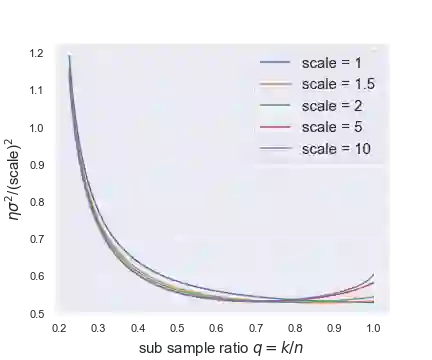
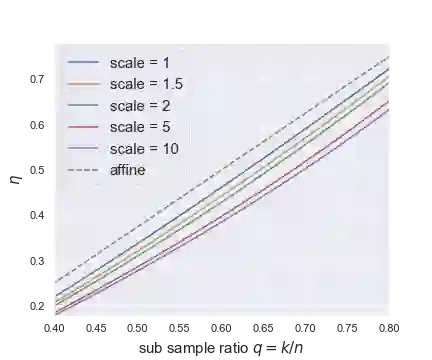
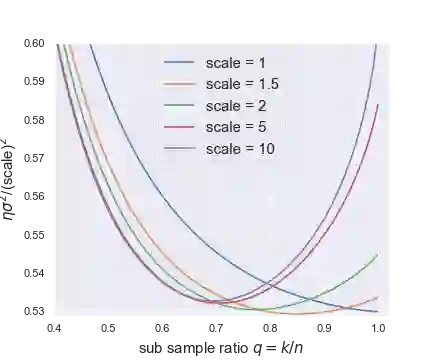
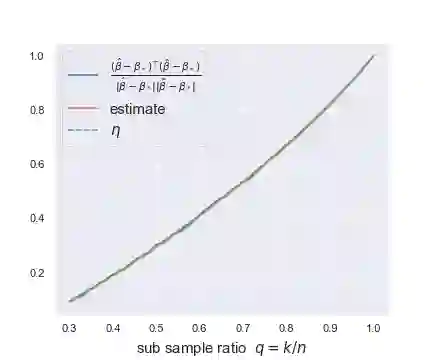
This paper studies the asymptotics of resampling without replacement in the proportional regime where dimension $p$ and sample size $n$ are of the same order. For a given dataset $(X,y)\in \mathbb{R}^{n\times p}\times \mathbb{R}^n$ and fixed subsample ratio $q\in(0,1)$, the practitioner samples independently of $(X,y)$ iid subsets $I_1,...,I_M$ of $\{1,...,n\}$ of size $q n$ and trains estimators $\hat{\beta}(I_1),...,\hat{\beta}(I_M)$ on the corresponding subsets of rows of $(X, y)$. Understanding the performance of the bagged estimate $\bar{\beta} = \frac1M\sum_{m=1}^M \hat{\beta}(I_1),...,\hat{\beta}(I_M)$, for instance its squared error, requires us to understand correlations between two distinct $\hat{\beta}(I_m)$ and $\hat{\beta}(I_{m'})$ trained on different subsets $I_m$ and $I_{m'}$. In robust linear regression and logistic regression, we characterize the limit in probability of the correlation between two estimates trained on different subsets of the data. The limit is characterized as the unique solution of a simple nonlinear equation. We further provide data-driven estimators that are consistent for estimating this limit. These estimators of the limiting correlation allow us to estimate the squared error of the bagged estimate $\bar{\beta}$, and for instance perform parameter tuning to choose the optimal subsample ratio $q$. As a by-product of the proof argument, we obtain the limiting distribution of the bivariate pair $(x_i^T \hat{\beta}(I_m), x_i^T \hat{\beta}(I_{m'}))$ for observations $i\in I_m\cap I_{m'}$, i.e., for observations used to train both estimates.
翻译:本文研究在维度 $p$ 与样本量 $n$ 为同阶量的比例条件下,无放回重抽样的渐近性质。对于给定数据集 $(X,y)\in \mathbb{R}^{n\times p}\times \mathbb{R}^n$ 和固定子样本比例 $q\in(0,1)$,研究者独立于 $(X,y)$ 抽取容量为 $q n$ 的独立同分布子集 $I_1,...,I_M\subset \{1,...,n\}$,并在 $(X, y)$ 对应的行子集上训练估计量 $\hat{\beta}(I_1),...,\hat{\beta}(I_M)$。理解袋装估计量 $\bar{\beta} = \frac1M\sum_{m=1}^M \hat{\beta}(I_1),...,\hat{\beta}(I_M)$ 的性能(例如其均方误差)需要理解基于不同子集 $I_m$ 和 $I_{m'}$ 训练的两个不同估计量 $\hat{\beta}(I_m)$ 与 $\hat{\beta}(I_{m'})$ 之间的相关性。在稳健线性回归与逻辑回归中,我们刻画了基于不同数据子集训练的两个估计量之间相关性的概率极限。该极限被表征为某简单非线性方程的唯一解。我们进一步提供了与该极限估计一致的数据驱动型估计量。这些极限相关性的估计量使我们能够估计袋装估计量 $\bar{\beta}$ 的均方误差,并可执行参数调优以选择最优子样本比例 $q$。作为证明过程的副产品,我们还得到了观测值 $i\in I_m\cap I_{m'}$(即用于训练两个估计量的观测值)的二元对 $(x_i^T \hat{\beta}(I_m), x_i^T \hat{\beta}(I_{m'}))$ 的极限分布。