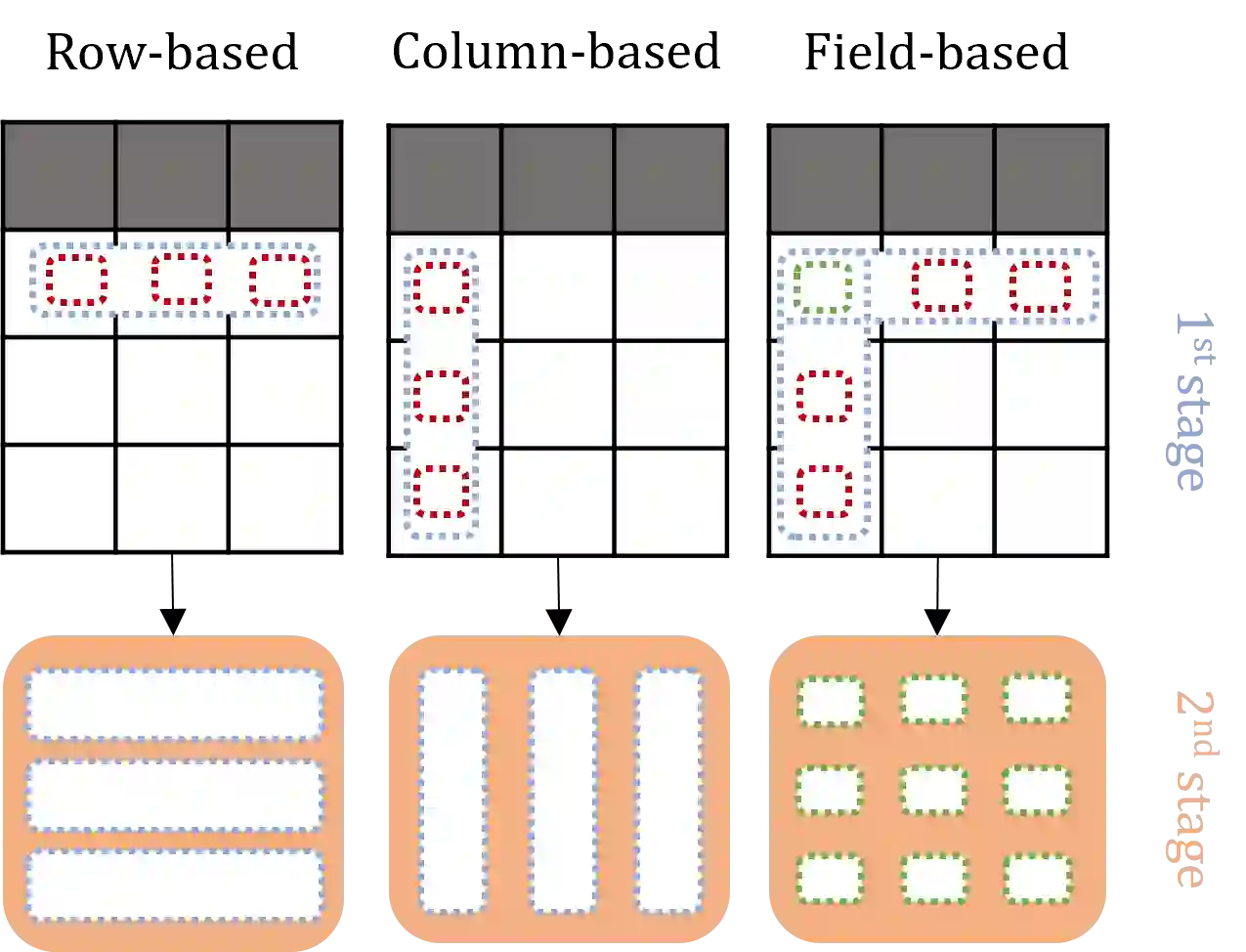
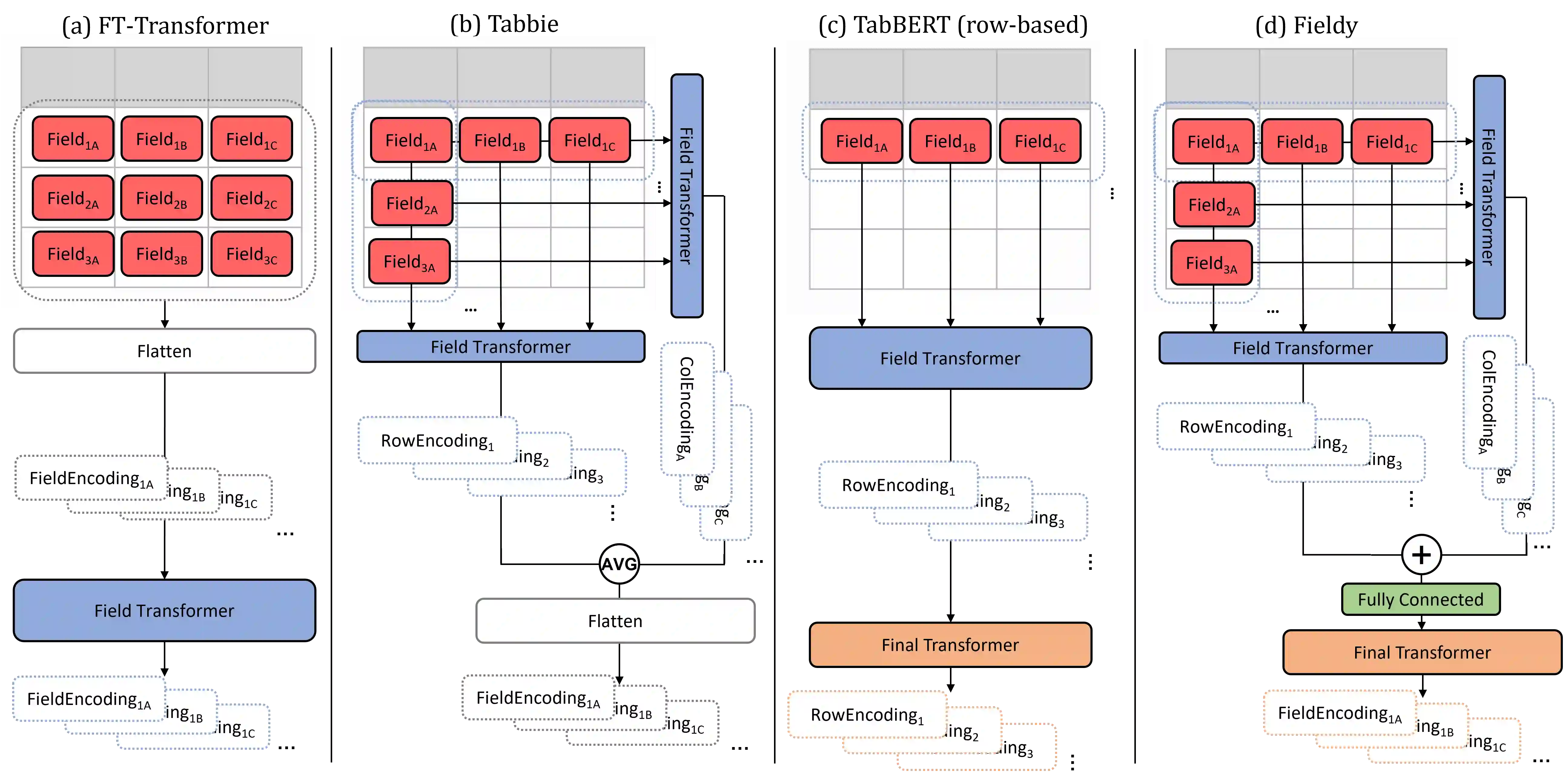
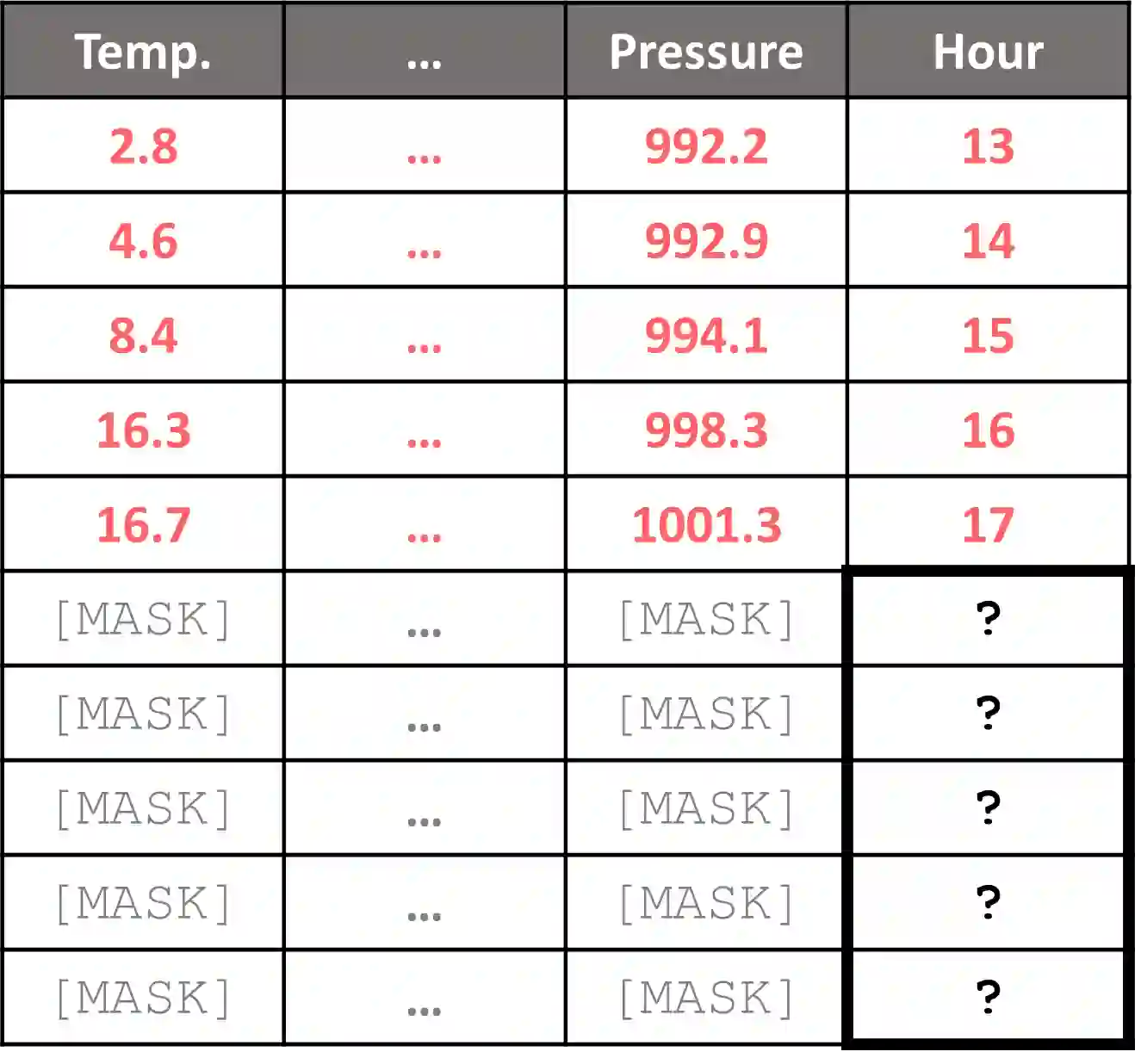
Tabular data is ubiquitous in many real-life systems. In particular, time-dependent tabular data, where rows are chronologically related, is typically used for recording historical events, e.g., financial transactions, healthcare records, or stock history. Recently, hierarchical variants of the attention mechanism of transformer architectures have been used to model tabular time-series data. At first, rows (or columns) are encoded separately by computing