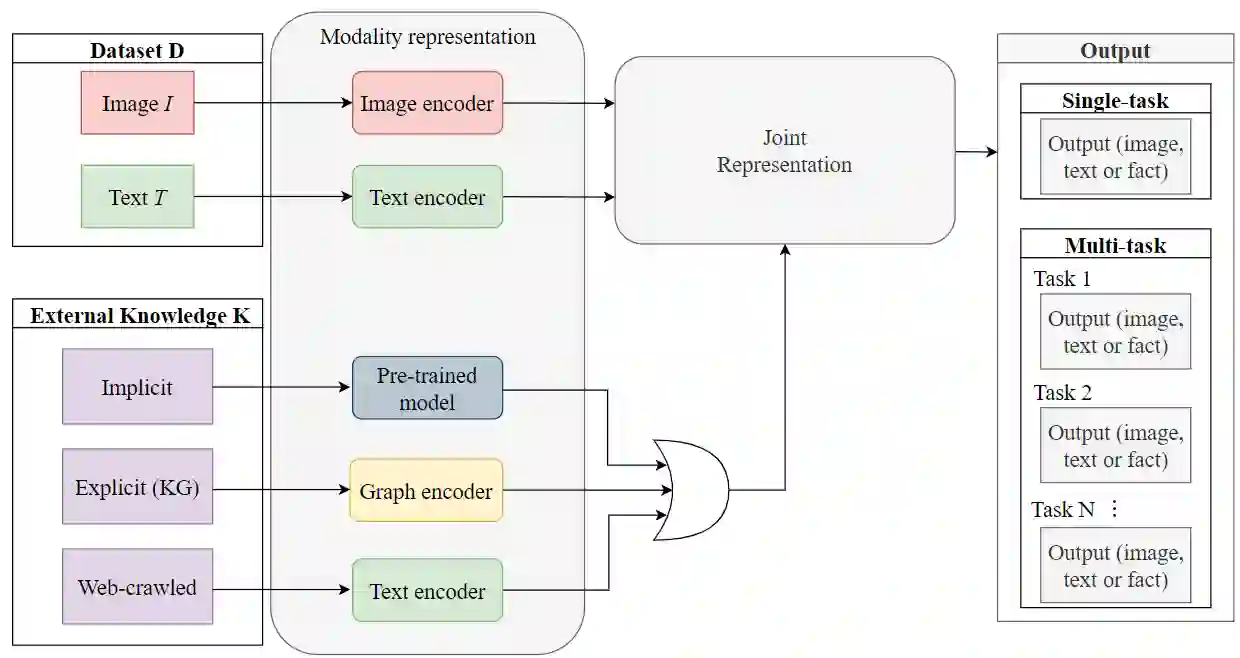
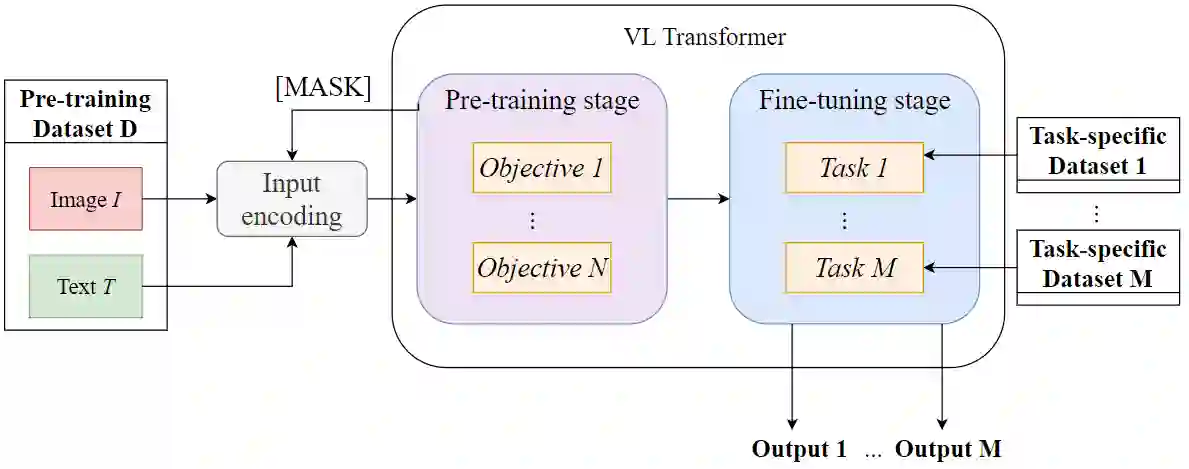
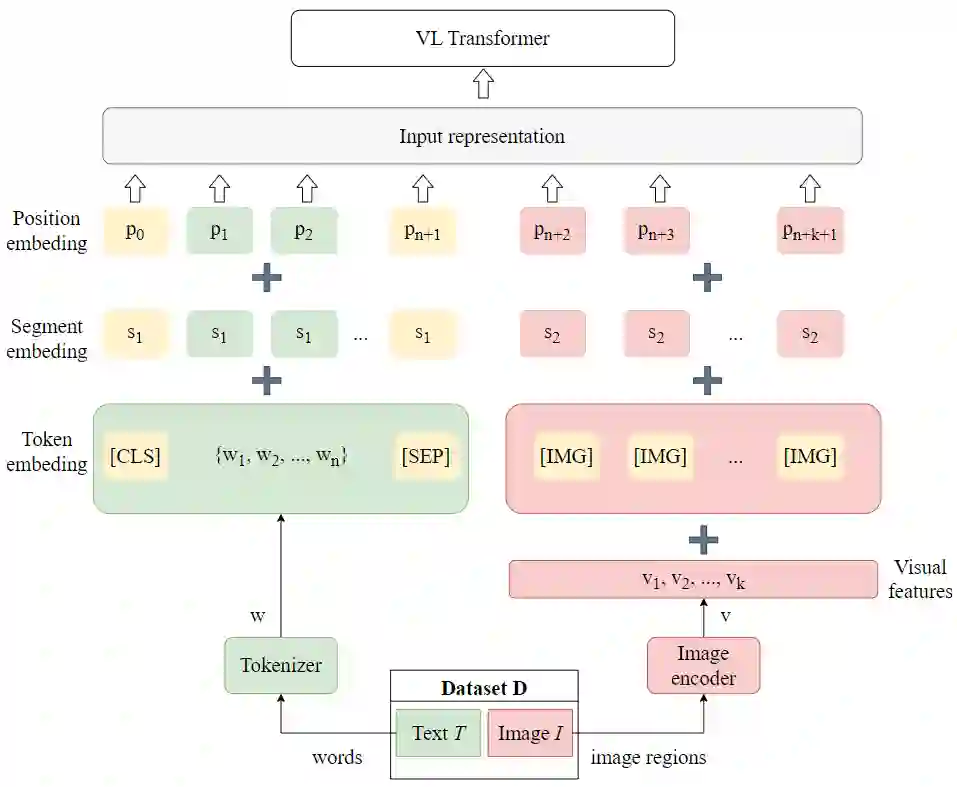
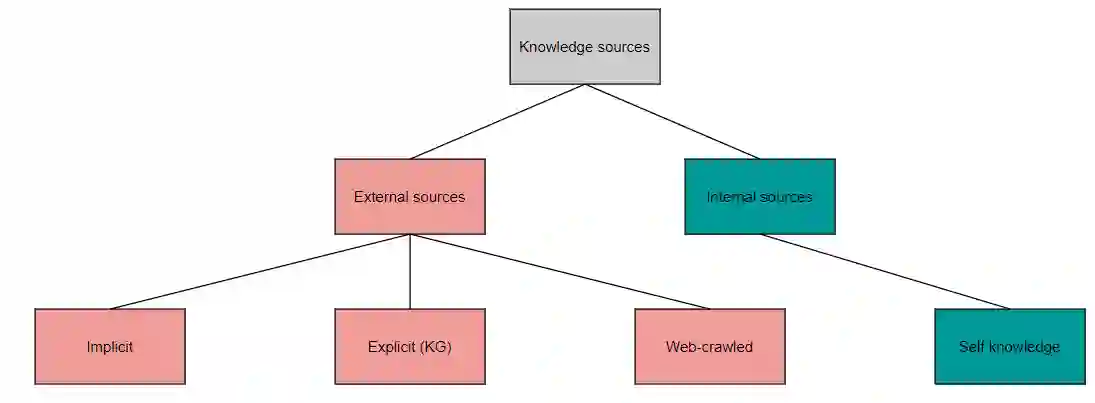
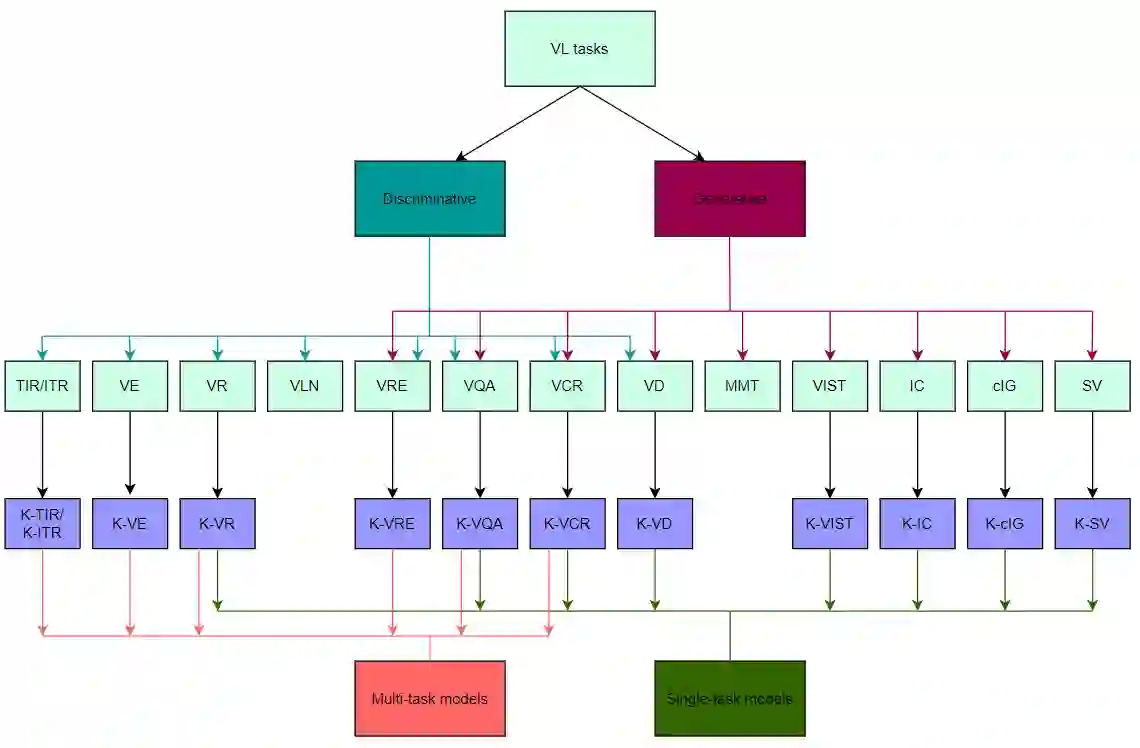
Multimodal learning has been a field of increasing interest, aiming to combine various modalities in a single joint representation. Especially in the area of visiolinguistic (VL) learning multiple models and techniques have been developed, targeting a variety of tasks that involve images and text. VL models have reached unprecedented performances by extending the idea of Transformers, so