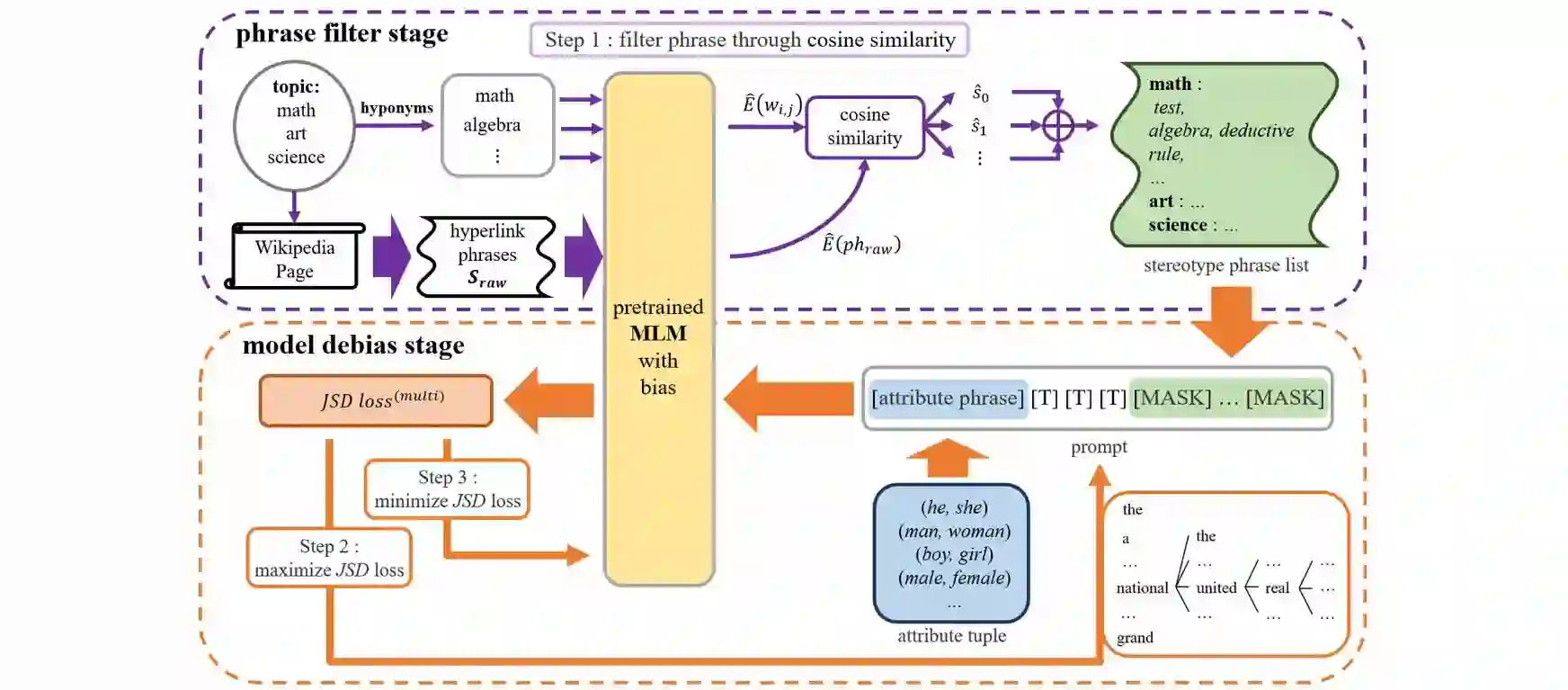
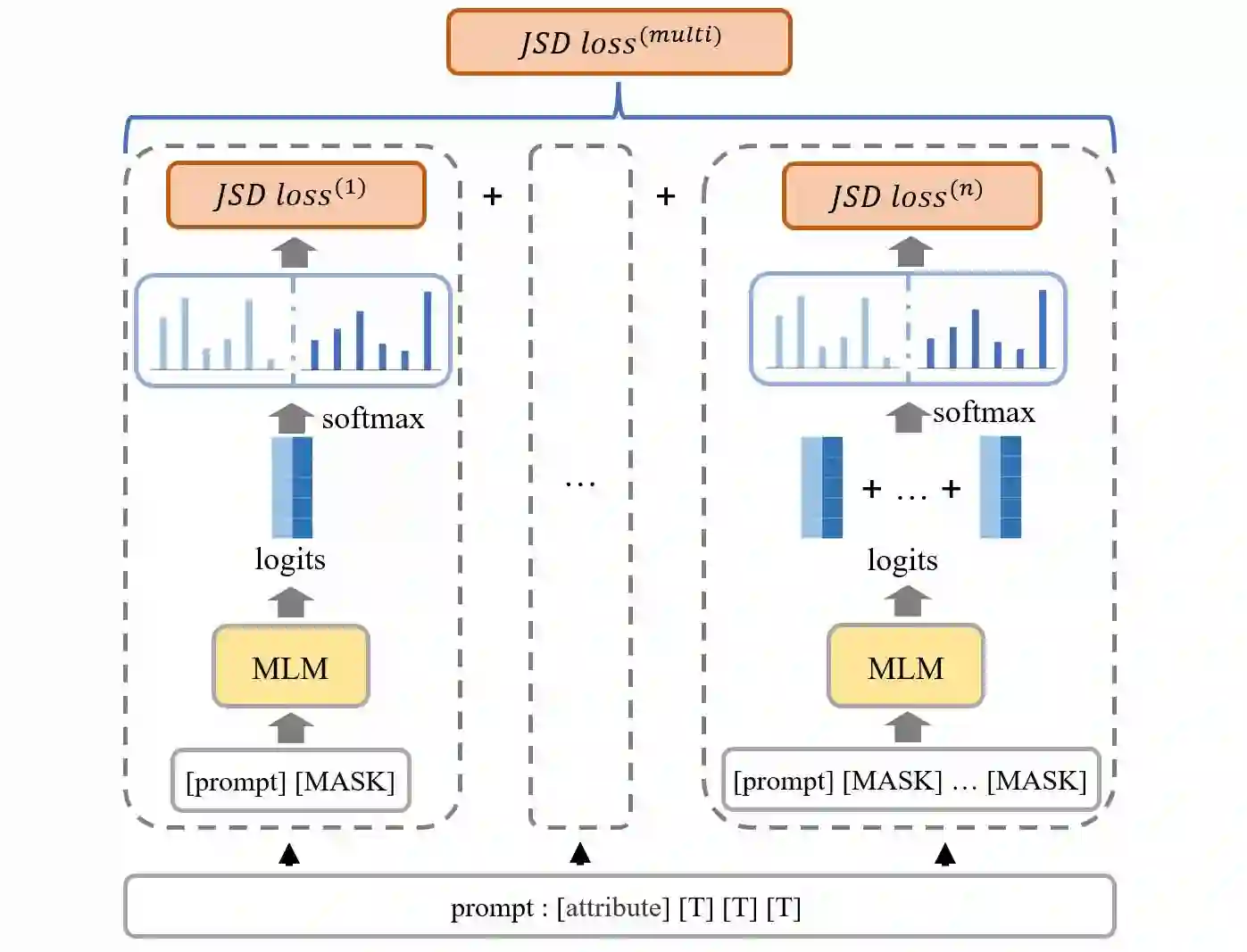
The social biases and unwelcome stereotypes revealed by pretrained language models are becoming obstacles to their application. Compared to numerous debiasing methods targeting word level, there has been relatively less attention on biases present at phrase level, limiting the performance of debiasing in discipline domains. In this paper, we propose an automatic multi-token debiasing pipeline called \textbf{General Phrase Debiaser}, which is capable of mitigating phrase-level biases in masked language models. Specifically, our method consists of a \textit{phrase filter stage} that generates stereotypical phrases from Wikipedia pages as well as a \textit{model debias stage} that can debias models at the multi-token level to tackle bias challenges on phrases. The latter searches for prompts that trigger model's bias, and then uses them for debiasing. State-of-the-art results on standard datasets and metrics show that our approach can significantly reduce gender biases on both career and multiple disciplines, across models with varying parameter sizes.
翻译:预训练语言模型所揭示的社会偏见和不受欢迎的刻板印象正成为其应用的障碍。与众多针对单词层面的去偏方法相比,短语层面存在的偏见受到的关注相对较少,这限制了在专业领域的去偏性能。本文提出一种名为**通用短语去偏器**的自动多词元去偏流水线,能够缓解掩码语言模型中的短语级偏见。具体而言,我们的方法包含两个阶段:一是**短语过滤阶段**,从维基百科页面生成刻板短语;二是**模型去偏阶段**,可在多词元层面消除模型偏见以应对短语带来的偏见挑战。后一阶段通过搜索触发模型偏见的提示语,并利用这些提示语进行去偏。在标准数据集和指标上的最新结果表明,我们的方法能够显著减少职业及多学科领域中的性别偏见,且在不同参数规模的模型上均有效。