attention between their fields. Subsequently, encoded rows (or columns) are attended to one another to model the entire tabular time-series. While efficient, this approach constrains the attention granularity and limits its ability to learn patterns at the field-level across separate rows, or columns. We take a first step to address this gap by proposing Fieldy, a fine-grained hierarchical model that contextualizes fields at both the row and column levels. We compare our proposal against state of the art models on regression and classification tasks using public tabular time-series datasets. Our results show that combining row-wise and column-wise attention improves performance without increasing model size. Code and data are available at https://github.com/raphaaal/fieldy.
翻译:表格数据在众多现实系统中普遍存在。特别是时间相关的表格数据,其中行与行之间按时间顺序关联,通常用于记录历史事件,例如金融交易、医疗记录或股票历史。最近,Transformer架构注意力机制的分层变体已被用于建模表格时序数据。首先,通过计算其字段之间的注意力,分别对行(或列)进行编码。随后,编码后的行(或列)相互关注以建模整个表格时序。尽管高效,但这种方法限制了注意力的粒度,并削弱了其跨不同行或列在字段级别学习模式的能力。我们通过提出Fieldy迈出了解决这一差距的第一步,这是一种细粒度的分层模型,可在行和列级别对字段进行上下文建模。我们使用公开的表格时序数据集,在回归和分类任务上将我们的方案与最先进的模型进行比较。结果表明,结合行向和列向注意力可在不增加模型规模的情况下提升性能。代码和数据可在https://github.com/raphaaal/fieldy获取。