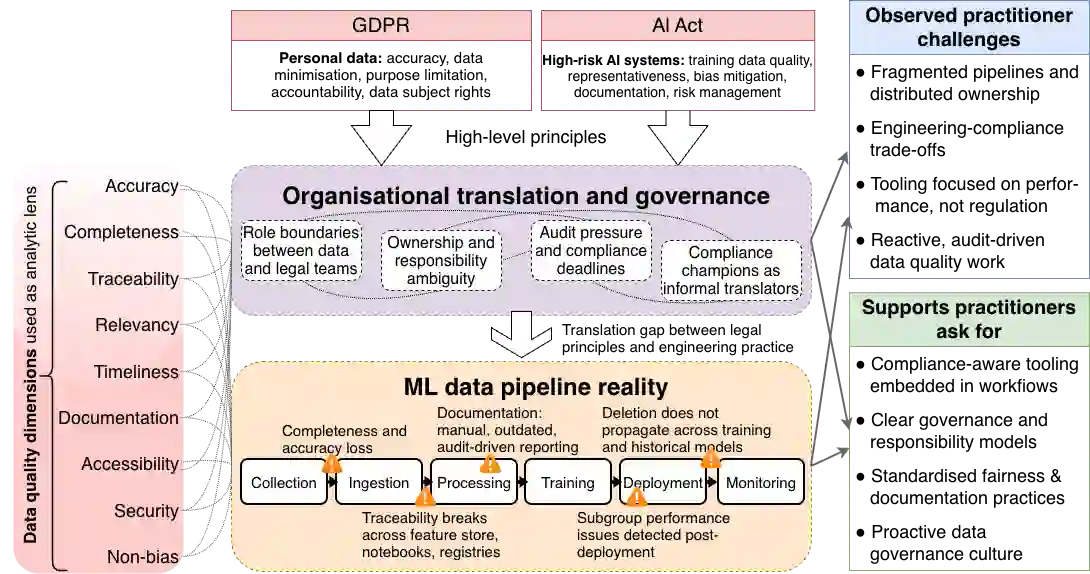
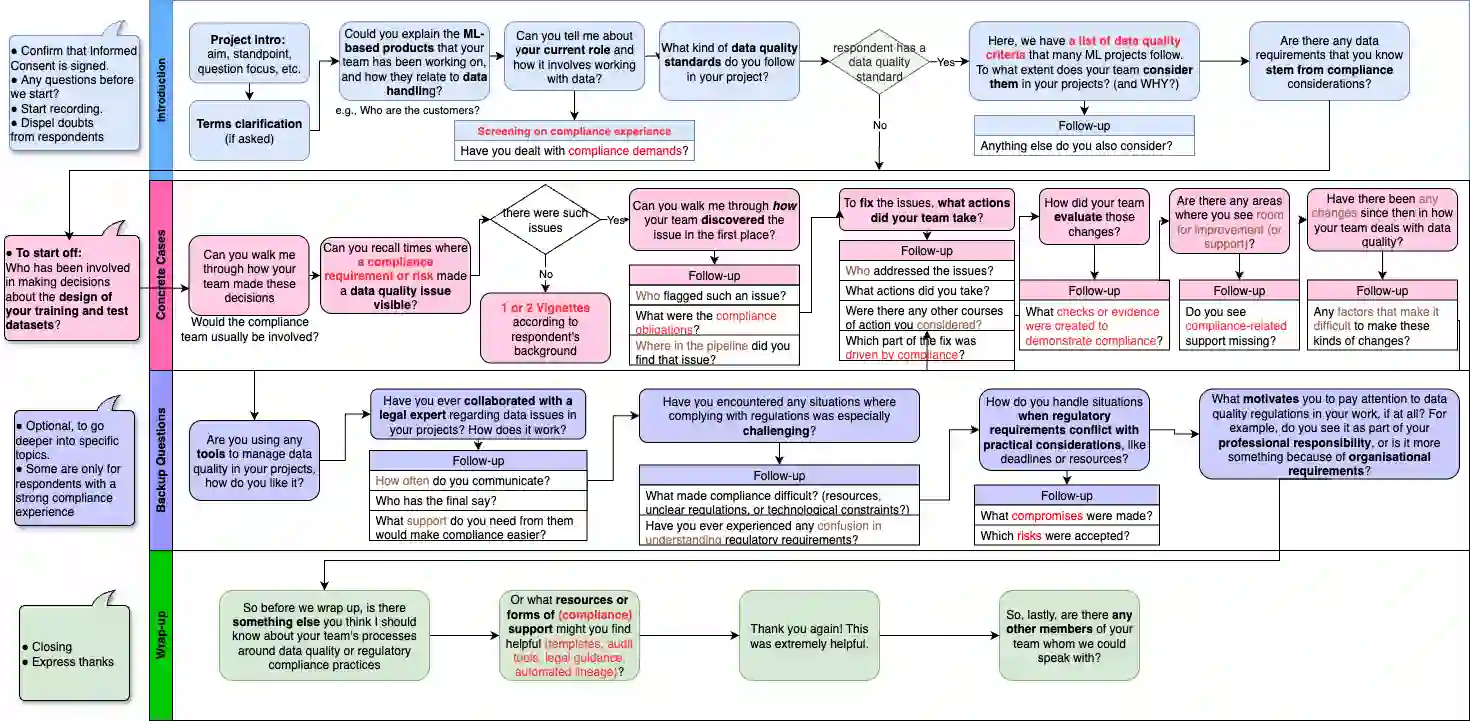
Ensuring data quality in machine learning (ML) systems has become increasingly complex as regulatory requirements expand. In the European Union (EU), frameworks such as the General Data Protection Regulation (GDPR) and the Artificial Intelligence Act (AI Act) articulate data quality requirements that closely parallel technical concerns in ML practice, while also extending to legal obligations related to accountability, risk management, and human rights protection. This paper presents a qualitative interview study with EU-based data practitioners working on ML systems in regulated contexts. Through semi-structured interviews, we investigate how practitioners interpret regulatory-aligned data quality, the challenges they encounter, and the supports they identify as necessary. Our findings reveal persistent gaps between legal principles and engineering workflows, fragmentation across data pipelines, limitations of existing tools, unclear responsibility boundaries between technical and legal teams, and a tendency toward reactive, audit-driven quality practices. We also identify practitioners' needs for compliance-aware tooling, clearer governance structures, and cultural shifts toward proactive data governance.
翻译:随着监管要求的扩展,确保机器学习(ML)系统中的数据质量变得日益复杂。在欧盟(EU),《通用数据保护条例》(GDPR)和《人工智能法案》(AI Act)等框架明确了与ML实践技术关切高度契合的数据质量要求,同时延伸至涉及问责制、风险管理和人权保护的法律义务。本文通过对在受监管环境中从事ML系统工作的欧盟数据实践者进行定性访谈研究。通过半结构化访谈,我们探究了实践者如何理解符合监管要求的数据质量、他们遇到的挑战以及他们认为必要的支持措施。我们的研究揭示了法律原则与工程工作流程之间持续存在的鸿沟、数据管道各环节的碎片化、现有工具的局限性、技术团队与法律团队之间模糊的责任边界,以及倾向于被动、审计驱动的质量实践模式。我们还识别出实践者对合规感知工具、更清晰的治理结构以及向主动数据治理文化转变的需求。