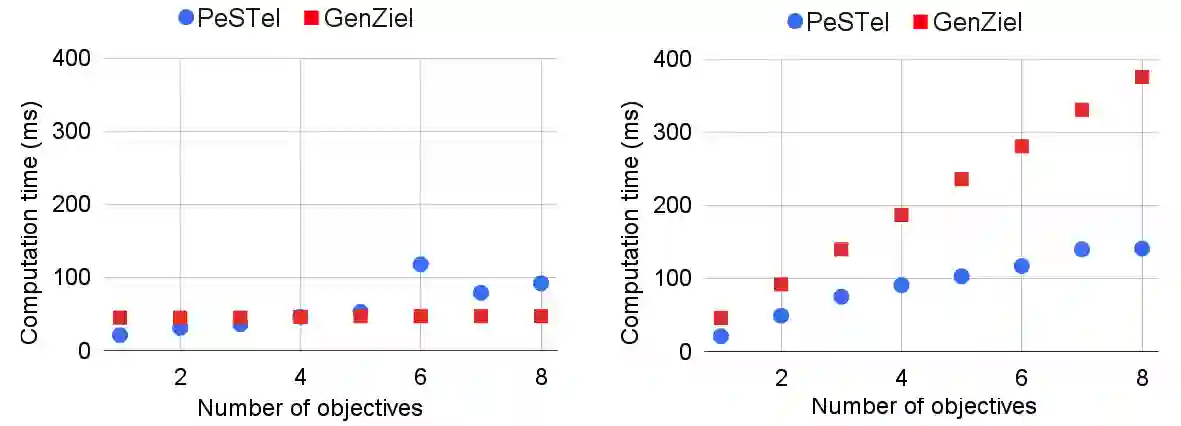
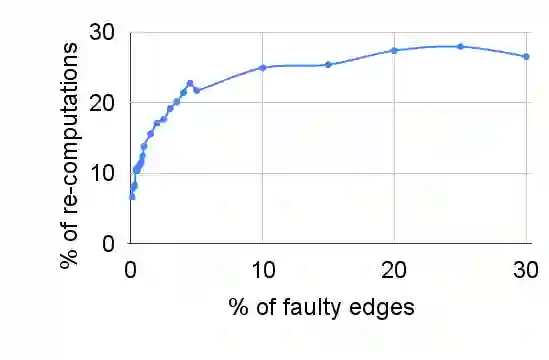
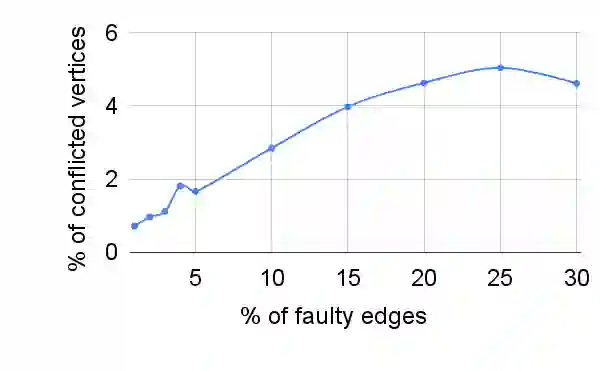
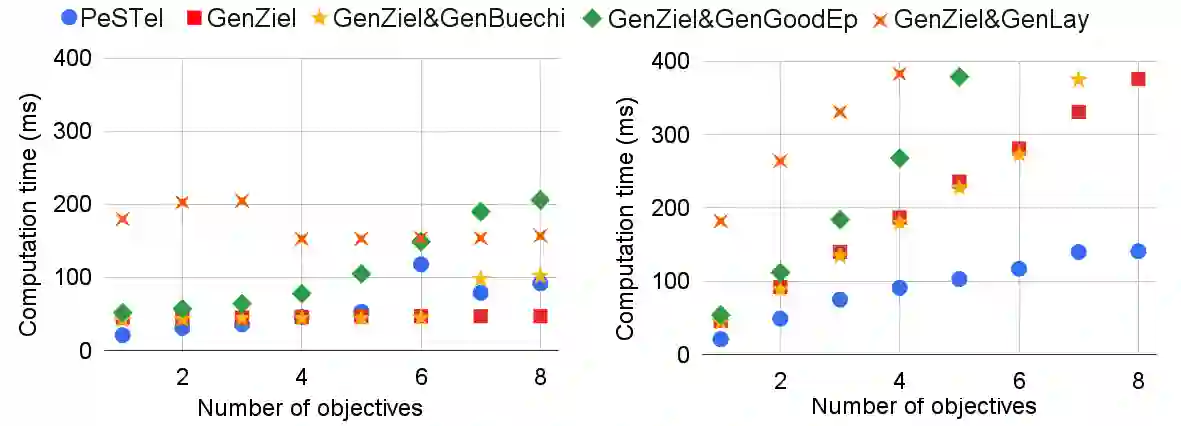
We present a novel method to compute \emph{permissive winning strategies} in two-player games over finite graphs with $ \omega $-regular winning conditions. Given a game graph $G$ and a parity winning condition $\Phi$, we compute a \emph{winning strategy template} $\Psi$ that collects an infinite number of winning strategies for objective $\Phi$ in a concise data structure. We use this new representation of sets of winning strategies to tackle two problems arising from applications of two-player games in the context of cyber-physical system design -- (i) \emph{incremental synthesis}, i.e., adapting strategies to newly arriving, \emph{additional} $\omega$-regular objectives $\Phi'$, and (ii) \emph{fault-tolerant control}, i.e., adapting strategies to the occasional or persistent unavailability of actuators. The main features of our strategy templates -- which we utilize for solving these challenges -- are their easy computability, adaptability, and compositionality. For \emph{incremental synthesis}, we empirically show on a large set of benchmarks that our technique vastly outperforms existing approaches if the number of added specifications increases. While our method is not complete, our prototype implementation returns the full winning region in all 1400 benchmark instances, i.e., handling a large problem class efficiently in practice.
翻译:我们提出一种新颖方法,用于计算有限图上的两人博弈中关于ω-正则获胜条件的*许可赢得策略*。给定一个博弈图G和一个奇偶获胜条件Φ,我们计算一个*赢得策略模板*Ψ,该模板以一种简洁的数据结构收集针对目标Φ的无限多个赢得策略。我们利用这种新的赢得策略集表示来应对两人博弈在信息物理系统设计应用背景下产生的两个问题——(i)*增量式合成*,即使策略适应新出现的*额外*ω-正则目标Φ',以及(ii)*容错控制*,即使策略适应执行器偶尔或持续不可用的情况。我们策略模板的主要特征——我们利用这些特征来解决上述挑战——在于其易于计算性、适应性和组合性。对于*增量式合成*,我们在大量基准测试上通过实验表明,当添加的规约数量增加时,我们的技术显著优于现有方法。尽管我们的方法并非完备,但我们的原型实现在全部1400个基准测试实例中均返回了完整的获胜区域,即在实际中高效处理了一大类问题。