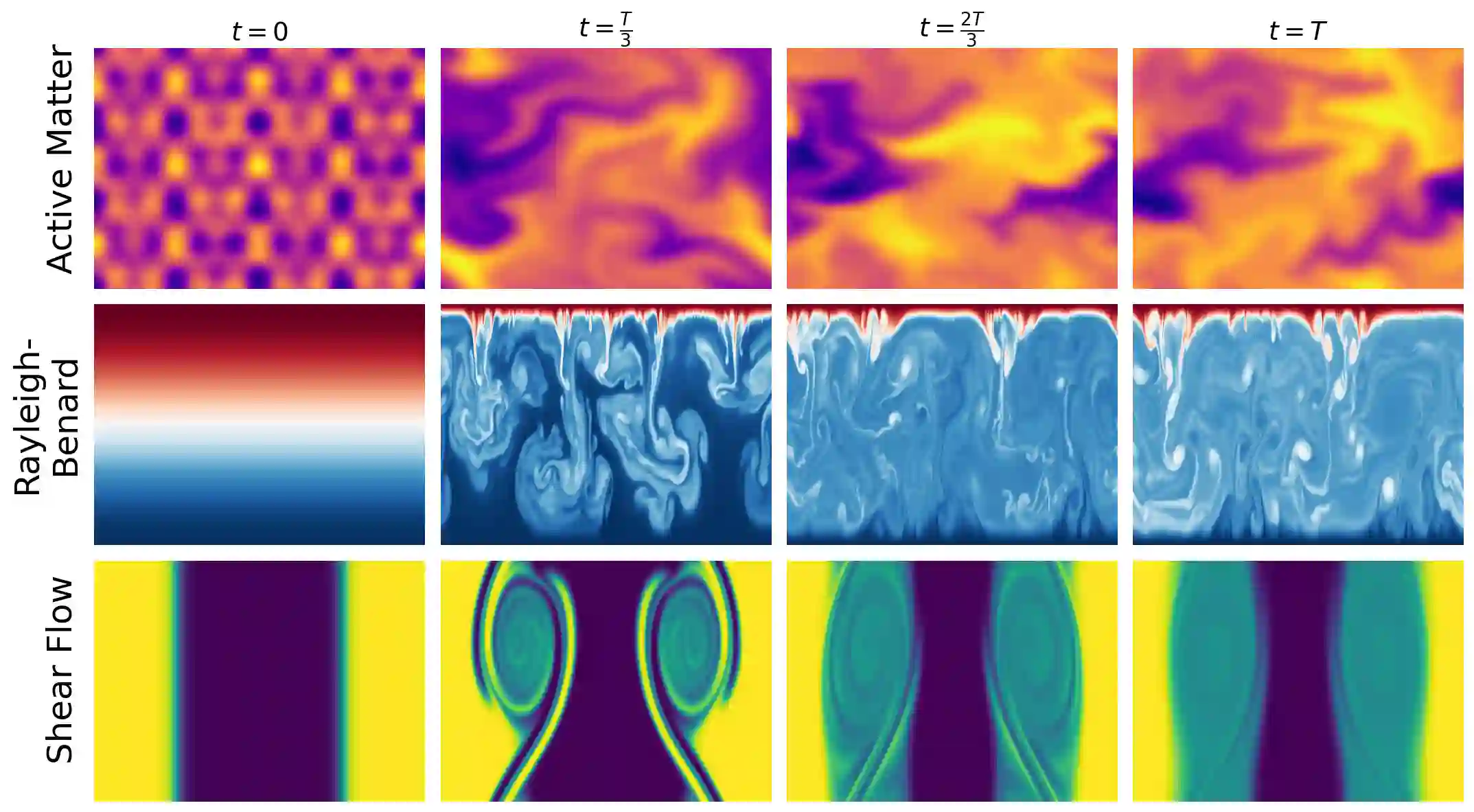
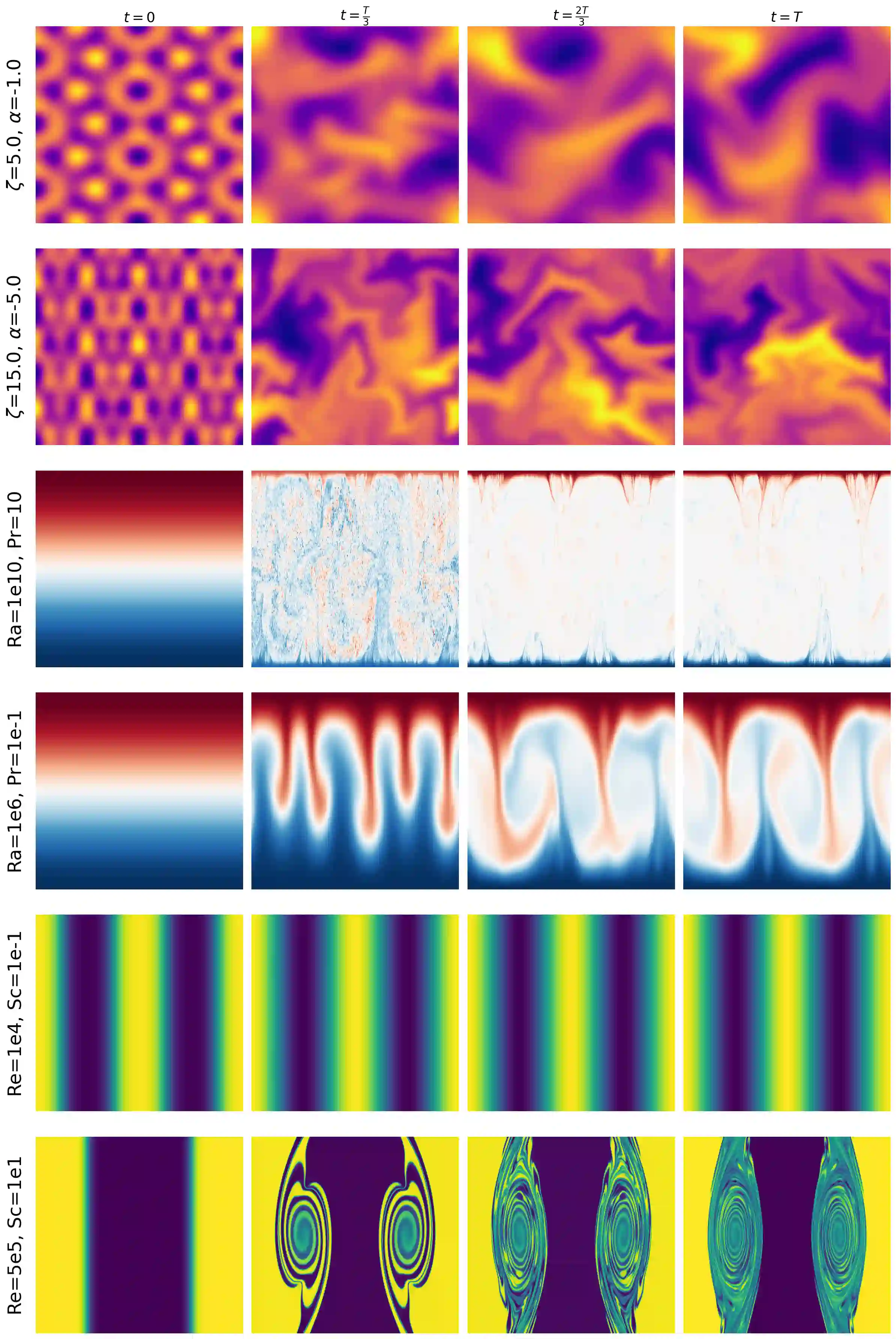
Machine learning approaches to spatiotemporal physical systems have primarily focused on next-frame prediction, with the goal of learning an accurate emulator for the system's evolution in time. However, these emulators are computationally expensive to train and are subject to performance pitfalls, such as compounding errors during autoregressive rollout. In this work, we take a different perspective and look at scientific tasks further downstream of predicting the next frame, such as estimation of a system's governing physical parameters. Accuracy on these tasks offers a uniquely quantifiable glimpse into the physical relevance of the representations of these models. We evaluate the effectiveness of general-purpose self-supervised methods in learning physics-grounded representations that are useful for downstream scientific tasks. Surprisingly, we find that not all methods designed for physical modeling outperform generic self-supervised learning methods on these tasks, and methods that learn in the latent space (e.g., joint embedding predictive architectures, or JEPAs) outperform those optimizing pixel-level prediction objectives. Code is available at https://github.com/helenqu/physical-representation-learning.
翻译:针对时空物理系统的机器学习方法主要集中于下一帧预测,其目标是学习系统时间演化的精确仿真器。然而,这些仿真器的训练计算成本高昂,且存在性能缺陷,例如在自回归推演过程中误差会不断累积。在本研究中,我们采取不同视角,关注预测下一帧之后更下游的科学任务,例如系统主导物理参数的估计。这些任务的准确性为评估模型表征的物理相关性提供了独特的可量化视角。我们评估了通用自监督方法在学习适用于下游科学任务的、基于物理的表征方面的有效性。令人惊讶的是,我们发现并非所有为物理建模设计的方法在这些任务上都优于通用的自监督学习方法,并且在潜在空间中学习的方法(例如联合嵌入预测架构,即JEPAs)优于那些优化像素级预测目标的方法。代码可在 https://github.com/helenqu/physical-representation-learning 获取。