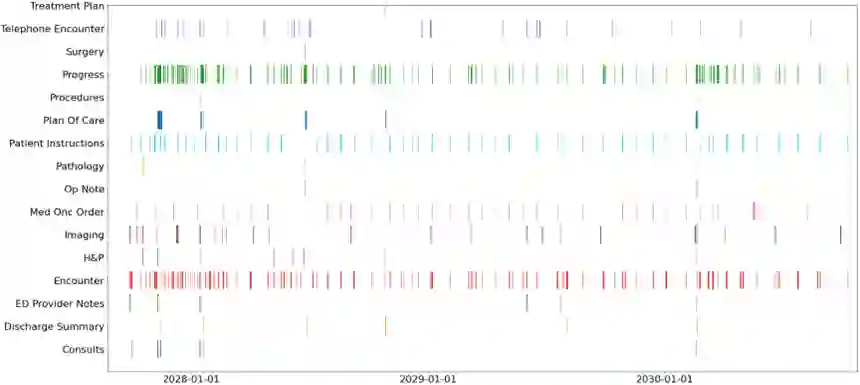
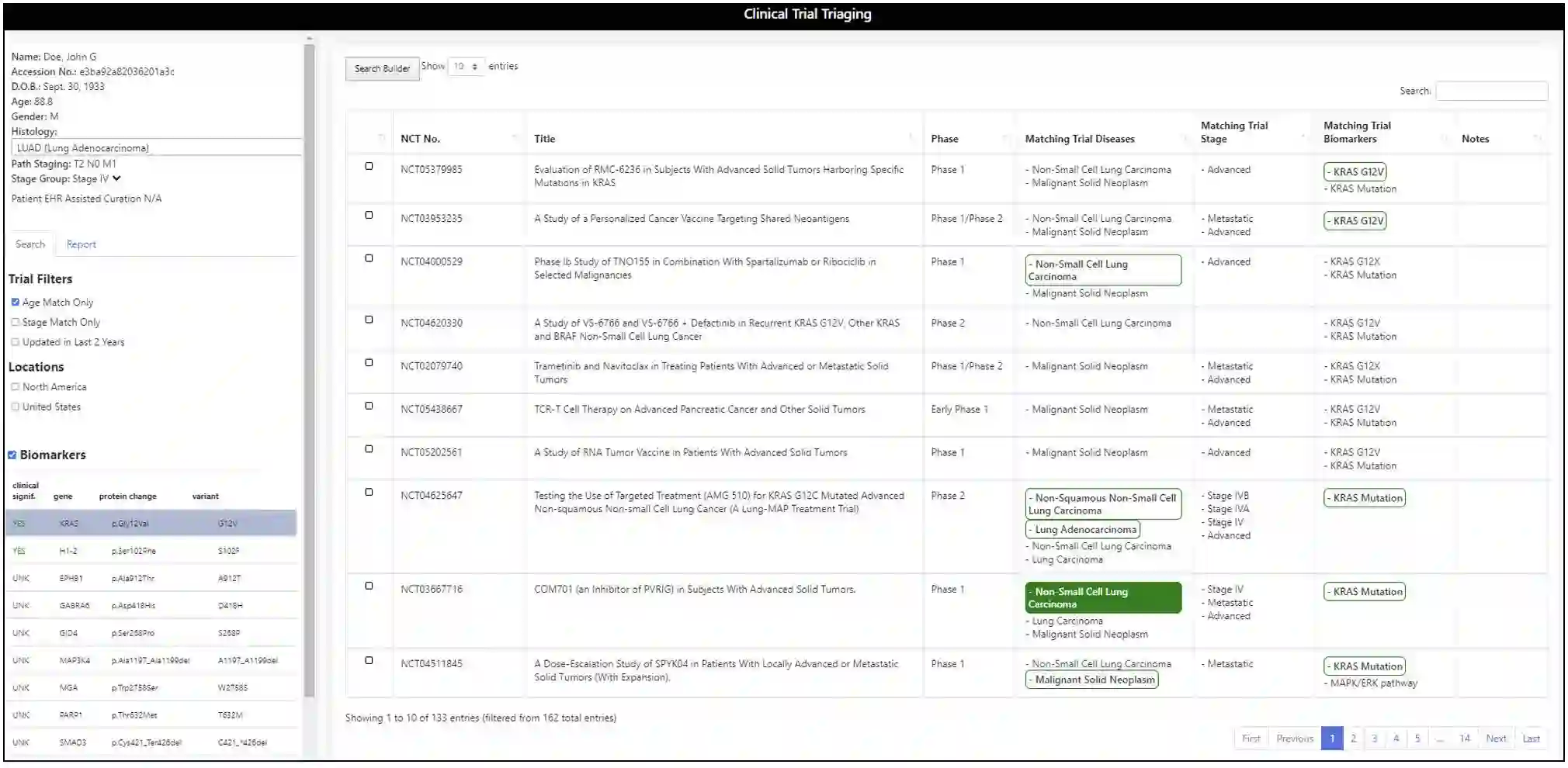
Clinical trial matching is a key process in health delivery and discovery. In practice, it is plagued by overwhelming unstructured data and unscalable manual processing. In this paper, we conduct a systematic study on scaling clinical trial matching using large language models (LLMs), with oncology as the focus area. Our study is grounded in a clinical trial matching system currently in test deployment at a large U.S. health network. Initial findings are promising: out of box, cutting-edge LLMs, such as GPT-4, can already structure elaborate eligibility criteria of clinical trials and extract complex matching logic (e.g., nested AND/OR/NOT). While still far from perfect, LLMs substantially outperform prior strong baselines and may serve as a preliminary solution to help triage patient-trial candidates with humans in the loop. Our study also reveals a few significant growth areas for applying LLMs to end-to-end clinical trial matching, such as context limitation and accuracy, especially in structuring patient information from longitudinal medical records.
翻译:临床试验匹配是医疗健康服务与研究中的关键环节。实践中,该过程面临非结构化数据庞杂、人工处理难以规模化等困境。本文以肿瘤学为目标领域,系统研究如何运用大语言模型(LLMs)实现临床试验匹配的规模化。研究立足美国某大型医疗网络当前试运行的临床试验匹配系统。初步结果令人鼓舞:即使采用开箱即用的尖端大语言模型(如GPT-4),已能结构化处理复杂的临床试验筛选标准,并抽取嵌套逻辑运算(如AND/OR/NOT)。尽管尚不完美,但大语言模型的表现显著优于既往强基准模型,可作为人机协同筛查患者-试验候选对象的初步方案。研究同时揭示了将大语言模型应用于端到端临床试验匹配的重大发展方向,包括上下文限制与准确性优化,特别是从纵向病历中结构化提取患者信息等关键挑战。