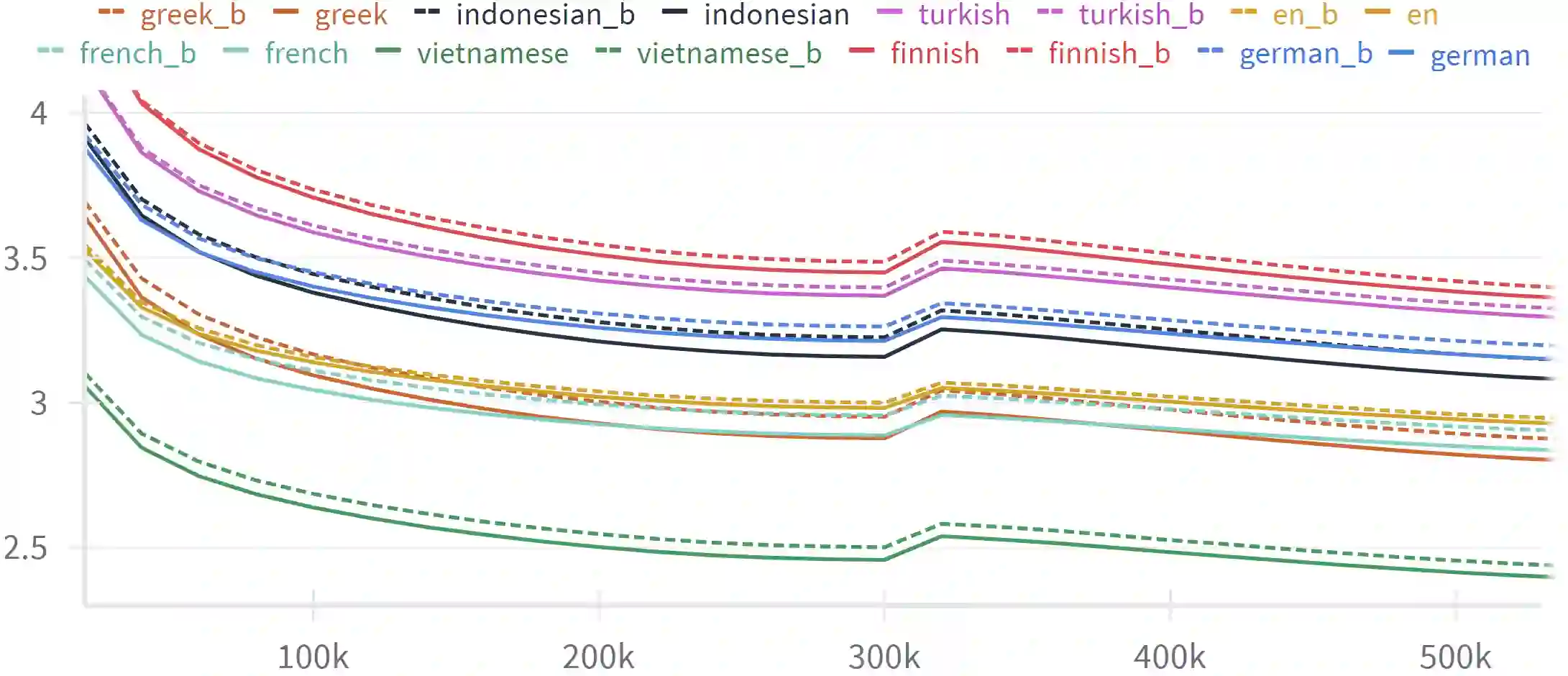
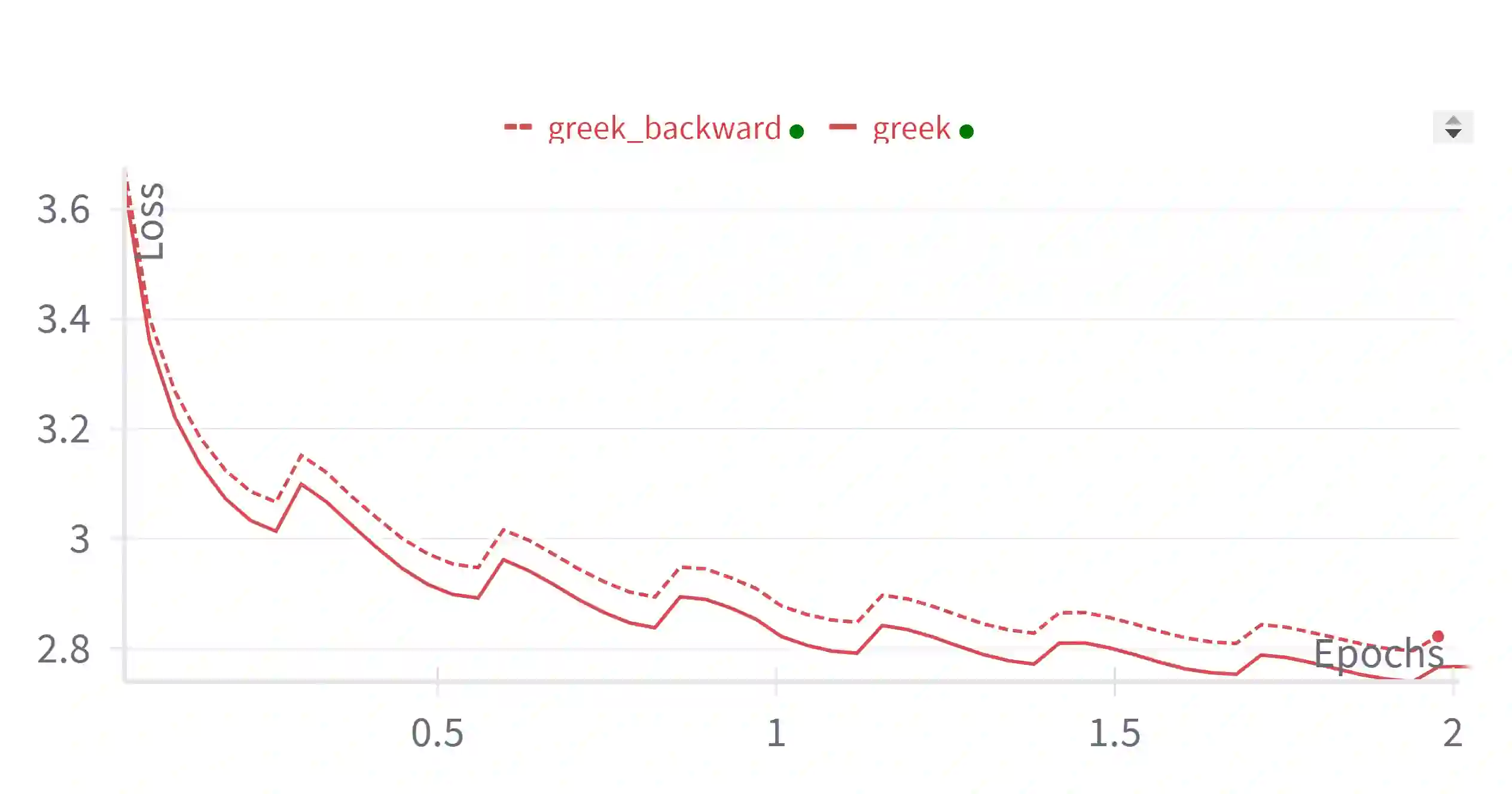
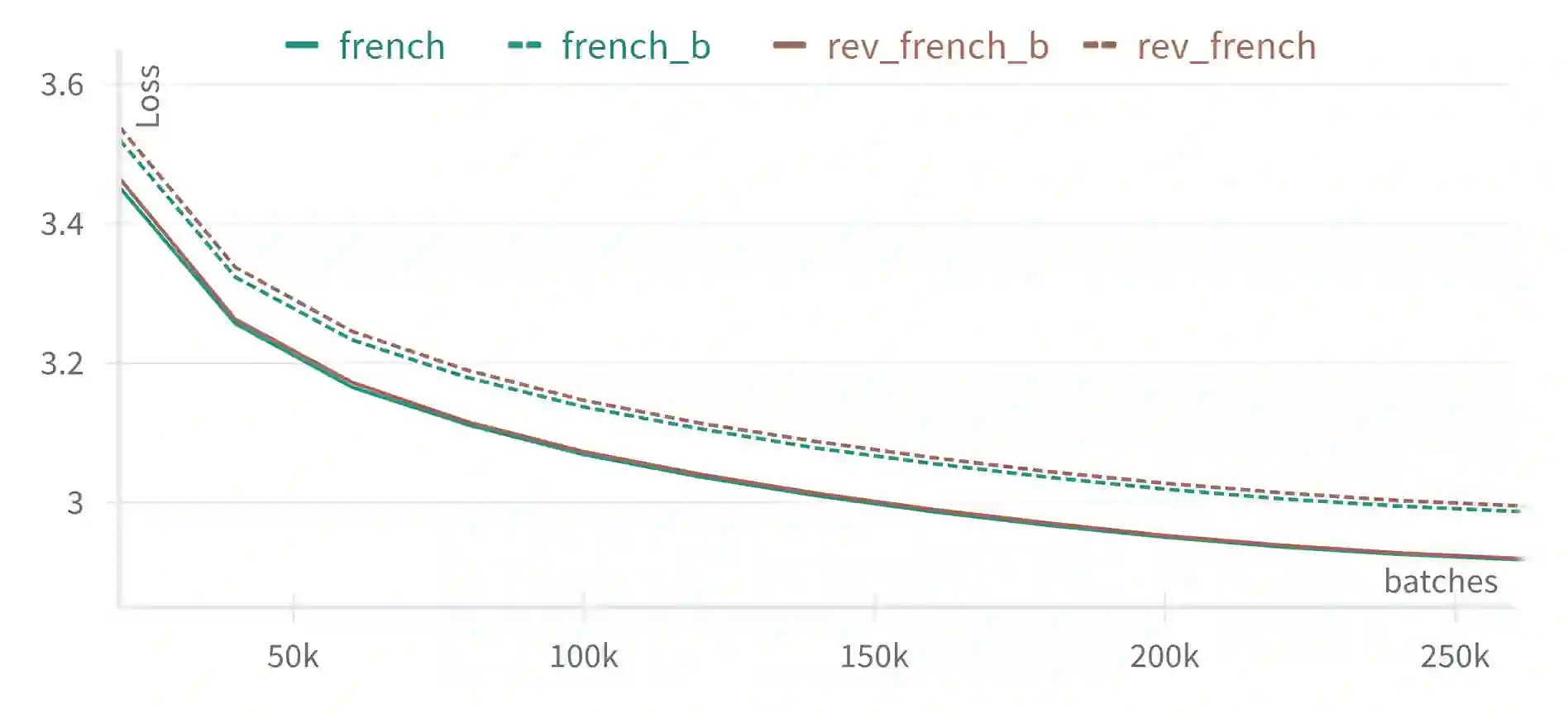
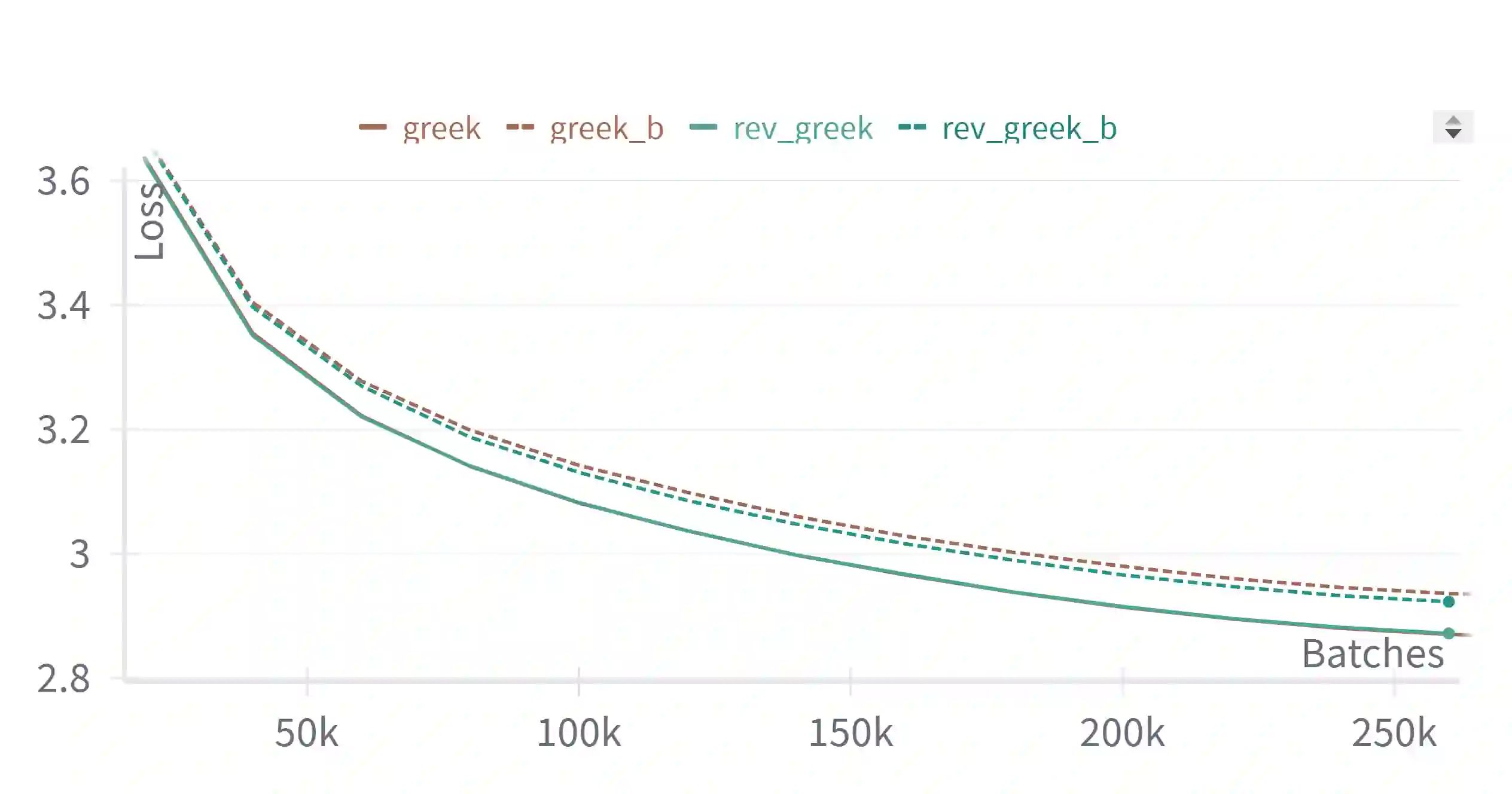
We study the probabilistic modeling performed by Autoregressive Large Language Models (LLMs) through the angle of time directionality, addressing a question first raised in (Shannon, 1951). For large enough models, we empirically find a time asymmetry in their ability to learn natural language: a difference in the average log-perplexity when trying to predict the next token versus when trying to predict the previous one. This difference is at the same time subtle and very consistent across various modalities (language, model size, training time, ...). Theoretically, this is surprising: from an information-theoretic point of view, there should be no such difference. We provide a theoretical framework to explain how such an asymmetry can appear from sparsity and computational complexity considerations, and outline a number of perspectives opened by our results.
翻译:我们通过时间方向性的视角研究自回归大语言模型(LLMs)执行的概率建模,探讨了(Shannon, 1951)首次提出的问题。对于足够大的模型,我们经验性地发现其学习自然语言的能力存在时间不对称性:即模型在预测下一个词元与预测上一个词元时的平均对数困惑度存在差异。这种差异既微妙又高度一致地存在于各种模态中(语言、模型规模、训练时长等)。从理论角度看,这一发现令人惊讶:从信息论的观点出发,本不应存在此类差异。我们提出了一个理论框架,从稀疏性与计算复杂度的角度解释这种不对称性如何产生,并概述了我们的研究结果所开启的若干研究方向。