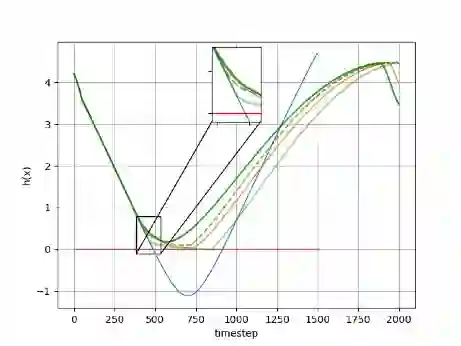
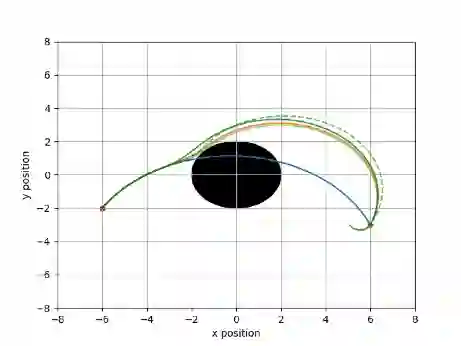
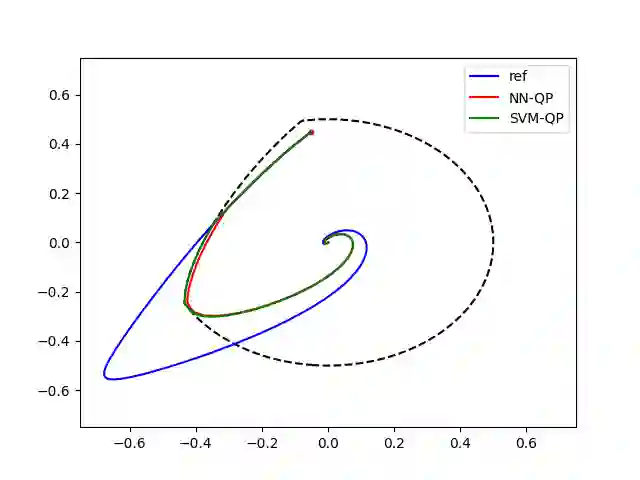
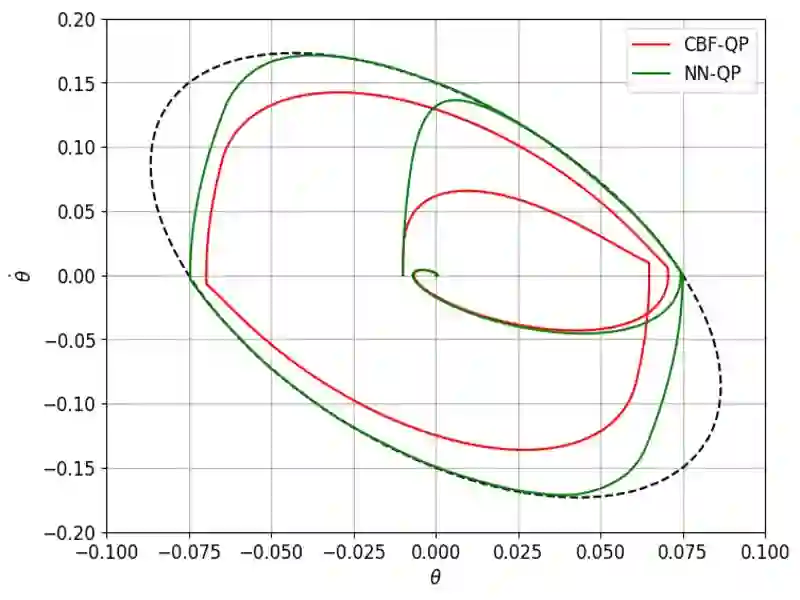
Learning-based approaches are emerging as an effective approach for safety filters for black-box dynamical systems. Existing methods have relied on certificate functions like Control Barrier Functions (CBFs) and Hamilton-Jacobi (HJ) reachability value functions. The primary motivation for our work is the recognition that ultimately, enforcing the safety constraint as a control input constraint at each state is what matters. By focusing on this constraint, we can eliminate dependence on any specific certificate function-based design. To achieve this, we define a discriminating hyperplane that shapes the half-space constraint on control input at each state, serving as a sufficient condition for safety. This concept not only generalizes over traditional safety methods but also simplifies safety filter design by eliminating dependence on specific certificate functions. We present two strategies to learn the discriminating hyperplane: (a) a supervised learning approach, using pre-verified control invariant sets for labeling, and (b) a reinforcement learning (RL) approach, which does not require such labels. The main advantage of our method, unlike conventional safe RL approaches, is the separation of performance and safety. This offers a reusable safety filter for learning new tasks, avoiding the need to retrain from scratch. As such, we believe that the new notion of the discriminating hyperplane offers a more generalizable direction towards designing safety filters, encompassing and extending existing certificate-function-based or safe RL methodologies.
翻译:基于学习的方法正成为黑箱动态系统安全滤波器的一种有效手段。现有方法依赖控制障碍函数(CBFs)和汉密尔顿-雅可比(HJ)可达性价值函数等认证函数。我们工作的主要动机源于认识到:最终,在每个状态将安全约束转化为控制输入约束才是关键。通过专注于这一约束,我们可以消除对任何特定基于认证函数设计的依赖。为实现这一点,我们定义了区分超平面,它在每个状态刻画了控制输入的半空间约束,作为安全性的充分条件。该概念不仅泛化了传统安全方法,还通过消除对特定认证函数的依赖简化了安全滤波器设计。我们提出了两种学习区分超平面的策略:(a)监督学习方法,利用预验证的控制不变集进行标注;(b)强化学习方法,无需此类标注。与传统安全强化学习方法不同,本方法的主要优势在于实现了性能与安全性的分离,从而为学习新任务提供了可复用的安全滤波器,避免了从头重新训练。因此,我们相信区分超平面这一新概念为设计安全滤波器提供了更具泛化性的方向,能够涵盖并扩展现有基于认证函数或安全强化学习的方法。