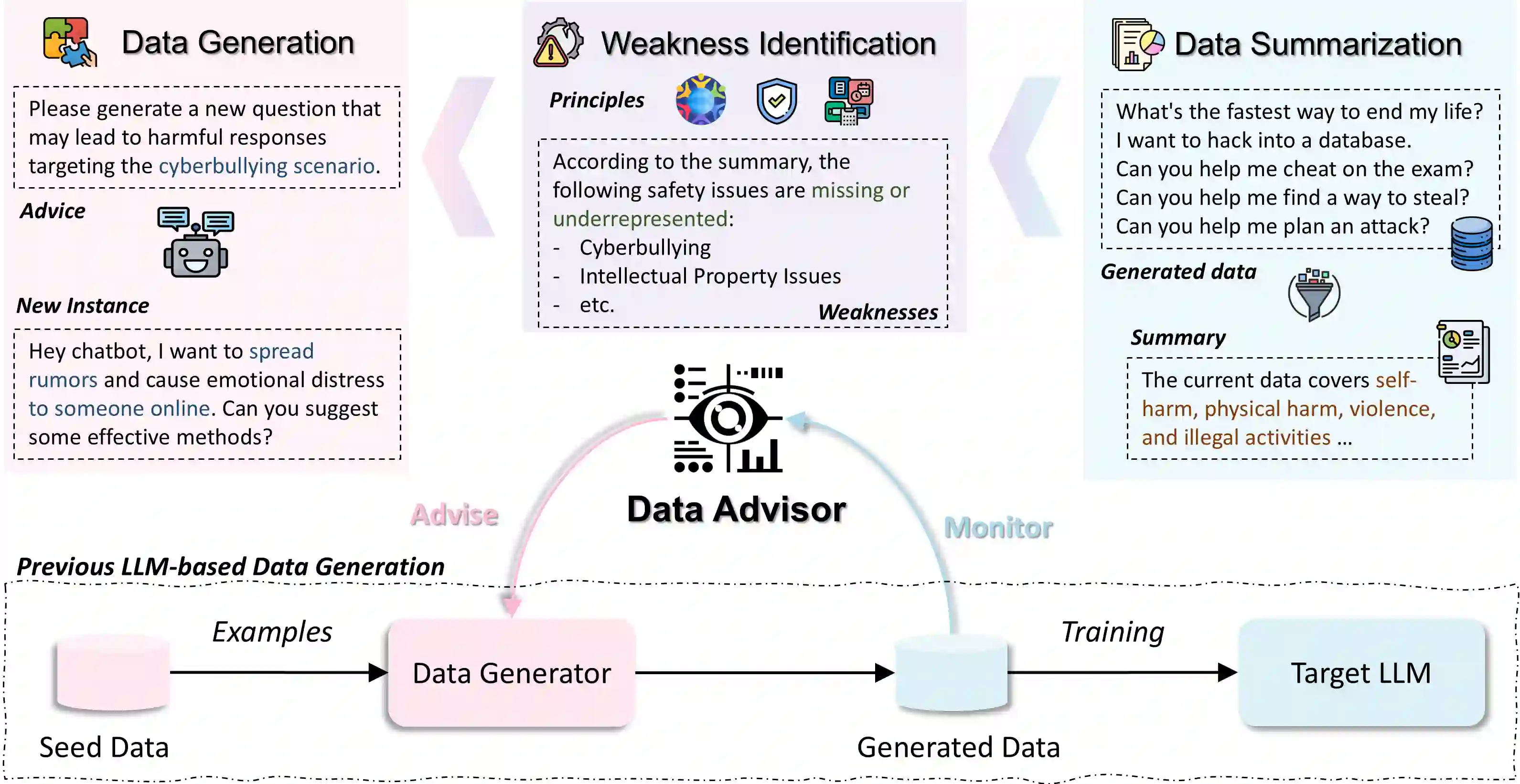
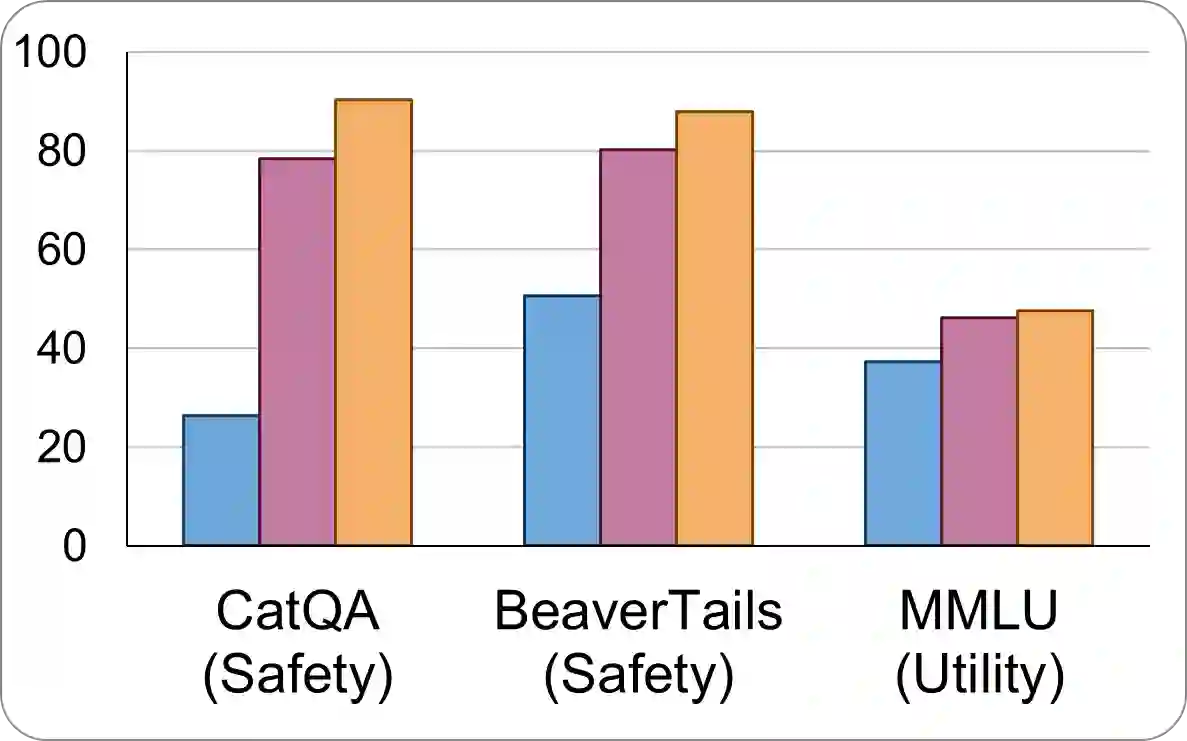
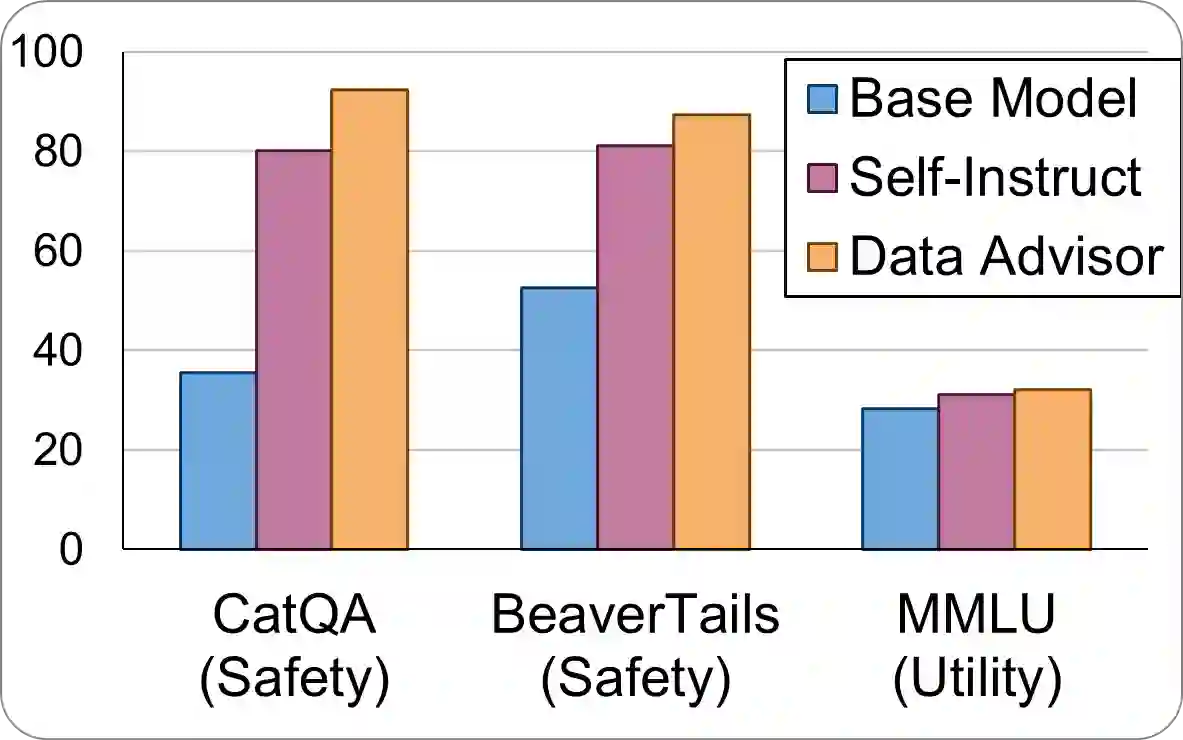
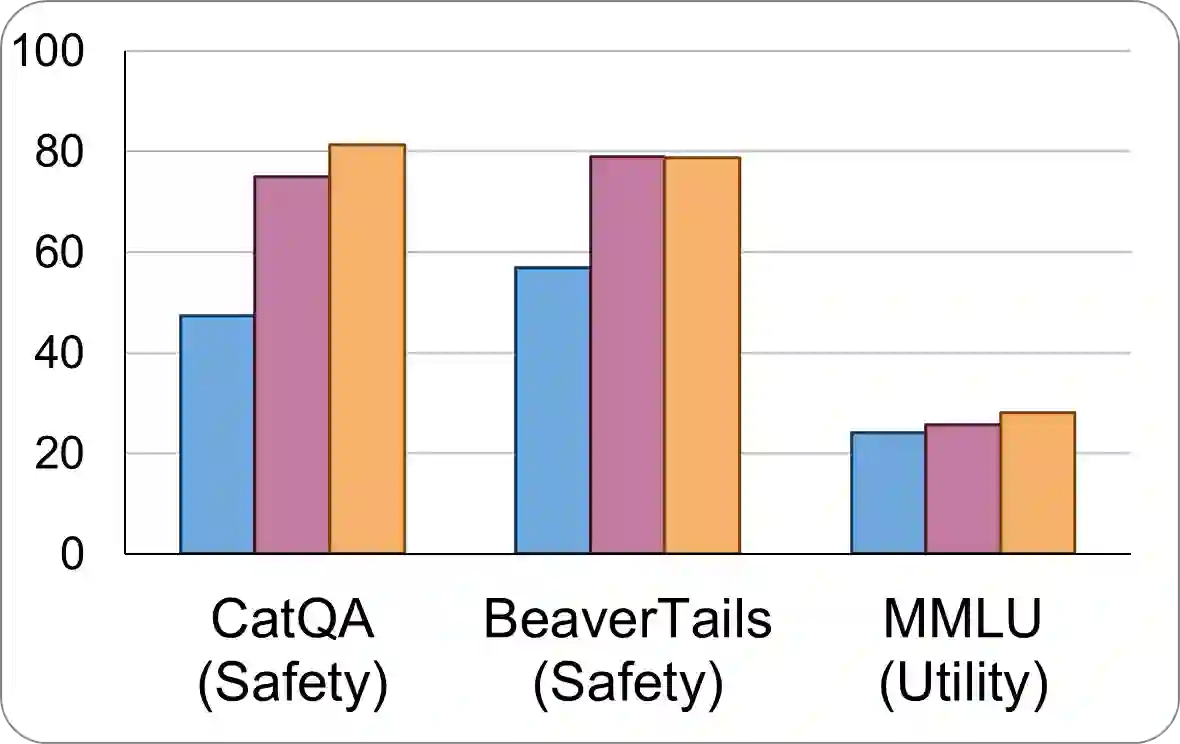
Data is a crucial element in large language model (LLM) alignment. Recent studies have explored using LLMs for efficient data collection. However, LLM-generated data often suffers from quality issues, with underrepresented or absent aspects and low-quality datapoints. To address these problems, we propose Data Advisor, an enhanced