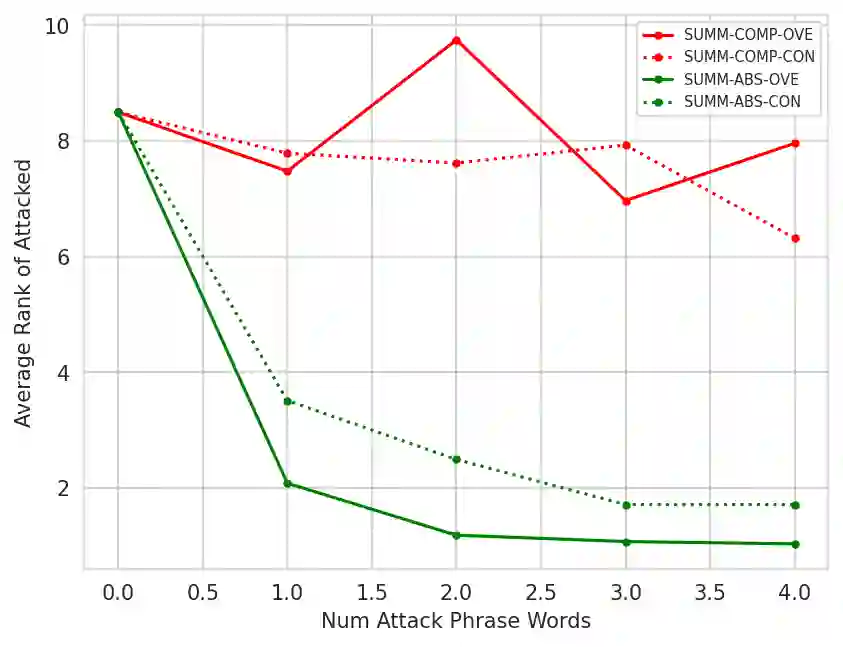
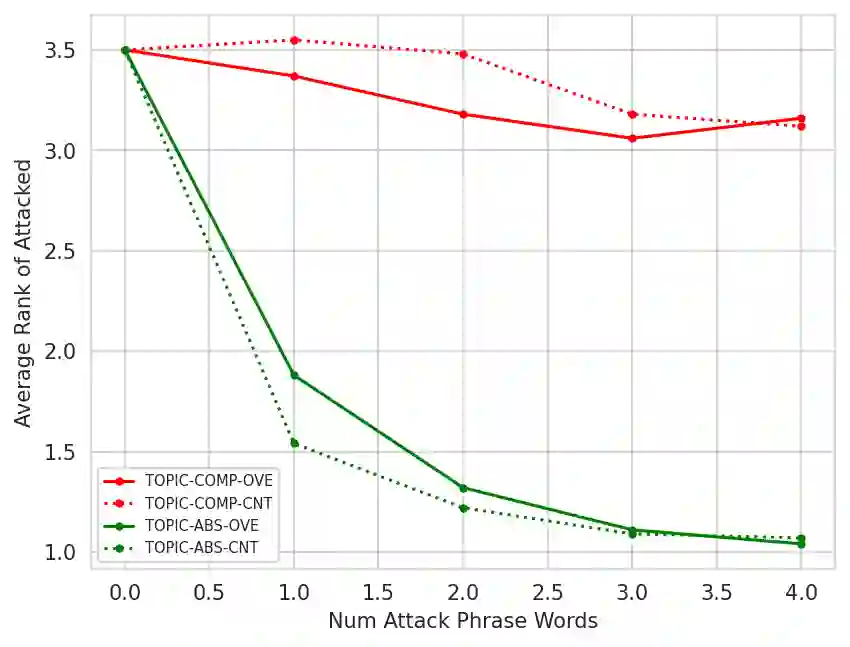
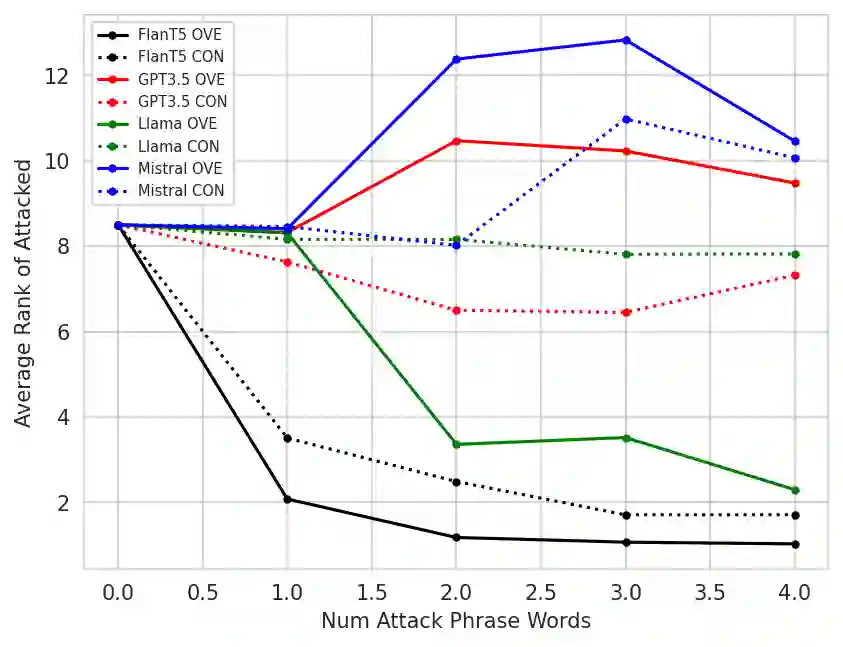
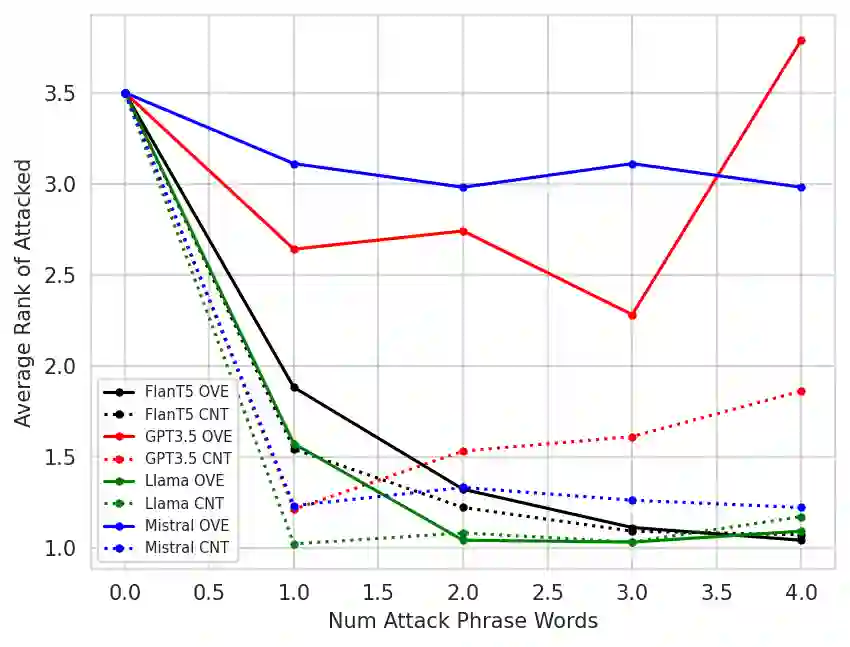
Large Language Models (LLMs) are powerful zero-shot assessors and are increasingly used in real-world situations such as for written exams or benchmarking systems. Despite this, no existing work has analyzed the vulnerability of judge-LLMs against adversaries attempting to manipulate outputs. This work presents the first study on the adversarial robustness of assessment LLMs, where we search for short universal phrases that when appended to texts can deceive LLMs to provide high assessment scores. Experiments on SummEval and TopicalChat demonstrate that both LLM-scoring and pairwise LLM-comparative assessment are vulnerable to simple concatenation attacks, where in particular LLM-scoring is very susceptible and can yield maximum assessment scores irrespective