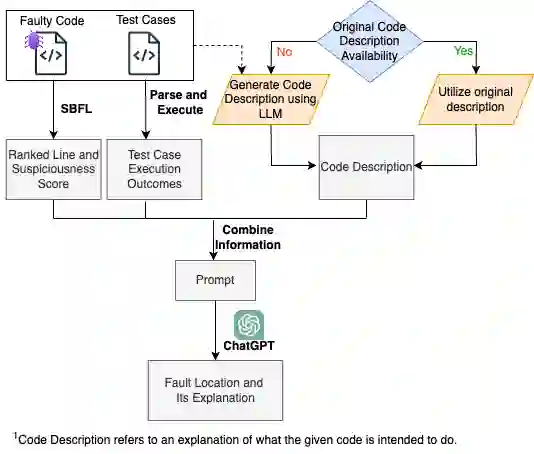
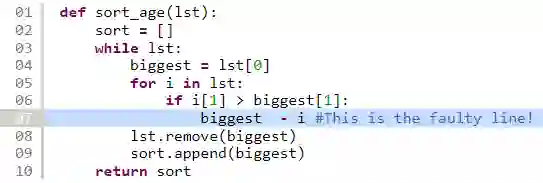
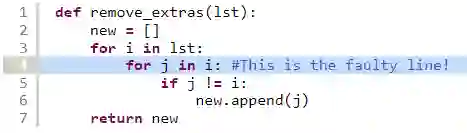
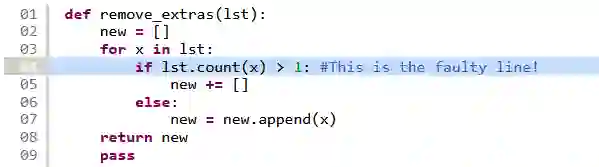
Fault localization is a critical process that involves identifying specific program elements responsible for program failures. Manually pinpointing these elements, such as classes, methods, or statements, which are associated with a fault is laborious and time-consuming. To overcome this challenge, various fault localization tools have been developed. These tools typically generate a ranked list of suspicious program elements. However, this information alone is insufficient. A prior study emphasized that automated fault localization should offer a rationale. In this study, we investigate the step-by-step reasoning for explainable fault localization. We explore the potential of Large Language Models (LLM) in assisting developers in reasoning about code. We proposed FuseFL that utilizes several combinations of information to enhance the LLM results which are spectrum-based fault localization results, test case execution outcomes, and code description (i.e., explanation of what the given code is intended to do). We conducted our investigation using faulty code from Refactory dataset. First, we evaluate the performance of the automated fault localization. Our results demonstrate a more than 30% increase in the number of successfully localized faults at Top-1 compared to the baseline. To evaluate the explanations generated by FuseFL, we create a dataset of human explanations that provide step-by-step reasoning as to why specific lines of code are considered faulty. This dataset consists of 324 faulty code files, along with explanations for 600 faulty lines. Furthermore, we also conducted human studies to evaluate the explanations. We found that for 22 out of the 30 randomly sampled cases, FuseFL generated correct explanations.
翻译:故障定位是一个关键过程,涉及识别导致程序失败的特定程序元素。手动定位与故障相关的类、方法或语句等元素既费力又耗时。为克服这一挑战,已开发出多种故障定位工具。这些工具通常生成可疑程序元素的排序列表,但仅凭这些信息并不足够。先前的研究强调,自动化故障定位应提供推理依据。在本研究中,我们探讨了可解释故障定位的逐步推理方法。我们探索利用大型语言模型(LLM)辅助开发者进行代码推理的潜力。我们提出了FuseFL,该模型利用多种信息组合(包括基于频谱的故障定位结果、测试用例执行结果和代码描述,即对给定代码预期功能的解释)来增强LLM的表现。我们使用Refactory数据集中的故障代码开展研究。首先,我们评估了自动化故障定位的性能。结果表明,与基线相比,成功定位的故障数在Top-1位置上提升了30%以上。为评估FuseFL生成的解释,我们创建了一个人工解释数据集,提供关于为何特定代码行被视为故障的逐步推理。该数据集包含324个故障代码文件及600个故障行的解释。此外,我们还进行了人工研究以评估解释质量。发现30个随机采样案例中,有22个案例的FuseFL生成了正确的解释。