LLM-based method for generating data that takes into account the characteristics of the desired dataset. Starting from a set of pre-defined principles in hand, Data Advisor monitors the status of the generated data, identifies weaknesses in the current dataset, and advises the next iteration of data generation accordingly. Data Advisor can be easily integrated into existing data generation methods to enhance data quality and coverage. Experiments on safety alignment of three representative LLMs (i.e., Mistral, Llama2, and Falcon) demonstrate the effectiveness of Data Advisor in enhancing model safety against various fine-grained safety issues without sacrificing model utility.
翻译:数据是大语言模型(LLM)对齐中的关键要素。近期研究探索了利用LLM进行高效数据收集的方法。然而,LLM生成的数据常存在质量问题,表现为代表性不足或缺失的维度以及低质量数据点。为解决这些问题,我们提出数据顾问(Data Advisor),这是一种基于LLM的增强型数据生成方法,能够充分考虑目标数据集的特征。该方法从一组预定义原则出发,持续监控生成数据的动态状态,识别当前数据集的薄弱环节,并据此指导下一轮数据生成。数据顾问可轻松集成到现有数据生成方法中,以提升数据质量与覆盖度。在三个代表性LLM(即Mistral、Llama2和Falcon)的安全对齐实验中,数据顾问有效提升了模型针对各类细粒度安全问题的防御能力,且未损害模型实用性。