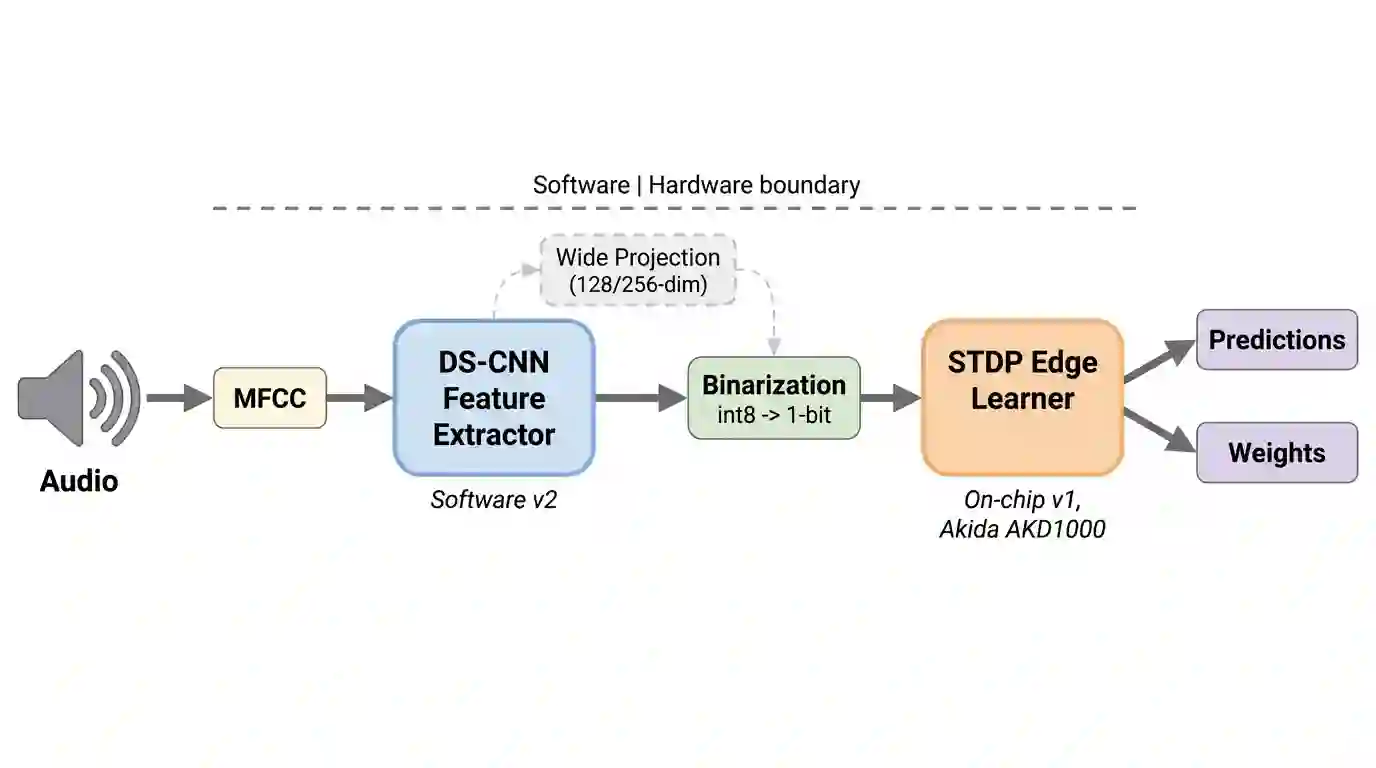
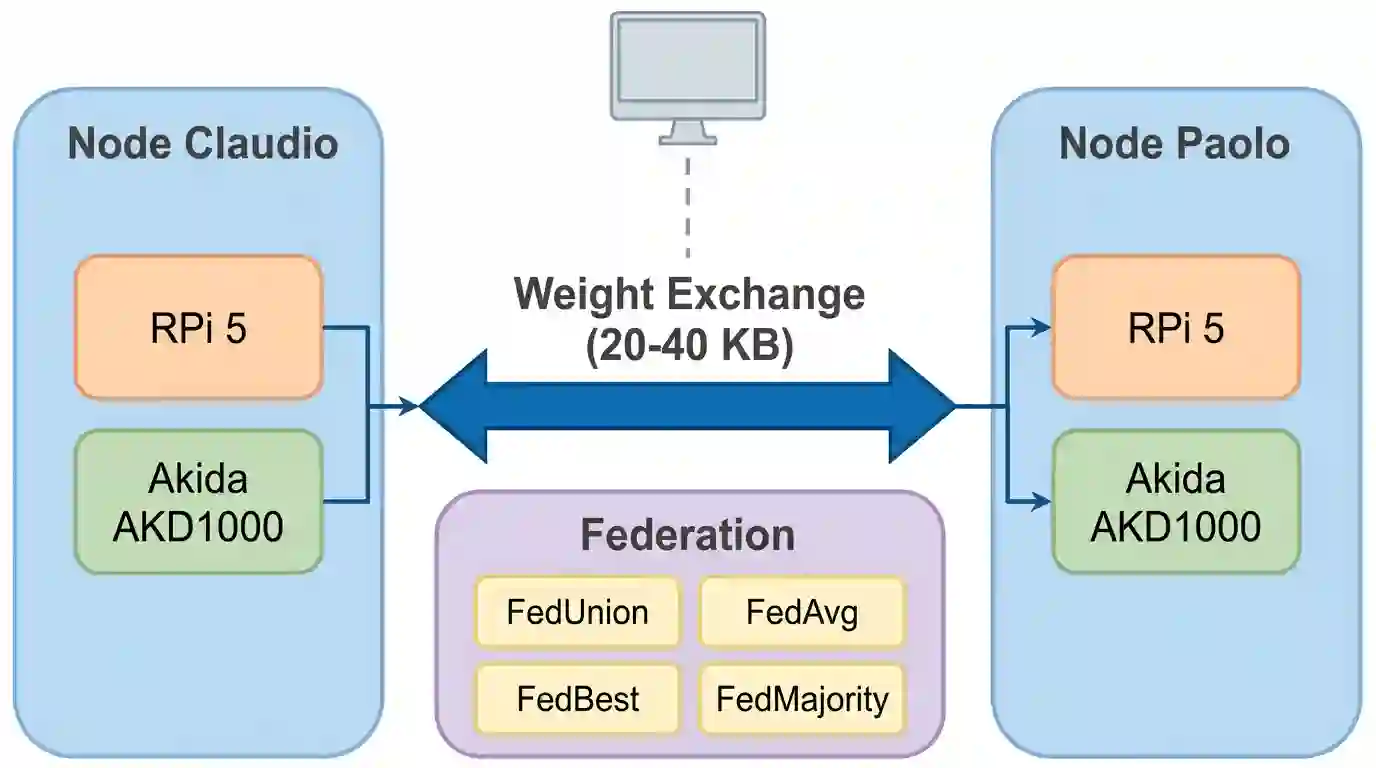
Federated learning on neuromorphic hardware remains unexplored because on-chip spike-timing-dependent plasticity (STDP) produces binary weight updates rather than the floating-point gradients assumed by standard algorithms. We build a two-node federated system with BrainChip Akida AKD1000 processors and run approximately 1,580 experimental trials across seven analysis phases. Of four weight-exchange strategies tested, neuron-level concatenation (FedUnion) consistently preserves accuracy while element-wise weight averaging (FedAvg) destroys it (p = 0.002). Domain-adaptive fine-tuning of the upstream feature extractor accounts for most of the accuracy gains, confirming feature quality as the dominant factor. Scaling feature dimensionality from 64 to 256 yields 77.0% best-strategy federated accuracy (n=30, p < 0.001). Two independent asymmetries (wider features help federation more than individual learning, while binarization hurts federation more) point to a shared prototype complementarity mechanism: cross-node transfer scales with the distinctiveness of neuron prototypes.
翻译:神经形态硬件上的联邦学习仍未被探索,因为片上脉冲时序依赖可塑性(STDP)产生的是二进制权重更新,而非标准算法所假设的浮点梯度。我们构建了一个包含两个BrainChip Akida AKD1000处理器的联邦系统,并在七个分析阶段进行了约1580次实验测试。在四种权重交换策略中,神经元级拼接(FedUnion)始终能保持精度,而逐元素权重平均(FedAvg)则会破坏精度(p = 0.002)。上游特征提取器的领域自适应微调贡献了大部分精度提升,证实了特征质量是主导因素。将特征维度从64扩展到256,可获得77.0%的最佳策略联邦精度(n=30,p < 0.001)。两个独立的不对称现象(更宽的特征对联邦学习的帮助大于个体学习,而二值化对联邦学习的损害更大)指向一个共享的原型互补机制:跨节点迁移的规模与神经元原型独特性成正比。