that both modalities can learn from each other. Massive pre-training procedures enable VL models to acquire a certain level of real-world understanding, although many gaps can be identified: the limited comprehension of commonsense, factual, temporal and other everyday knowledge aspects questions the extendability of VL tasks. Knowledge graphs and other knowledge sources can fill those gaps by explicitly providing missing information, unlocking novel capabilities of VL models. In the same time, knowledge graphs enhance explainability, fairness and validity of decision making, issues of outermost importance for such complex implementations. The current survey aims to unify the fields of VL representation learning and knowledge graphs, and provides a taxonomy and analysis of knowledge-enhanced VL models.
翻译:多模态学习作为一个日益受到关注的领域,旨在将不同模态信息整合到统一的联合表示中。尤其在视觉-语言(VL)学习领域,研究者已开发出多种模型和技术,用于处理涉及图像与文本的各类任务。通过扩展Transformer架构的基本思想,VL模型实现了前所未有的性能突破,使两种模态能够相互学习。大规模预训练流程虽使VL模型获得了一定程度的现实世界理解能力,但仍存在诸多缺陷:对常识性、事实性、时序性及其他日常知识维度的有限理解,限制了VL任务的可扩展性。知识图谱与其他知识源能够通过显式提供缺失信息填补这些空白,从而激发VL模型的新能力。与此同时,知识图谱还能增强这类复杂系统在决策过程中的可解释性、公平性和有效性——这些正是最关键的议题。本综述旨在统一视觉-语言表示学习与知识图谱两大领域,并提出知识增强型VL模型的分类体系与分析框架。