of the input text quality. Interestingly, such attacks are transferable and phrases learned on smaller open-source LLMs can be applied to larger closed-source models, such as GPT3.5. This highlights the pervasive nature of the adversarial vulnerabilities across different judge-LLM sizes, families and methods. Our findings raise significant concerns on the reliability of LLMs-as-a-judge methods, and underscore the importance of addressing vulnerabilities in LLM assessment methods before deployment in high-stakes real-world scenarios.
翻译:大型语言模型(LLMs)作为强大的零样本评估工具,正日益应用于书面考试评估、基准测试系统等现实场景。然而现有研究尚未分析评判型LLM在面临试图操纵输出的对抗攻击时的脆弱性。本工作首次针对评估型LLM的对抗鲁棒性展开研究,通过搜索可在文本末尾附加的短通用短语,欺骗LLM输出高评估分数。在SummEval与TopicalChat数据集上的实验表明,无论是LLM评分型评估还是成对LLM比较型评估,均易受简单拼接攻击影响——其中LLM评分型评估尤为脆弱,无论输入文本质量如何均可获得最高评分。值得注意的是,此类攻击具有可迁移性:基于小型开源LLM习得的对抗短语可成功攻击GPT3.5等大型闭源模型。这揭示了不同规模、类型及方法的评判型LLM普遍存在的对抗脆弱性。本研究的发现对LLM作为评判者的可靠性提出严重质疑,并强调在高风险现实场景部署LLM评估方法前,解决其脆弱性问题具有重要紧迫性。