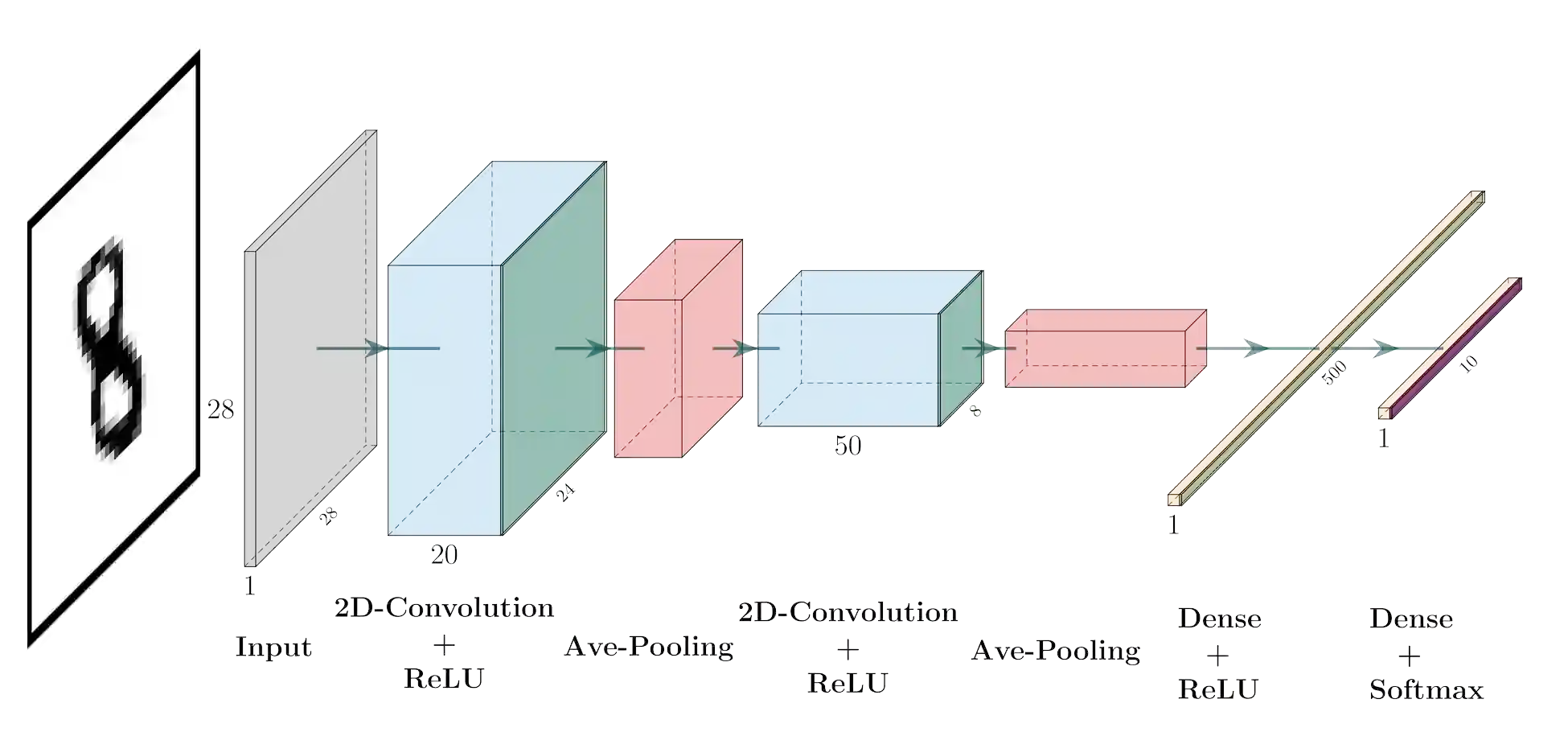
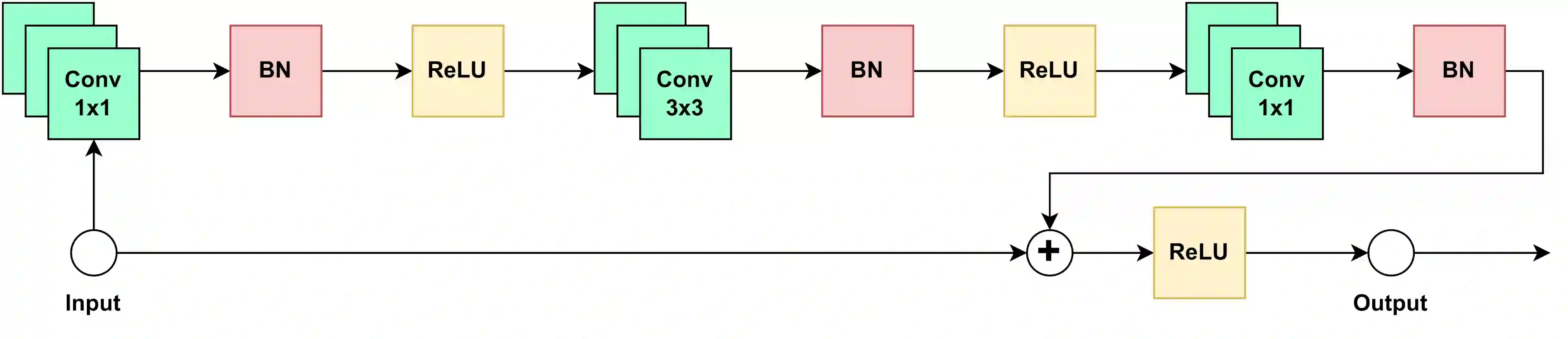
We present a unified representation of the most popular neural network activation functions. Adopting Mittag-Leffler functions of fractional calculus, we propose a flexible and compact functional form that is able to interpolate between various activation functions and mitigate common problems in training neural networks such as vanishing and exploding gradients. The presented gated representation extends the scope of fixed-shape activation functions to their adaptive counterparts whose shape can be learnt from the training data. The derivatives of the proposed functional form can also be expressed in terms of Mittag-Leffler functions making it a suitable candidate for gradient-based backpropagation algorithms. By training multiple neural networks of different complexities on various datasets with different sizes, we demonstrate that adopting a unified gated representation of activation functions offers a promising and affordable alternative to individual built-in implementations of activation functions in conventional machine learning frameworks.
翻译:我们提出了一种最流行的神经网络激活函数的统一表示。采用分数阶微积分中的Mittag-Leffler函数,我们提出了一种灵活且紧凑的函数形式,能够插值多种激活函数,并缓解训练神经网络中的常见问题,如梯度消失和梯度爆炸。所提出的门控表示将固定形状激活函数的范围扩展至自适应形式,其形状可从训练数据中学习得到。该函数形式的导数也可用Mittag-Leffler函数表达,使其适用于基于梯度的反向传播算法。通过在不同规模的多个数据集上训练不同复杂度的神经网络,我们证明采用统一的门控激活函数表示为传统机器学习框架中独立内置的激活函数实现提供了一种有前景且经济实惠的替代方案。